







文章目录
准备阶段
前两天偶然看到 利用 Python 爬取了 13966 条运维招聘信息,我得出了哪些结论?这篇文章,觉得分析得很好,于是也想写一篇关于“数据分析”招聘信息的文章。
我照着作者的思路,开始了我的数据分析探索 biu~
数据获取
要获取数据的网站是前程无忧网
在网站中搜索关键词 “数据分析” ,即可看到所有与数据分析相关的招聘信息
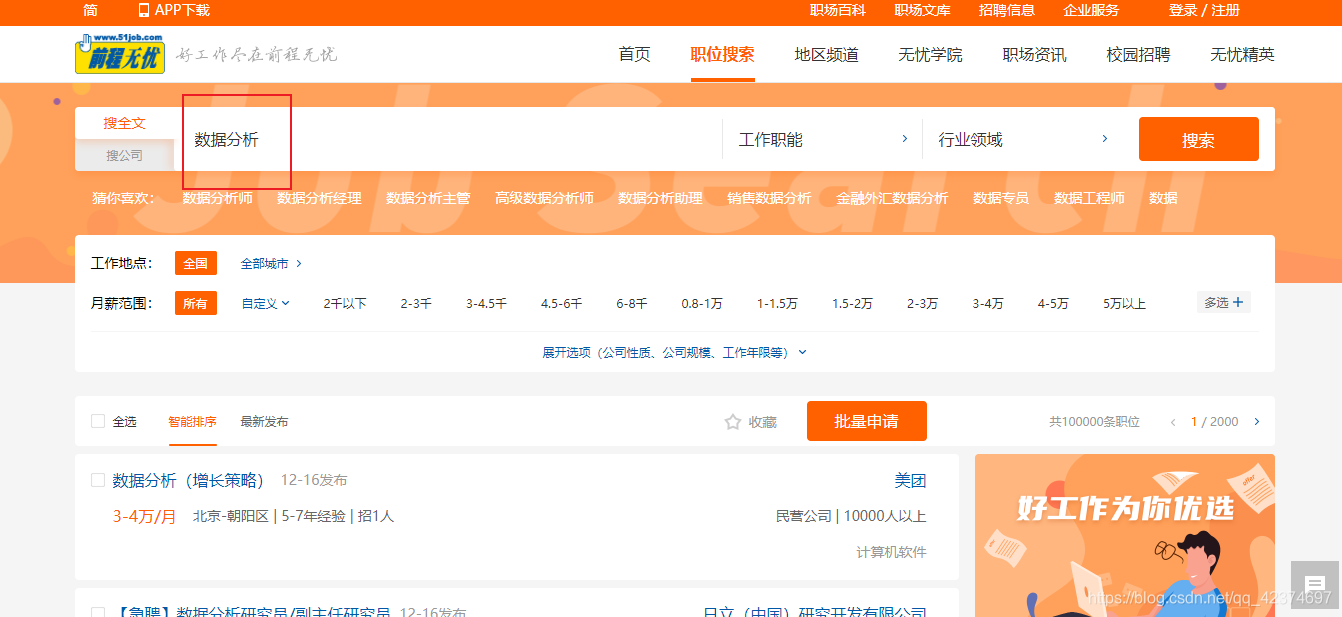
这里显示有 2000 多页,实际上我期望的数据并没有这么多
随机跳转到100页,看到招聘信息如下
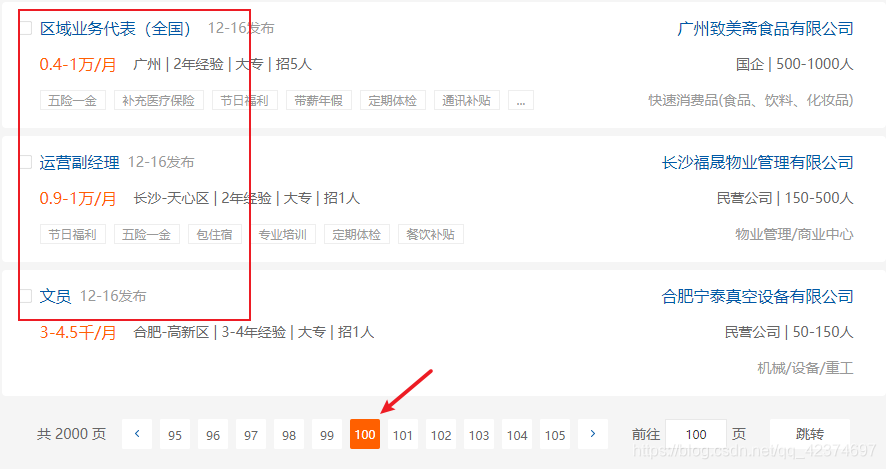
所以本次只爬取前面几十页数据,以确保拿到的是我所需要的数据
接下来准备用以前的爬虫套路,用requests 、 Xpath 等工具开始提取数据,结果发现这个网页返回来的数据与以前的不一样,有点蒙逼了
仔细观察返回的数据(网页源代码),发现职位信息在‘window.__SEARCH_RESULT__ ’之后,‘’</scrip t>‘’之前,所以可以根据这个写出对应的正则表达式来提取数据

'window.__SEARCH_RESULT__ = (.*?)</script>'
用 Json 库进行解析
data = json.loads(
re.findall('window.__SEARCH_RESULT__ = (.*?)</script>', html)[0]
)
results = data['engine_search_result']
这里我将整个大字典提取出来

把它复制粘贴到 Json在线解析网站中,方便查看其结构
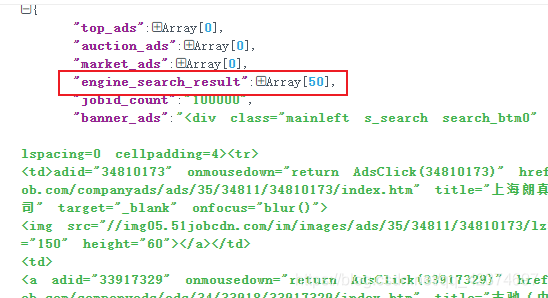
可以看到,每一页有50条招聘信息,每一条信息中包括了工作岗位、公司名称、工作地点等数据,接下来就可以逐一提取了

爬虫部分代码如下:
#接下来进行数据提取
def parse_one_page(results):
for x in range(len(results)):
try:
# 公司名称
company_name = results[x]['company_name']
# 岗位名称
job_name = results[x]['job_name']
# 工作地点
workarea = results[x]['workarea_text'][:2]
# 工资
providesalary = results[x]['providesalary_text']
# 发布日期
issuedate = results[x]['issuedate']
# 经验、学历
attribute = '/'.join(results[x]['attribute_text'])
# 公司类型
companytype = results[x]['companytype_text']
# 公司规模
companysize = results[x]['companysize_text']
# 公司所属行业
companyind = results[x]['companyind_text']
# 公司待遇
jobwelf = results[x]['jobwelf']
# 工作详情
job_href = results[x]['job_href']
#解决乱码问题
rr = requests.get(job_href,headers = headers)
rr.encoding = 'gbk'
con = rr.text
con = etree.HTML(con)
# 岗位详情
aa = con.xpath('//div[@class="bmsg job_msg inbox"]/p/text()')
aa = ''.join([i.strip().replace('\xa0','') for i in aa])
# 写入
sheet.append([company_name, job_name, workarea,providesalary,issuedate,attribute,companytype,companysize,companyind,jobwelf,aa])
except Exception:
pass
def main(offset):
# 构造主函数,初始化各个模块,传入入口URL
url = base_url.format(offset)
data = json.loads(
re.findall('window.__SEARCH_RESULT__ = (.*?)</script>', get_one_page(url))[0])
results = data['engine_search_result']
# 为了反爬,设置睡眠时间
time.sleep(1)
parse_one_page(results)
需要完整代码的朋友请留言!

爬取结果如下

数据清洗
数据清洗部分是参考开头提到的文章中的代码
import pandas as pd
import numpy as np
import re
import jieba
df = pd.read_excel('info.xlsx')
df.head()
# 去重之前的记录数
print("去重之前的记录数",df.shape)
# 记录去重
df.drop_duplicates(subset=["公司名称","岗位名称","工作地点"],inplace=True)
# 去重之后的记录数
print("去重之后的记录数",df.shape)
去重之前的记录数 (2000, 10)
去重之后的记录数 (1988, 10)
对工资列进行处理
df["工资"].str[-1].value_counts()
df["工资"].str[-3].value_counts()
index1 = df["工资"].str[-1].isin(["年","月"])
index2 = df["工资"].str[-3].isin(["万","千"])
df = df[index1 & index2]
df["工资"].str[-3:].value_counts()
def get_money_max_min(x):
try:
if x[-3] == "万":
z = [float(i)*10000 for i in re.findall("[0-9]+\.?[0-9]*",x)]
elif x[-3] == "千":
z = [float(i) * 1000 for i in re.findall("[0-9]+\.?[0-9]*", x)]
if x[-1] == "年":
z = [i/12 for i in z]
return z
except:
return x
salary = df["工资"].apply(get_money_max_min)
df["最低工资"] = salary.str[0]
df["最高工资"] = salary.str[1]
df["工资水平"] = df[["最低工资","最高工资"]].mean(axis=1)
这里用平均值作为工资水平

对经验与学历字段的处理
df["学历"] = df["经验、学历"].apply(lambda x:re.findall("本科|大专|应届生|在校生|硕士|博士",x))
df["经验"] = df["经验、学历"].apply(lambda x:re.findall("无需经验|1年经验|2年经验|3-4年经验|5-7年经验",x))
df["招人数"] = df["经验、学历"].apply(lambda x:x[x.rfind('/')+1:])
def func(x):
if len(x) == 0:
return np.nan
elif len(x) == 1 or len(x) == 2:
return x[0]
else:
return x[2]
df["学历"] = df["学历"].apply(func)
df["经验"] = df["经验"].apply(func)

对公司规模字段的处理
def func(x):
if x == '少于50人':
return "<50"
elif x == '50-150人':
return "50-150"
elif x == '150-500人':
return '150-500'
elif x == '500-1000人':
return '500-1000'
elif x == '1000-5000人':
return '1000-5000'
elif x == '5000-10000人':
return '5000-10000'
elif x == '10000人以上':
return ">10000"
else:
return np.nan
df["公司规模"] = df["公司规模"].apply(func)
行业字段的处理
df["公司所属行业"] = df["公司所属行业"].apply(lambda x:re.sub(",","/",x))# 将 , 替换为 /
df["公司所属行业"] = df["公司所属行业"].apply(lambda x:x.split("/")[0])
df["公司所属行业"].value_counts()
筛选出需要作图的数据
feature = ["公司名称","岗位名称","工作地点","工资水平","发布日期","公司规模","公司类型","公司所属行业","招人数","学历",'经验']
final_df = df[feature]
final_df.to_excel(r"可视化数据.xlsx",encoding="gbk",index=None)

数据可视化
基本的数据处理完毕后,就可以开始制图啦
首先,我先用前两天编制的程序,统计数据集每一列中不同值出现的次数
import pandas as pd
import os
os.chdir(r'C:\Users\Administrator\Desktop')
df = pd.read_excel('可视化数据.xlsx')
def fun(df):
dic = {}
for i in df.columns:
dic[i] = df[i].value_counts()
return dic
dd = fun(df)
# 写入excel
import xlwt
f = xlwt.Workbook() #创建工作薄
sheet1 = f.add_sheet(u'sheet1',cell_overwrite_ok=True) #创建sheet
pattern = xlwt.Pattern()
pattern.pattern = xlwt.Pattern.SOLID_PATTERN
pattern.pattern_fore_colour = 5
style = xlwt.XFStyle()
style.pattern = pattern
al = xlwt.Alignment()
al.horz = 0x02 # 设置水平居中
al.vert = 0x01 # 设置垂直居中
style.alignment = al
# 获取字典的键
list_ = [k for k in dd]
k=0
l=0
for s in range(len(dd)):
l=k+1
# 写入第一行
sheet1.write_merge(0, 1, k, l,list_[s] , style)
# 写入内容
j = 2
for v,h in zip(dd[list_[s]],dd[list_[s]].index):
sheet1.write(j,k,h) #循环写入 竖着写
sheet1.write(j,l,v) #循环写入 竖着写
j=j+1
k=k+3
f.save('统计数据.xls')#保存文件
这些数据可以方便我在不同的工具中进行制图


有了这些数据就可以开始制图了,当然要说明的是,这里的分析非常浅显,还有很多不足,毕竟我还没有真正的接触实际的数据分析工作 T-T
(1)岗位名称
在所有爬取的数据中,数据分析师岗位的招聘信息最多,超过其余15个岗位的总和,当然,我认为这里列出来的岗位不严格的来说都算是数据分析师岗位;其次是数据分析专员、高级数据分析师、数据分析工程师、数据分析助理等。
除此之外,还出现与行业联系的岗位,比如销售数据分析、电商数据分析、临床数据分析、财务数据分析等等。

(2)工作地点
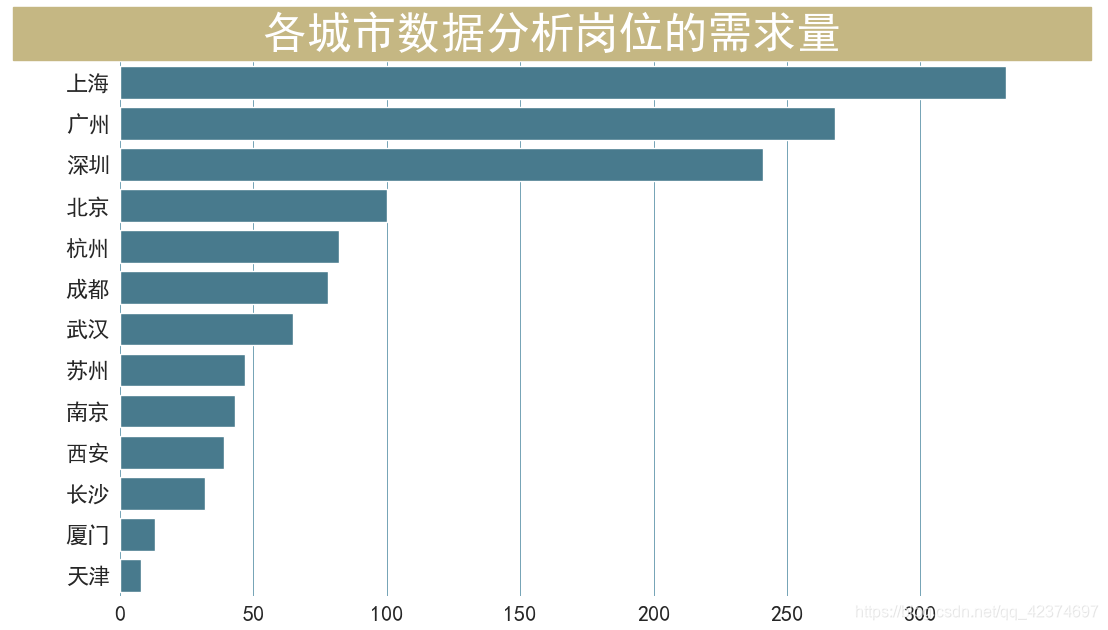
在工作地点的分布中,在广东省工作的岗位最多,远远超过其他城市,这其中广州和深圳的招聘信息较多;其次是上海、江苏、浙江。
对于在重庆工作的岗位并不多,处于中下水平,看来我以后去 “打工” ,要想机会多多得跑远一点了
import pandas as pd
import os
os.chdir(r'C:\Users\Administrator\Desktop')
df = pd.read_excel("可视化数据.xlsx")
df.head()
df1 = df[df["工作地点"] != "异地"]
df1.head()
area_data = {
'北京': ['北京市','朝阳区', '海淀区', '通州区', '房山区', '丰台区', '昌平区', '大兴区', '顺义区', '西城区', '延庆县', '石景山区', '宣武区', '怀柔区', '崇文区', '密云县',
'东城区', '门头沟区', '平谷区'],
'广东':['广东省', '东莞市', '广州市', '中山市', '深圳市', '惠州市', '江门市', '珠海市', '汕头市', '佛山市', '湛江市', '河源市', '肇庆市','潮州市', '清远市', '韶关市', '揭阳市', '阳江市', '云浮市', '茂名市', '梅州市', '汕尾市'],
'山东':['山东省', '济南市', '青岛市', '临沂市', '济宁市', '菏泽市', '烟台市','泰安市', '淄博市', '潍坊市', '日照市', '威海市', '滨州市', '东营市', '聊城市', '德州市', '莱芜市', '枣庄市'],
'江苏':['江苏省', '苏州市', '徐州市', '盐城市', '无锡市','南京市', '南通市', '连云港市', '常州市', '扬州市', '镇江市', '淮安市', '泰州市', '宿迁市', '昆山市', '常熟市'],
'河南':['河南省', '郑州市', '南阳市', '新乡市', '安阳市', '洛阳市', '信阳市','平顶山市', '周口市', '商丘市', '开封市', '焦作市', '驻马店市', '濮阳市', '三门峡市', '漯河市', '许昌市', '鹤壁市', '济源市'],
'上海':['上海市', '松江区', '宝山区', '金山区','嘉定区', '南汇区', '青浦区', '浦东新区', '奉贤区', '闵行区', '徐汇区', '静安区', '黄浦区', '普陀区', '杨浦区', '虹口区', '闸北区', '长宁区', '崇明县', '卢湾区'],
'河北':[ '河北省', '石家庄市', '唐山市', '保定市', '邯郸市', '邢台市', '河北区', '沧州市', '秦皇岛市', '张家口市', '衡水市', '廊坊市', '承德市'],
'浙江':['浙江省', '温州市', '宁波市','杭州市', '台州市', '嘉兴市', '金华市', '湖州市', '绍兴市', '舟山市', '丽水市', '衢州市', '义务市'],
'陕西':['陕西省', '西安市', '咸阳市', '宝鸡市', '汉中市', '渭南市','安康市', '榆林市', '商洛市', '延安市', '铜川市'],
'湖南':[ '湖南省', '长沙市', '邵阳市', '常德市', '衡阳市', '株洲市', '湘潭市', '永州市', '岳阳市', '怀化市', '郴州市','娄底市', '益阳市', '张家界市', '湘西州'],
'重庆':[ '重庆市', '江北区', '渝北区', '沙坪坝区', '九龙坡区', '万州区', '永川市', '南岸区', '酉阳县', '北碚区', '涪陵区', '秀山县', '巴南区', '渝中区', '石柱县', '忠县', '合川市', '大渡口区', '开县', '长寿区', '荣昌县', '云阳县', '梁平县', '潼南县', '江津市', '彭水县', '璧山县', '綦江县',
'大足县', '黔江区', '巫溪县', '巫山县', '垫江县', '丰都县', '武隆县', '万盛区', '铜梁县', '南川区', '奉节县', '双桥区', '城口县'],
'福建':['福建省', '漳州市', '泉州市','厦门市', '福州市', '莆田市', '宁德市', '三明市', '南平市', '龙岩市'],
'天津':['天津市', '和平区', '北辰区', '河北区', '河西区', '西青区', '津南区', '东丽区', '武清区','宝坻区', '红桥区', '大港区', '汉沽区', '静海县', '宁河县', '塘沽区', '蓟县', '南开区', '河东区'],
'云南':[ '云南省', '昆明市', '红河州', '大理州', '文山州', '德宏州', '曲靖市', '昭通市', '楚雄州', '保山市', '玉溪市', '丽江地区', '临沧地区', '思茅地区', '西双版纳州', '怒江州', '迪庆州'],
'四川':['四川省', '成都市', '绵阳市', '广元市','达州市', '南充市', '德阳市', '广安市', '阿坝州', '巴中市', '遂宁市', '内江市', '凉山州', '攀枝花市', '乐山市', '自贡市', '泸州市', '雅安市', '宜宾市', '资阳市','眉山市', '甘孜州'],
'广西':['广西壮族自治区', '贵港市', '玉林市', '北海市', '南宁市', '柳州市', '桂林市', '梧州市', '钦州市', '来宾市', '河池市', '百色市', '贺州市', '崇左市', '防城港市'],
'安徽':['安徽省', '芜湖市', '合肥市', '六安市', '宿州市', '阜阳市','安庆市', '马鞍山市', '蚌埠市', '淮北市', '淮南市', '宣城市', '黄山市', '铜陵市', '亳州市','池州市', '巢湖市', '滁州市'],
'海南':['海南省', '三亚市', '海口市', '琼海市', '文昌市', '东方市', '昌江县', '陵水县', '乐东县', '五指山市', '保亭县', '澄迈县', '万宁市','儋州市', '临高县', '白沙县', '定安县', '琼中县', '屯昌县'],
'江西':['江西省', '南昌市', '赣州市', '上饶市', '吉安市', '九江市', '新余市', '抚州市', '宜春市', '景德镇市', '萍乡市', '鹰潭市'],
'湖北':['湖北省', '武汉市', '宜昌市', '襄樊市', '荆州市', '恩施州', '孝感市', '黄冈市', '十堰市', '咸宁市', '黄石市', '仙桃市', '随州市', '天门市', '荆门市', '潜江市', '鄂州市', '神农架林区'],
'山西':['山西省', '太原市', '大同市', '运城市', '长治市', '晋城市', '忻州市', '临汾市', '吕梁市', '晋中市', '阳泉市', '朔州市'],
'辽宁':['辽宁省', '大连市', '沈阳市', '丹东市', '辽阳市', '葫芦岛市', '锦州市', '朝阳市', '营口市', '鞍山市', '抚顺市', '阜新市', '本溪市', '盘锦市', '铁岭市'],
'台湾':['台湾省','台北市', '高雄市', '台中市', '新竹市', '基隆市', '台南市', '嘉义市'],
'黑龙江':['黑龙江', '齐齐哈尔市', '哈尔滨市', '大庆市', '佳木斯市', '双鸭山市', '牡丹江市', '鸡西市','黑河市', '绥化市', '鹤岗市', '伊春市', '大兴安岭地区', '七台河市'],
'内蒙古':['内蒙古自治区', '赤峰市', '包头市', '通辽市', '呼和浩特市', '乌海市', '鄂尔多斯市', '呼伦贝尔市','兴安盟', '巴彦淖尔盟', '乌兰察布盟', '锡林郭勒盟', '阿拉善盟'],
'香港':["香港","香港特别行政区"],
'澳门':['澳门','澳门特别行政区'],
'贵州':['贵州省', '贵阳市', '黔东南州', '黔南州', '遵义市', '黔西南州', '毕节地区', '铜仁地区','安顺市', '六盘水市'],
'甘肃':['甘肃省', '兰州市', '天水市', '庆阳市', '武威市', '酒泉市', '张掖市', '陇南地区', '白银市', '定西地区', '平凉市', '嘉峪关市', '临夏回族自治州','金昌市', '甘南州'],
'青海':['青海省', '西宁市', '海西州', '海东地区', '海北州', '果洛州', '玉树州', '黄南藏族自治州'],
'新疆':['新疆','新疆维吾尔自治区', '乌鲁木齐市', '伊犁州', '昌吉州','石河子市', '哈密地区', '阿克苏地区', '巴音郭楞州', '喀什地区', '塔城地区', '克拉玛依市', '和田地区', '阿勒泰州', '吐鲁番地区', '阿拉尔市', '博尔塔拉州', '五家渠市',
'克孜勒苏州', '图木舒克市'],
'西藏':['西藏区', '拉萨市', '山南地区', '林芝地区', '日喀则地区', '阿里地区', '昌都地区', '那曲地区'],
'吉林':['吉林省', '吉林市', '长春市', '白山市', '白城市','延边州', '松原市', '辽源市', '通化市', '四平市'],
'宁夏':['宁夏回族自治区', '银川市', '吴忠市', '中卫市', '石嘴山市', '固原市']
}
def func(x):
for k,v in area_data.items():
for i in v:
if x in i:
return k
df1["省份"] = df1["工作地点"].apply(func)
Province = df1["省份"].value_counts().index.tolist()
data = df1["省份"].value_counts().values.tolist()
city_num = pd.DataFrame({'Province':Province,'data':data})
# 导入所需的库
import pandas as pd
import numpy as np
from plotnine import *
from pylab import mpl
import matplotlib.pyplot as plt
import matplotlib.patches as mpathes
from matplotlib.collections import PatchCollection
from matplotlib import cm, colors
# 正常显示中文标签
mpl.rcParams['font.sans-serif'] = ['SimHei']
# 正常显示负号
mpl.rcParams['axes.unicode_minus'] = False
# 定义颜色,主色:蓝色,辅助色:灰色,互补色:橙色
c = {'蓝色':'#00589F', '深蓝色':'#003867', '浅蓝色':'#5D9BCF',
'灰色':'#999999', '深灰色':'#666666', '浅灰色':'#CCCCCC',
'橙色':'#F68F00', '深橙色':'#A05D00', '浅橙色':'#FBC171'}
# 从 Excel 文件中读取数据
df = pd.read_excel('中国省份坐标.xlsx')
# 计算每个省份的中心坐标
df_center = df.groupby('Province').mean()
# 合并省份坐标和数据
dfxy = pd.merge(df_center, city_num, on='Province', how ='left')
dfxy.fillna(0,inplace=True)
# 定义颜色数值
color_value = np.array(dfxy.data)
# 使用「面向对象」的方法画图,定义图片的大小
fig, ax = plt.subplots(figsize=(16, 9))
# 设置背景颜色
fig.set_facecolor('w')
ax.set_facecolor('w')
# 设置标题
ax.set_title('\n岗位招聘地点的区域分布', loc='center', fontsize=26)
# 循环设置每个省份
patches = []
for Province in np.unique(df['Province']):
# 筛选每个省份的数据
dfp = df[df['Province'] == Province]
# 多边形的每个位置
rect = mpathes.Polygon([(x, y) for x, y in zip(dfp['x'], dfp['y'])])
patches.append(rect)
# 多边形内部显示省份名称和数据
ax.text(df_center.loc[Province].x, df_center.loc[Province].y,
'\n'+Province+'\n'+'%d' % dfxy[dfxy['Province'] == Province].data.values[0],
fontsize=15, va='center', ha='center', color=c['深灰色'])
# 填充形状和颜色
collection = PatchCollection(patches, alpha=0.5, cmap=plt.cm.Oranges, ec=c['浅灰色'], fc='w', lw=1)
collection.set_array(color_value)
ax.add_collection(collection)
# 隐藏边框
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['left'].set_visible(False)
ax.spines['bottom'].set_visible(False)
# 隐藏 X、Y 轴
ax.xaxis.set_visible(False)
ax.yaxis.set_visible(False)
# 避免变形
plt.axis('equal')
plt.show()

取其中前四个数据进行制图

补充:
import pandas as pd
import numpy as np
import seaborn as sns
from pyecharts.charts import Pie
from pyecharts import options as opts
import matplotlib.pyplot as plt
sns.set_style('white',{'font.sans-serif':['simhei','Arial']})
pd.set_option("display.max_column", None)
pd.set_option("display.max_row",None)
import os
os.chdir(r'C:\Users\Administrator\Desktop')
df = pd.read_excel('可视化数据.xlsx')
city_list = ["北京","上海","深圳","广州","杭州","成都","南京","武汉","西安","厦门","长沙","苏州","天津"]
df = df[df['工作地点'].isin(city_list)]
fig, ax = plt.subplots(figsize=(12,8))
sns.countplot(y="工作地点",order= df["工作地点"].value_counts().index,data=df,color='#3c7f99')
plt.box(False)
fig.text(x=0.04, y=0.90, s=' 各城市数据分析岗位的需求量 ',
fontsize=32, weight='bold', color='white', backgroundcolor='#c5b783')
plt.tick_params(axis='both', which='major', labelsize=16)
ax.xaxis.grid(which='both', linewidth=0.5, color='#3c7f99')
plt.xlabel('')
plt.ylabel('')
(3)公司所属行业
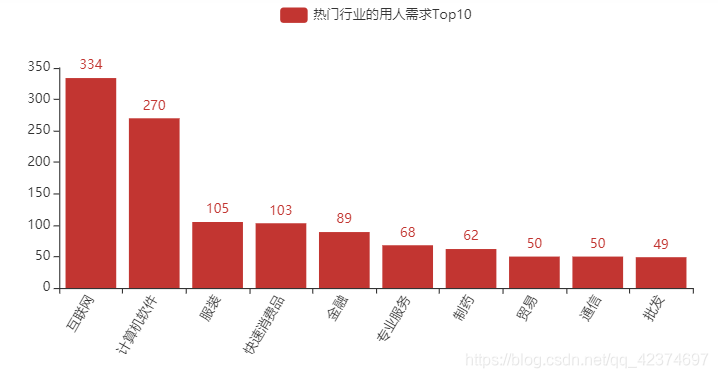
在爬取的所有招聘信息中,公司所属行业最多的是互联网行业,其次是计算机软件、服装、快速消费品…
额 ,看来各行各业都需要 “数据分析岗位” 啊

使用R语言制图

(4)工作经验要求
应聘 “数据分析” 相关岗位,公司要求的工作经验最多的是 1年的经验,其次是 3-4 年的经验…
对于我这种无经验的,是不是该去找找 “无需经验” 岗位 T_T

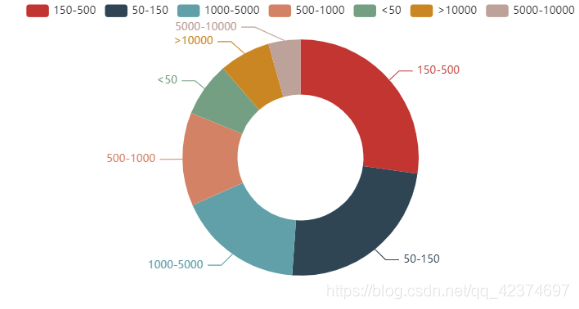
(5)公司规模情况
公司的规模最多的是 150 - 500 人,其次是 50-150人。

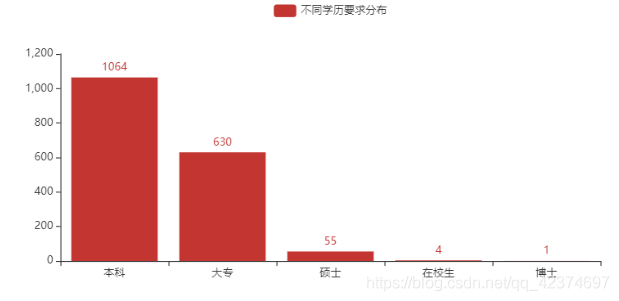
(7)学历要求
对于学历,大多数公司的最低要求是本科,其次是大专 。这里收集到的数据只有极少部分公司要求学历是硕士或者博士。
# 导入所需的库
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.image as image
# 正常显示中文标签
mpl.rcParams['font.sans-serif'] = ['SimHei']
# 自动适应布局
mpl.rcParams.update({'figure.autolayout': True})
# 正常显示负号
mpl.rcParams['axes.unicode_minus'] = False
# 定义颜色,主色:蓝色,辅助色:灰色,互补色:橙色
c = {'蓝色':'#00589F', '深蓝色':'#003867', '浅蓝色':'#5D9BCF',
'灰色':'#999999', '深灰色':'#666666', '浅灰色':'#CCCCCC',
'橙色':'#F68F00', '深橙色':'#A05D00', '浅橙色':'#FBC171'}
# 定义数据
df = pd.DataFrame({'学历要求':['本科', '大专', '硕士','在校生', '博士'], '数量':[1064, 630, 55, 4,1]})
'''
美国确诊人数 所花的天数
0 第一个百万 98
1 第二个百万 42
2 第三个百万 30
3 第四个百万 16
'''
# 画图用的数据定义
x = df['学历要求']
y = df['数量']
# 使用「面向对象」的方法画图
fig, ax = plt.subplots(figsize=(8, 6))
# 设置标题
ax.set_title('\n 不同学历要求分布\n', fontsize=28, loc='center', color=c['深灰色'])
# 画柱形图
ax.bar(x, y, width=0.6, color=c['蓝色'])
# 用箭头强调对比的关系
ax.annotate('', xy=(4, 200), xytext=(0.5, 1064), arrowprops=dict(color=c['橙色'], connectionstyle="arc3,rad=0.25"))
# 设置数据标签
for a, b in zip(x, y):
ax.text(a, b, '%.0f' % b, ha='center', va= 'bottom', fontsize=22, color=c['深灰色'])
# 隐藏边框
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.spines['left'].set_visible(False)
# 隐藏 X 轴的刻度线
ax.tick_params(axis='x', which='major', length=0)
# 隐藏 Y 轴刻度
ax.set_yticks([])
# 设置坐标标签字体大小和颜色
ax.tick_params(labelsize=20, colors=c['深灰色'])
plt.show()

(8)公司类型
这里获得的数据显示大部分公司都是民营企业,数量远超其他公司类型。

(9)招收人数
在 “数据分析”岗位招聘信息中,大多数公司只招收1人,其次是招两人,看来竞争很激烈啊。

(10)岗位职责和任职要求数据词云分析
因每个招聘职位下的描述都不相同,网页结构也不同,所以我这里将岗位职责与任职要求这两个文本数据混合做词云图,但是最好是分开分析。
# 词云图
import jieba
import pandas as pd
import stylecloud
import matplotlib.pyplot as plt
import numpy as np
df = pd.read_excel('C:\\Users\\Administrator\\Desktop\\info.xlsx')
def get_cut_words(content_series):
# 读入停用词表
stop_words = []
with open(r"C:\\Users\\Administrator\\Desktop\\chineseStopWords.txt", 'r') as f:
lines = f.readlines()
for line in lines:
stop_words.append(line.strip())
# 添加关键词
my_words = ['5G', 'CPS', '高速公路', '人工智能', '数字孪生体','工业大数据','智能大数据']
for i in my_words:
jieba.add_word(i)
# 自定义停用词
my_stop_words = ['岗位职能', '任职要求', '岗位', '任职', '...','一个','集团'
'1', '签署', '相关', '数据分析', '岗位职责','协议', '首个',
'巴基斯坦', '印尼', '集团', '提供', '国家','市场','首次','改造'
]
stop_words.extend(my_stop_words)
# 分词
content=';'.join([ str(c) for c in content_series.tolist()])
word_num = jieba.lcut(content)
# 条件筛选
word_num_selected = [i for i in word_num if i not in stop_words and len(i)>=2]
return word_num_selected
text1 = get_cut_words(content_series=df['岗位详情'])
from stylecloud import gen_stylecloud
result = " ".join(text1)
gen_stylecloud(text=result,
font_path='C:\\Windows\\Fonts\\STKAITI.TTF',
# icon_name='fas fa-envira',
icon_name='fas fa-cannabis',
max_words=150,
max_font_size=70,
output_name='C:\\Users\\Administrator\\Desktop\\t11.png',
) #必须加中文字体,否则格式错误

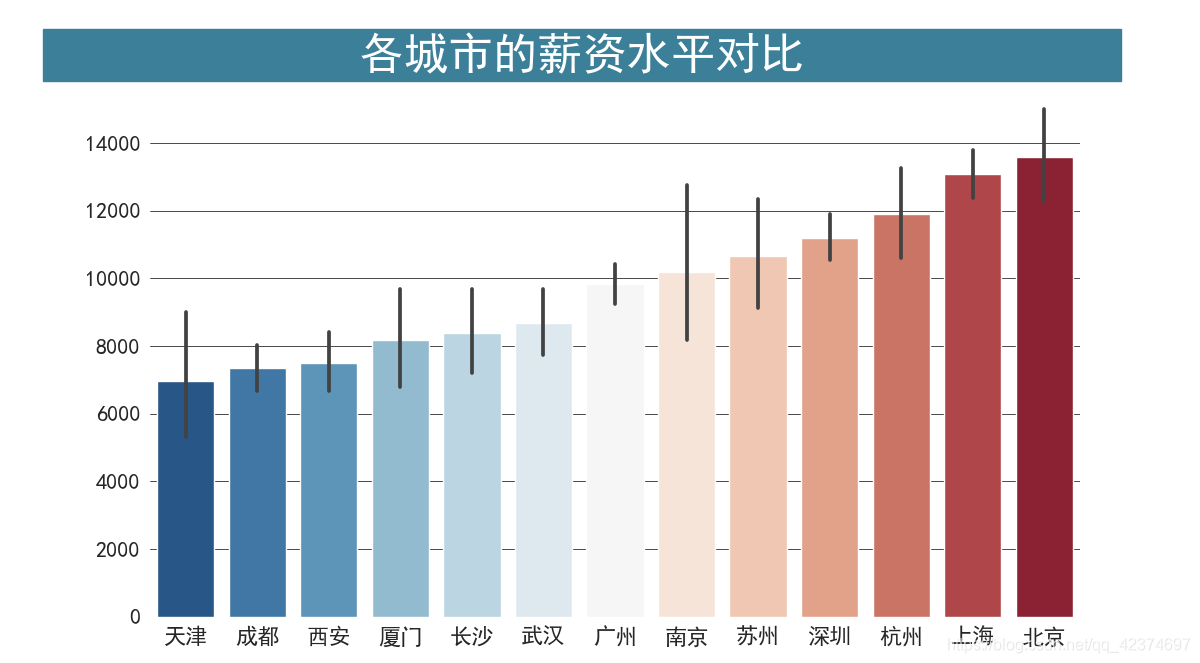
工资水平
fig,ax = plt.subplots(figsize=(12,8))
city_order = df.groupby("工作地点")["工资水平"].mean().sort_values().index.tolist()
sns.barplot(x="工作地点", y="工资水平", order=city_order, data=df, ci=95,palette="RdBu_r")
fig.text(x=0.04, y=0.90, s=' 各城市的薪资水平对比 ',
fontsize=32, weight='bold', color='white', backgroundcolor='#3c7f99')
plt.tick_params(axis="both",labelsize=16,)
ax.yaxis.grid(which='both', linewidth=0.5, color='black')
# ax.set_yticklabels([" ","5k","10k","15k","20k"])
plt.box(False)
plt.xlabel('')
plt.ylabel('')
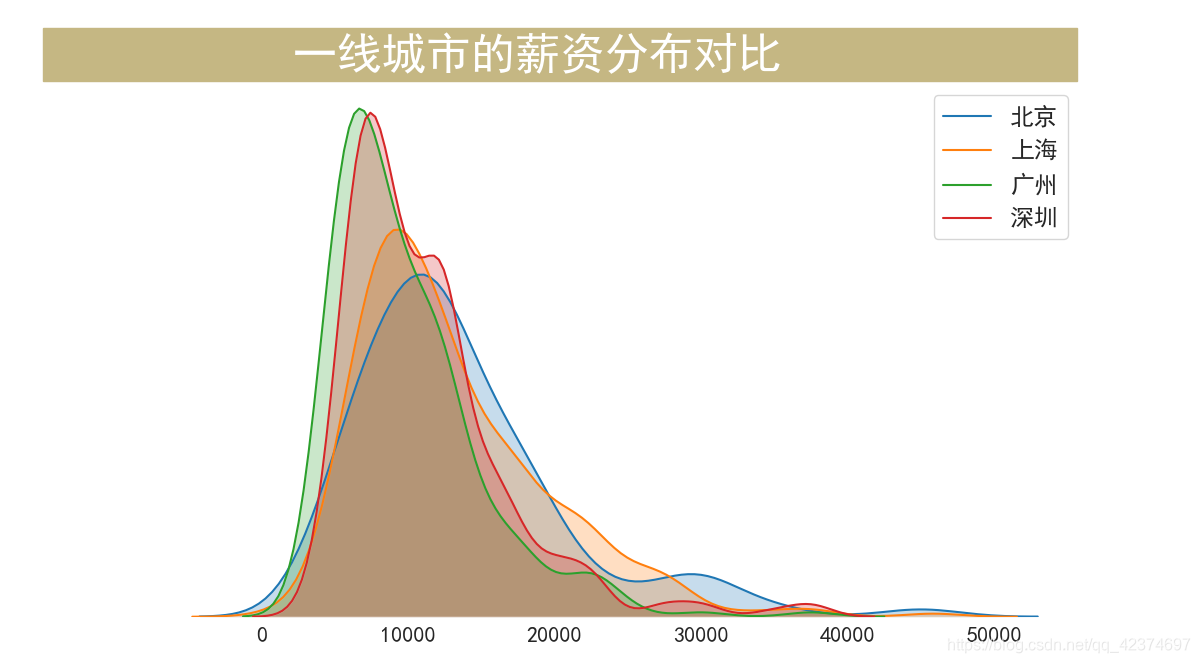
一线城市的薪资分布对比
fig,ax = plt.subplots(figsize=(12,8))
fig.text(x=0.04, y=0.90, s=' 一线城市的薪资分布对比 ',
fontsize=32, weight='bold', color='white', backgroundcolor='#c5b783')
sns.kdeplot(df[df["工作地点"]=='北京']["工资水平"],shade=True,label="北京")
sns.kdeplot(df[df["工作地点"]=='上海']["工资水平"],shade=True,label="上海")
sns.kdeplot(df[df["工作地点"]=='广州']["工资水平"],shade=True,label="广州")
sns.kdeplot(df[df["工作地点"]=='深圳']["工资水平"],shade=True,label="深圳")
plt.tick_params(axis='both', which='major', labelsize=16)
plt.box(False)
# plt.xticks(np.arange(0,61,10), [str(i)+"k" for i in range(0,61,10)])
plt.yticks([])
plt.legend(fontsize = 'xx-large',fancybox=None)
Pyecharts绘图
利用Pyecharts也可以进行数据可视化,基本的需求都能满足,这里我主要是参考文章开头提及的博客代码进行制图。
(1)热门行业的用人需求Top10
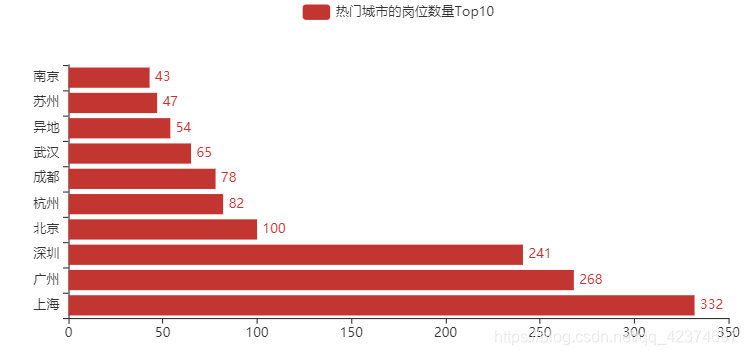
(2)热门城市的岗位数量Top10
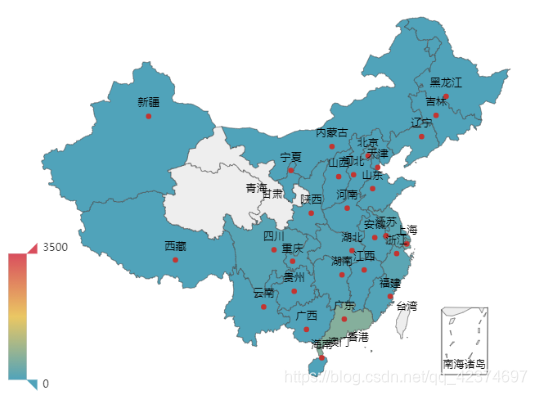
(3)岗位分布
(4)不同公司规模的用人情况
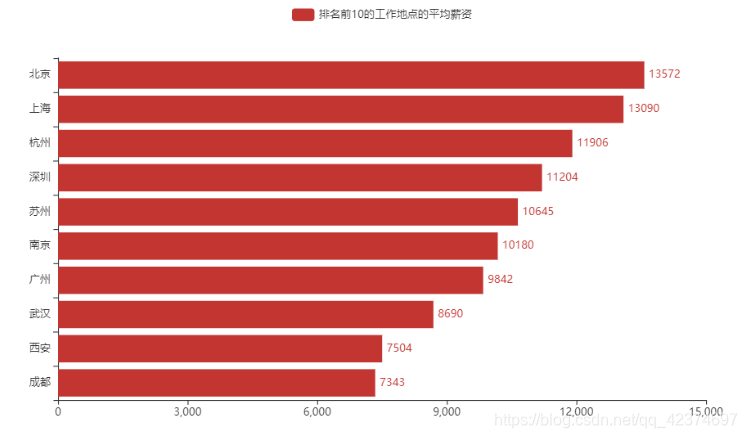
(5)排名前10的工作地点的平均薪资
(6)排名前20的岗位的平均薪资
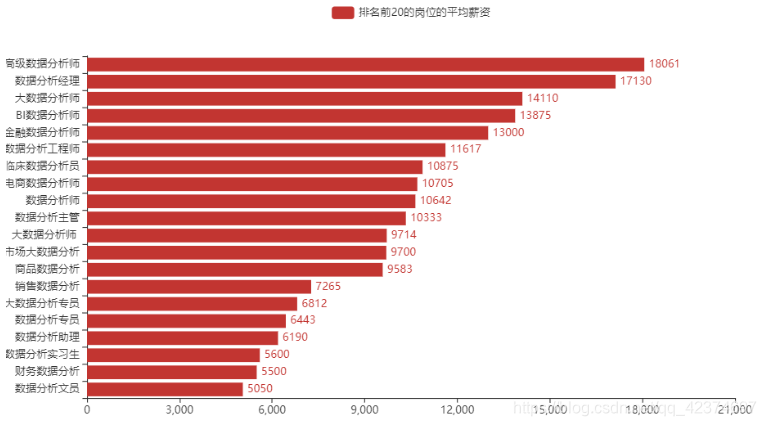
(7)不同学历要求分布
(8)岗位职能与任职要求词云图

最后,做了一个非常简单的组合
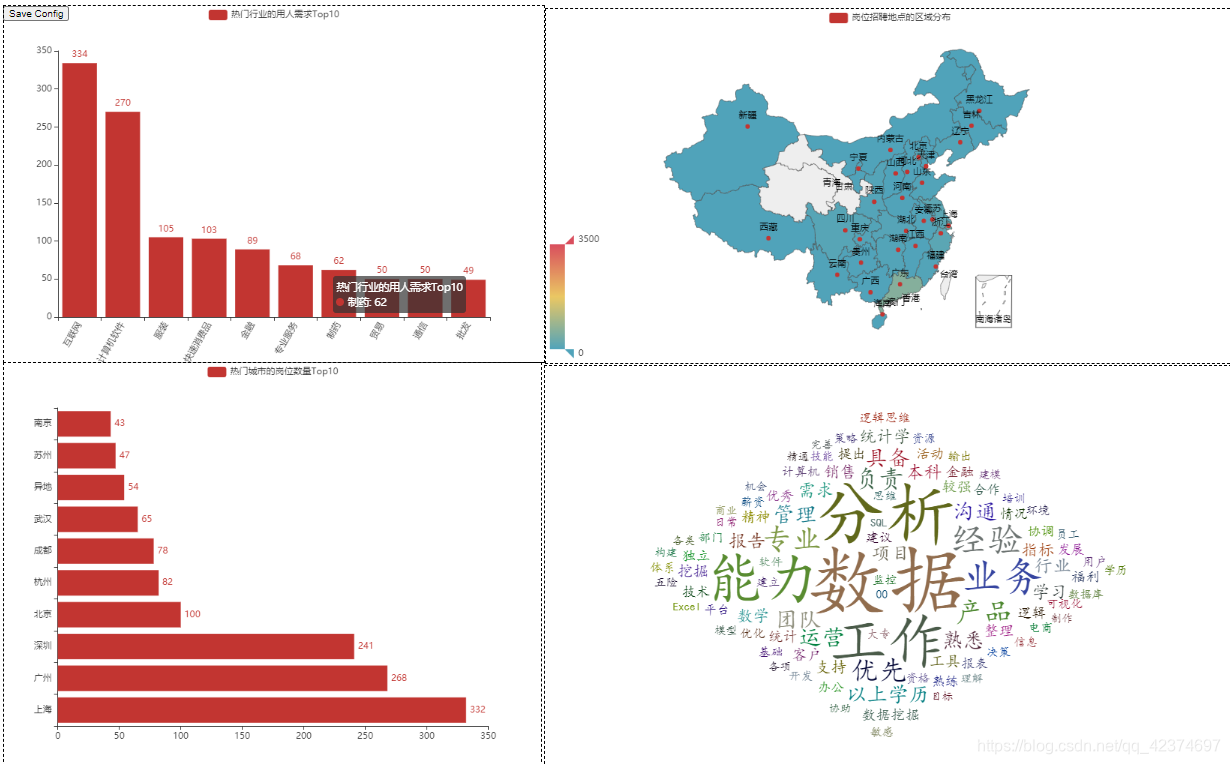
针对所做的内容,进行简单的总结:
- 数据爬取得较少,可能不能反映真实情况;
- 数据处理较为粗糙,没有细致挖掘其中的信息;
- 可以像原博一样做一个可视化大屏,更好的呈现数据
- …

















 7195
7195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









