







bootstrape自助法思想
- 有放回地全抽
有放回的抽取样本,抽取和原样本数量相同的样本
- 抽取和原样本量不同数量的样本:
- 抽取和原样本量不同数量的样本
- 重复抽样进行B次
- 每次都可以求一个相应的统计量/估计量(例如方差)
- 统计量求均值查看稳定性(用方差表示)
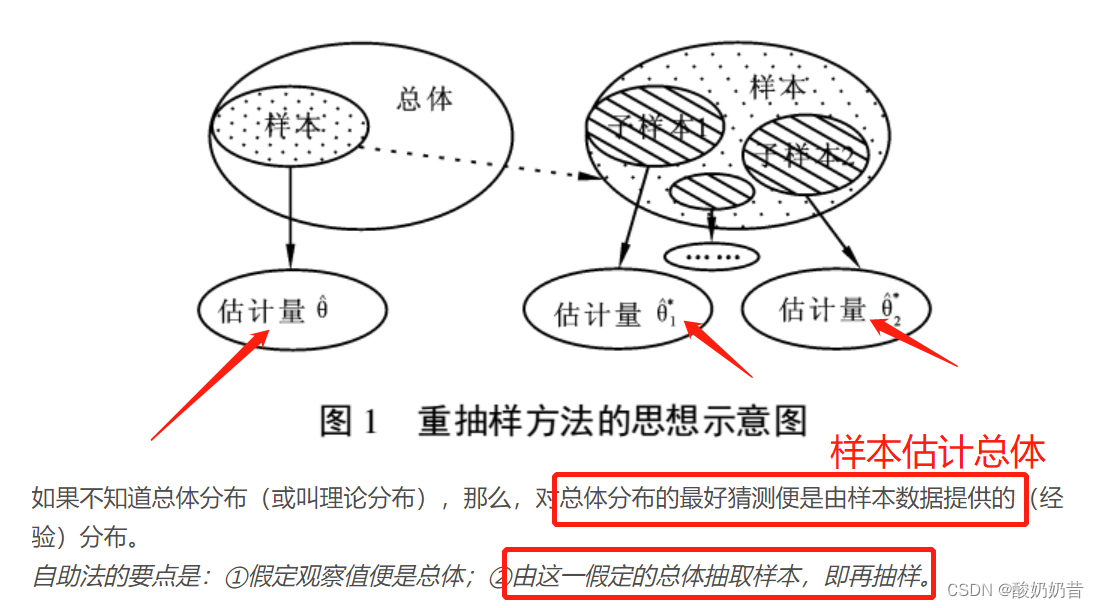
- 例子:一共1000个数据,第一次抽10个数据后放回,第二次抽10个数据后放回…,重复100次,得到1000个数据,重复100次所得到的样本即是bootstrape自助法得到的样本
matlab代码
- bootstrape调用函数:每次抽取一个样本,重复m次,可以根据自身情况进行设计和更改,比如每次抽取10个样本,重复m/10次。
function [s,t]=bootstrape(data)
% s表示bootstrape重复抽样得到的样本
% t表示的是原数据集data中未被重复抽样剩余的样本
t = data;
[m,n] = size(data);
s = zeros(m,n);
labels = [];
for i=1:m
index = unidrnd(m);%产生从1到m所指定的最大数数之间的离散均匀随机整数
labels = [labels index];
s(i,:) = data(index,:);
end
kind=unique(labels);
disp(length(kind))
t(kind,:) = [];
end
- 一次抽样抽取10个样本,重复n次
function [s,t]=bootstrape_10(data)
% s表示bootstrape重复抽样得到的样本
% t表示的是原数据集data中未被重复抽样剩余的样本
N=10;
t = data;
[m,n] = size(data);
s = [];
labels = [];
for i=1:floor(m/N)
index = unidrnd(m,N,1);%产生从1到m所指定的最大数数之间10行1列的离散均匀随机整数
labels = [labels index];
s = [s;data(index,:)];
end
kind=unique(labels);
disp(length(kind))
t(kind,:) = [];
end
- 主函数
clear all;close all;clc;
data=xlsread('自身的原数据集(根据自身情况写).xlsx');
[s,t]=bootstrape(data);
[s1,t1]=bootstrape_10(data);
xlswrite('s.xlsx',s);
xlswrite('t.xlsx',t);
xlswrite('s1.xlsx',s1);
xlswrite('t1.xlsx',t1);














 264
264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









