







 本文提出LoRA+算法,通过为LoRA的适应器矩阵设置不同的学习率,解决了大宽度模型中LoRA的次优问题,实验证明LoRA+在性能和训练速度上优于标准LoRA,尤其是在处理复杂任务时。
本文提出LoRA+算法,通过为LoRA的适应器矩阵设置不同的学习率,解决了大宽度模型中LoRA的次优问题,实验证明LoRA+在性能和训练速度上优于标准LoRA,尤其是在处理复杂任务时。
论文信息
论文标题:LoRA+: Efficient Low Rank Adaptation of Large Models
发表时间:2024年2月
论文内容
摘要
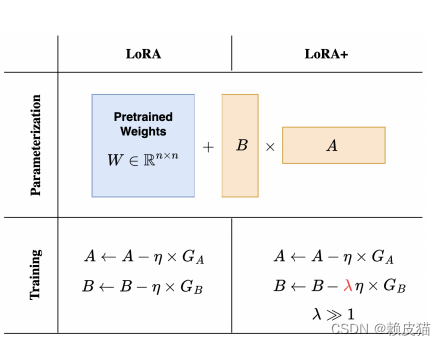
在本文中,我们表明,最初在论文《LoRA: Low-Rank Adaptation of Large Language Models》中引入的低秩适应(LoRA)会导致大宽度(嵌入维度)模型的次优微调。这是因为 LoRA 中的适配器矩阵 A 和 B 以相同的学习率更新。使用大宽度网络的缩放参数,我们证明对 A 和 B 使用相同的学习率并不能实现有效的特征学习。然后我们证明,只需通过精心选择的固定比率为 LoRA 适配器矩阵 A 和 B 设置不同的学习率,即可纠正 LoRA 的这种次优性。我们将此算法称为 LoRA+。在我们广泛的实验中,LoRA+ 提高了性能(1% ‑ 2% 的改进)和微调速度(高达 ~ 2 倍加速),而计算成本与 LoRA 相同。
主要结论
定理 1: (高效 LoRA(非正式))。假设权重矩阵 A 和 B 使用 Adam 进行训练,学习率分别为 η A η_A ηA和 η B η_B ηB。那么,不可能达到 η A = η B η_A = η_B ηA=ηB 的效率。然而,LoRA 微调在$η_A = θ(n^{-1} ) $ 和 η B = θ ( 1 ) η_B = θ(1) ηB=θ(1)时非常有效。
定理1的结果表明,只有一对满足 η B η A = θ ( n ) \frac{η_B}{η_A} = θ(n) ηAηB=θ(n)的学习率才能实现效率。在实践中,这转化为设置 η B ≫ η A η_B ≫ η_A
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









