







 论文提出CodeBLEU,一种针对代码合成的自动评估方法,改进了BLEU和精确匹配,考虑了代码的语法和语义。实验结果显示,CodeBLEU在与人类评分的相关性上优于传统指标。
论文提出CodeBLEU,一种针对代码合成的自动评估方法,改进了BLEU和精确匹配,考虑了代码的语法和语义。实验结果显示,CodeBLEU在与人类评分的相关性上优于传统指标。
论文信息
论文标题:CodeBLEU: a Method for Automatic Evaluation of Code Synthesis
发表时间:2020年9月
论文原文:CodeBLEU: a Method for Automatic Evaluation of Code Synthesis
论文内容
摘要
评价指标对一个领域的发展起着至关重要的作用,因为它定义了区分模型好坏的标准。在代码综合领域,常用的评估指标是 BLEU 或 精确匹配,但它们是不太适合评估代码能力,因为BLEU最初是为了评估自然语言而设计的,忽略了代码的重要语法和语义;而精确匹配因太过严格,导致低估具有相同的语义逻辑的不同输出。为了解决这个问题,我们引入了一个新的自动评估指标,称为CodeBLEU。它吸收了BLEU在n-gram匹配中的优势,并进一步通过抽象语法树(AST)引入代码语法,通过数据流引入代码语义。我们通过评估CodeBLEU与程序员在三个代码合成任务(即文本生成码、代码翻译和代码优化)上分配的质量分数之间的相关系数来进行实验。实验果表明,与BLEU和精确匹配相比,我们提出的Code-BLEU可以与程序员分配的分数实现更好的相关性。
主要思路
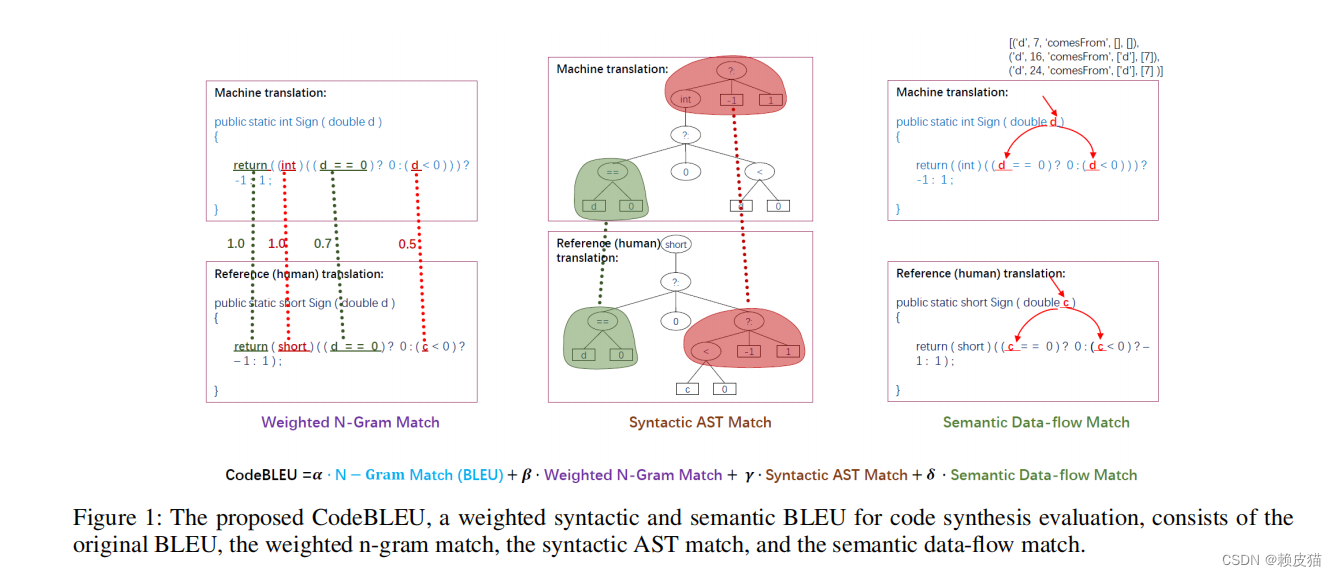
论文主要的思想是,在BLEU算法的基础上,增加了其余的三个指标用于解决BLEU的三个问题。
- BLEU对每个单词都是一样的,而代码其实是有保留字和声明名称的。对于语言的保留字和声明名称(如变量名、类名等)、常量数值(字符串、数值等),其重要性远远大于普通的名称声明。在这篇论文中,引入了带权重的 BLEU 算法,将保留字的权重设置为普通词的4倍,以应对该问题。
- BLEU将代码作为一串普通文本进行对比,忽略了代码语法。实际上,代码作为一个人为创建的语言,具备很强的逻辑性。该论文引入了AST语法树,通过对比语法树来引入对于代码语法的评估。
- BLEU将代码以自然语言的形式理解,忽略了代码语义。代码作为逻辑性很强的语言,一个语义的差别,可能带来的结果却是天差地别。该模型引入了数据流,以图的形式比较数据流的相似性,将代码语义引入评估模型中。
根据上述描述,CodeBLEU的最终得分公式如下:
C o d e B L E U = α ⋅ B L E U + β ⋅ B L E U w e i g h t + γ ⋅ M a t c h a s t + δ ⋅ M a t c h d f CodeBLEU =α · BLEU + β · BLEU_{weight} + γ · Match_{ast} + δ · Match_{df} CodeBLEU=α⋅BLEU+β⋅BLEUweight+γ⋅Matchast+δ⋅Matchdf
典型示例
论文中给了一正一反两个示例,来证明CodeBLEU比BLEU更加准确。
- 反例

这个例子中,参考代码是将一个double类型的数据转化为int类型。而候选代码则将数据转化成了float类型。使用BLEU算法,计算出的相似度为75.43。而考虑了语法和语义的CodeBLEU则对于返回类型的差异做了惩罚扣分,最终结果为69.73。
- 正例

参考代码的逻辑和反例相同,而候选代码中,只是变量名称换了,这丝毫不影响代码的整体逻辑。如果是人工评测,我们会打100分,因为这两段代码的功能是一样的。然而BLEU算法的打分只有68.14分,而考虑语法和语义的CodeBLEU算法的得分为83.97,一定程度上修正了误判。
实现细节
加权N‑Gram匹配
原始 BLEU 比较候选和参考之间的 n 元语法,并计算匹配的 n 元语法的比率。与自然语言的词汇量庞大、词序自由相比,编程语言是人工设计的,只有“int”、“public”等少数几个关键字。将传统的BLEU直接应用到代码综合中会忽略关键字的重要性。因此,我们引入加权n‑gram匹配,为不同的n‑gram分配不同的权重,使得关键词具有更高的权重。
计算公式如下:
p n = ∑ C ∈ C a n d i d a t e s ∑ i = 1 l µ n i ⋅ C o u n t c l i p ( C ( i , i + n ) ) ∑ C ′ ∈ C a n d i d a t e s ∑ i = 1 l µ n i ⋅ C o u n t
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1072
1072

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









