









说明:
💡💡💡本文后续更新和完善将在新账号展开,请移步新地址:
深度学习笔记——ViT、ViLT
深度学习笔记——DiT(Diffusion Transformer)
历史文章
机器学习
机器学习笔记——损失函数、代价函数和KL散度
机器学习笔记——特征工程、正则化、强化学习
机器学习笔记——30种常见机器学习算法简要汇总
机器学习笔记——感知机、多层感知机(MLP)、支持向量机(SVM)
机器学习笔记——KNN(K-Nearest Neighbors,K 近邻算法)
机器学习笔记——朴素贝叶斯算法
机器学习笔记——决策树
机器学习笔记——集成学习、Bagging(随机森林)、Boosting(AdaBoost、GBDT、XGBoost、LightGBM)、Stacking
机器学习笔记——Boosting中常用算法(GBDT、XGBoost、LightGBM)迭代路径
机器学习笔记——聚类算法(Kmeans、GMM-使用EM优化)
机器学习笔记——降维
深度学习
深度学习笔记——优化算法、激活函数
深度学习——归一化、正则化
深度学习——权重初始化、评估指标、梯度消失和梯度爆炸
深度学习笔记——前向传播与反向传播、神经网络(前馈神经网络与反馈神经网络)、常见算法概要汇总
深度学习笔记——卷积神经网络CNN
深度学习笔记——循环神经网络RNN、LSTM、GRU、Bi-RNN
深度学习笔记——Transformer
深度学习笔记——3种常见的Transformer位置编码
深度学习笔记——GPT、BERT、T5
深度学习笔记——ViT、ViLT
深度学习笔记——DiT(Diffusion Transformer)
深度学习笔记——多模态模型CLIP、BLIP
深度学习笔记——AE、VAE
深度学习笔记——生成对抗网络GAN
深度学习笔记——模型训练工具(DeepSpeed、Accelerate)
深度学习笔记——模型压缩和优化技术(蒸馏、剪枝、量化)
文章目录
ViT
ViT(Vision Transformer) 是一种将 Transformer 模型用于计算机视觉任务中的创新架构。ViT 只使用了 Transformer 的编码器 部分进行特征提取和表征学习。
论文:AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
1. ViT的基本概念
ViT 的核心思想是将传统的(CNN)的卷积操作替换为 Transformer 的注意力机制,借鉴 Transformer 模型在自然语言处理(NLP)中的成功经验,用于图像分类任务。
2. ViT的结构与工作流程
ViT的架构如下图所示:
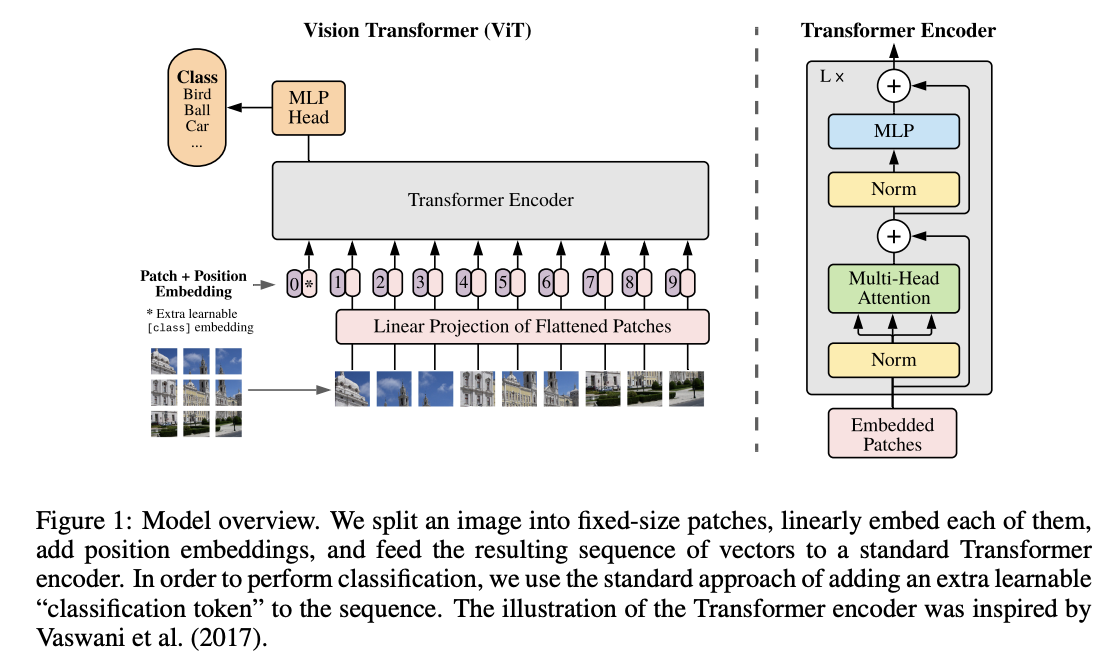
图1:模型概览。我们将一幅图像分割为固定大小的图块,将每个图块线性嵌入(embed),添加位置嵌入(position embedding),并将得到的向量序列输入到标准的Transformer编码器中。为了实现分类任务,我们采用标准的方法,在序列中添加一个额外的可学习的“分类标记”(classification token)。Transformer编码器的示意图受到 Vaswani 等人 (2017) 的启发。
ViT 模型的工作流程如下:
1. 图像分块(Image Patch Tokenization)
ViT 将输入的图像划分为固定大小的图像块(patches),并将这些图像块展开为一维向量,类似于将图像分成许多小的"单词"。然后,将每个图像块转换为一个嵌入向量,这些嵌入向量类似于 NLP 中的词嵌入(Word Embedding)。
- 假设输入图像的尺寸是 224 × 224 224 \times 224 224×224,将其划分为尺寸为 16 × 16 16 \times 16 16×16 的小块。这将产生 14 × 14 = 196 14 \times 14 = 196 14×14=196 个图像块。
- 每个图像块的像素值被展平成一维向量,并通过线性映射(全连接层)转换为固定维度的嵌入向量。
2. 位置编码(Positional Encoding)
因为 Transformer 的注意力机制不依赖于输入的顺序,而图像中的空间信息是重要的,因此需要给每个图像块添加位置编码(Positional Encoding),以保留图像块的位置信息。这样,Transformer 可以理解图像块之间的相对位置关系。
- 位置编码的方式与 NLP 中的 Transformer 类似,ViT 默认使用 可学习的1D位置编码,将二维图像的分割图块按照固定顺序展平成一维序列后,为序列中的每个位置分配一个可学习的编码向量。
本文主要解读默认的位置编码,后续提到的ViT的编码也是“可学习的1D位置编码”。
有序其他模型有优化使用**基于频率的二维位置编码(2D Frequency Embeddings)**来编码图像块的位置。详情请参考:深度学习笔记——常见的Transformer位置编码
3. Transformer 编码器(Transformer Encoder)
图像块和位置编码结合后,作为输入送入 Transformer 编码器。Transformer 编码器的每一层由多头自注意力机制(Multi-Head Self-Attention)和前馈神经网络(Feed-Forward Network, FFN)组成,并通过残差连接和层归一化来保持梯度稳定性。
- 多头自注意力机制:每个图像块与其他所有图像块之间的相似性通过自注意力机制计算,模型通过这种机制捕捉全局的特征表示。
- 前馈神经网络(FFN):每个图像块的特征表示通过前馈网络进一步提炼。
这个过程类似于传统的 Transformer 中对词的处理,只不过这里处理的是图像块。
4. 分类标记(Classification Token)
ViT 模型在输入图像块之前,通常会添加一个分类标记([CLS] Token)。这个分类标记类似于 BERT 模型中的 [CLS] 标记,用来代表整个图像的全局特征。最终,经过 Transformer 编码器的处理后,CLS 标记的输出被用于进行图像分类。
- CLS 标记的输出经过一个全连接层,将其映射到目标类别空间中,得到最终的分类结果。CLS 是 “classification” 的缩写,表示分类。它是一个附加到图像块序列之前的向量,类似于 BERT 模型中处理文本任务时添加的 [CLS] 标记。CLS 标记没有直接对应于任何特定的图像块,它只是一个特殊的向量,用于捕获整个图像的全局信息。
[0.9, 0.05, 0.05]
表示 90% 的概率是“猫”,5% 的概率是“狗”,5% 的概率是其他类别。

3. ViT的关键组件
1. 图像块(Patch Embedding)
ViT 将图像划分为固定大小的图像块,并将其展平为一维向量。这与传统 CNN 的卷积操作不同,CNN 的卷积操作是基于局部感受野,而 ViT 直接处理全局特征。
2. 多头自注意力机制(Multi-Head Self-Attention)
ViT 的核心是使用多头自注意力机制来计算每个图像块与其他图像块之间的关系。与 CNN 通过层级卷积提取特征不同,ViT 通过全局的自注意力机制捕捉图像的特征表示。


















 865
865

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









