






VIT
原始论文: An Image is Worth 16x16 Words Transformers for Image Recognition at Scale
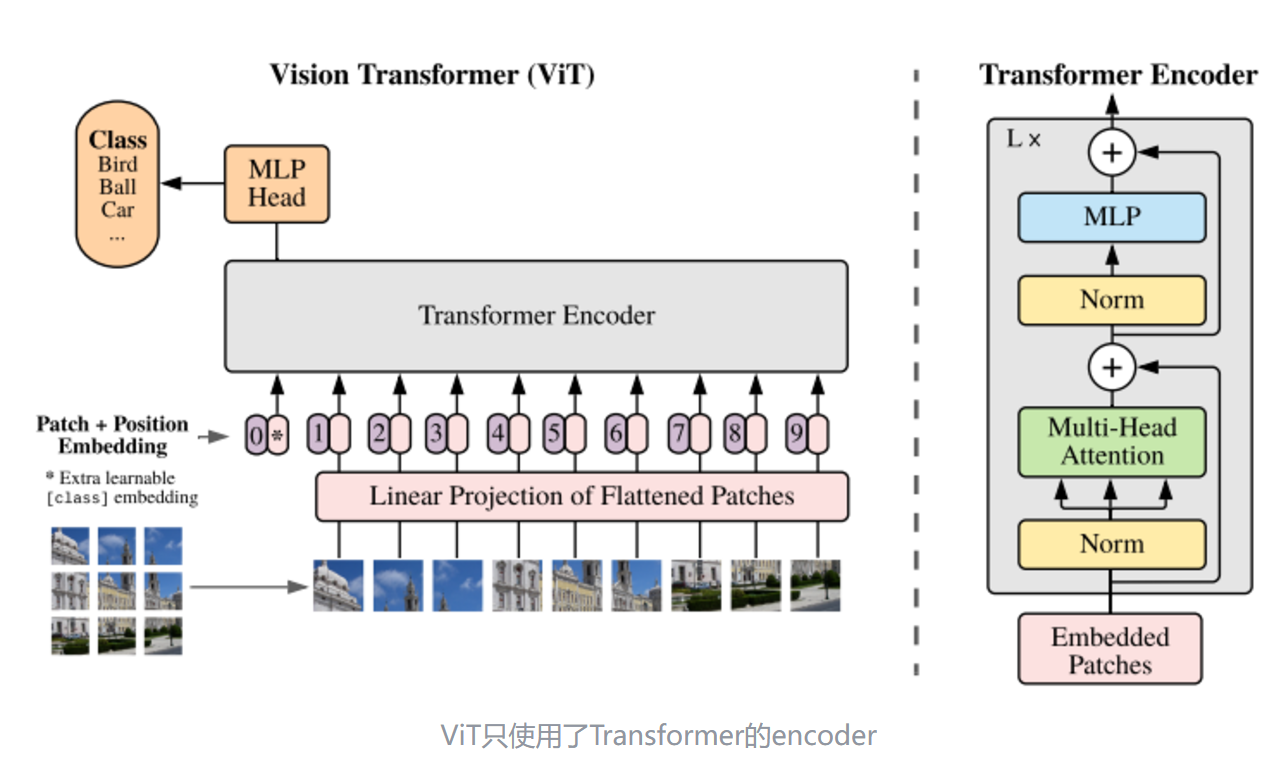
举例
通过例子便于理解:
输入图片大小为224x224,patch大小为16x16,channel为3
(1) patch embedding:输入图片大小为224x224,将图片分为固定大小的patch,patch大小为16x16,则每张图像会生成224x224/16x16=196个patch,即输入序列长度为196,每个patch维度16x16x3=768,线性投射层的维度为768x768,也就是等维度投影,因此输入通过线性投射层之后的维度依然为196x768。即一共有196个token,每个token的维度是768。
这里还需要加上一个特殊字符cls,可以当做结束字符,patch数量增加1,因此最终的维度是197x768。到目前为止,已经通过patch embedding将一个视觉问题转化为了一个seq2seq问题
(2) positional encoding(standard learnable 1D position embeddings):ViT同样需要加入位置编码,位置编码映射后维度和输入序列embedding的维度相同(768)。注意位置编码的操作是sum,而不是concat。加入位置编码信息之后,维度依然是197x768
(3) LN/multi-head attention/LN:LN输出维度依然是197x768。多头自注意力时,先将输入映射到q,k,v,如果只有一个头,qkv的维度都是197x768,如果有12个头(768/12=64),则qkv的维度是197x64,一共有12组qkv,最后再将12组qkv的输出拼接起来,输出维度是197x768,然后在过一层LN,维度依然是197x768
(4) MLP:将维度放大再缩小回去,197x768放大为197x3072,再缩小变为197x768
一个block之后维度依然和输入相同,都是197x768,因此可以堆叠多个block。最后会将特殊字符cls对应的输出
z
L
0
z^0_L
zL0作为encoder的最终输出 ,代表最终的image presentation(另一种做法是不加cls字符,对所有的tokens的输出做一个平均),如下图公式(4),后面接一个MLP进行图片分类
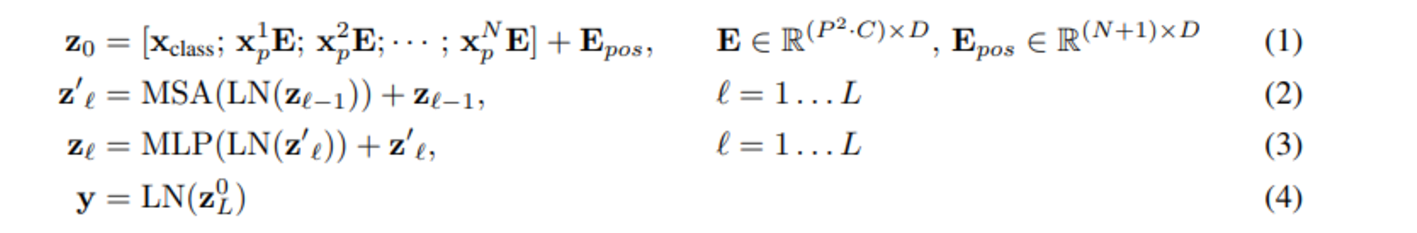
ViT 的核心结构与原理
ViT 的结构主要由以下几个部分组成:
- 图像切分(Patch Partitioning)
- 将输入图像(例如大小为 224×224224×224 224 \times 224224×224 的 RGB 图像)划分为固定大小的小块(patch),例如 16×1616×16 16 \times 1616×16 像素的小块。
- 每个小块被展平为一个一维向量,形成长度为 NN NN 的序列(N=总块数=(图像高度/块大小)2N=总块数=(图像高度/块大小)2 N = \text{总块数} = \text{(图像高度}/\text{块大小)}^2N=总块数=(图像高度/块大小)2)。
- 线性嵌入(Linear Projection of Patches)
- 将每个 patch 的向量通过一个线性投影(如全连接层),映射到固定的嵌入维度 DD DD。
- 位置编码(Positional Encoding)
- 因为 Transformer 本质上是无序的,所以需要为每个 patch 添加位置信息,确保模型知道各个 patch 的相对位置。
- Transformer 编码器(Transformer Encoder)
- 使用标准的 Transformer 编码器架构,包括 多头自注意力机制(Multi-Head Self-Attention)和 前馈网络(Feedforward Network)。
- 输入的 patch 序列通过多层 Transformer 编码器,学习全局的特征关系。
- 分类头(Classification Head)
- 在所有的 patch 序列前添加一个特殊的 [CLS] Token,表示全局图像特征。
- 最后将 [CLS] Token 的嵌入输出通过一个全连接层,用于分类任务
应用
图像分类:ViT 在 ImageNet 等图像分类任务上表现优异。
目标检测:结合 ViT 的框架如 DETR(基于 Transformer 的目标检测模型)已被广泛应用。
图像生成:在生成模型(如扩散模型)中,ViT 可作为特征提取模块。
跨模态学习:在多模态模型(如 CLIP)中,ViT 负责处理图像特征,与文本特征对齐。
UVIT
介绍
U-ViT(U-shaped Vision Transformer)是一种将 Vision Transformer(ViT)架构应用于扩散模型的创新设计。传统上,基于卷积神经网络(CNN)的 U-Net 在扩散模型中占据主导地位,而 U-ViT 则探索了使用 ViT 作为扩散模型骨干网络的可能性。
pape:All are Worth Words: A ViT Backbone for Diffusion Models
仓库:https://github.com/baofff/U-ViT
发表在2023年CVPR上
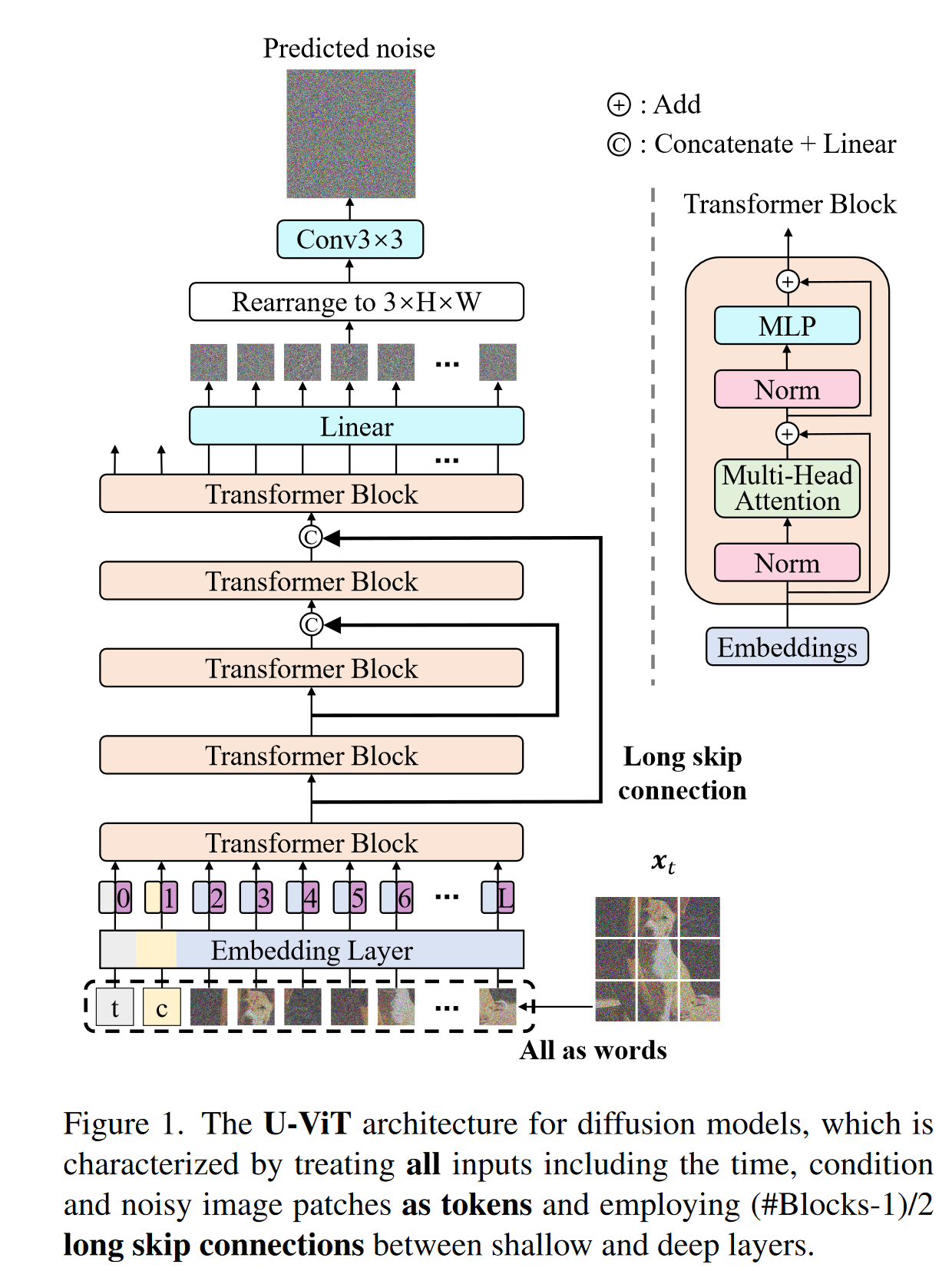
创新点
- 将时间t,条件c,和图像patch视作token输入到Transformer block
- 引入long skip connection
DIT
介绍
是与UVIT的同期工作
paper:Scalable Diffusion Models with Transformers
Diffusion Transformer (DiT) 是一种将 Transformer 架构应用于扩散模型的生成模型,旨在利用 Transformer 的自注意力机制来生成高质量的图像。传统的扩散模型通常采用基于卷积神经网络(CNN)的 U-Net 结构,而 DiT 则探索了使用 Vision Transformer(ViT)作为扩散模型骨干网络的可能性。
DiT 的核心特点:
- Transformer 架构:DiT 使用 ViT 作为主干网络,将图像划分为固定大小的块(patch),并将其作为序列输入到 Transformer 中进行处理。
- 条件输入处理:DiT 设计了多种处理条件输入的方法,包括 In-Context Conditioning、Cross-Attention、Adaptive Layer Norm(adaLN)等,以增强模型的生成能力。
- 模型可扩展性:通过调整模型的深度、宽度和输入 token 的数量,DiT 展现出良好的可扩展性,能够在计算复杂度和生成质量之间取得平衡。
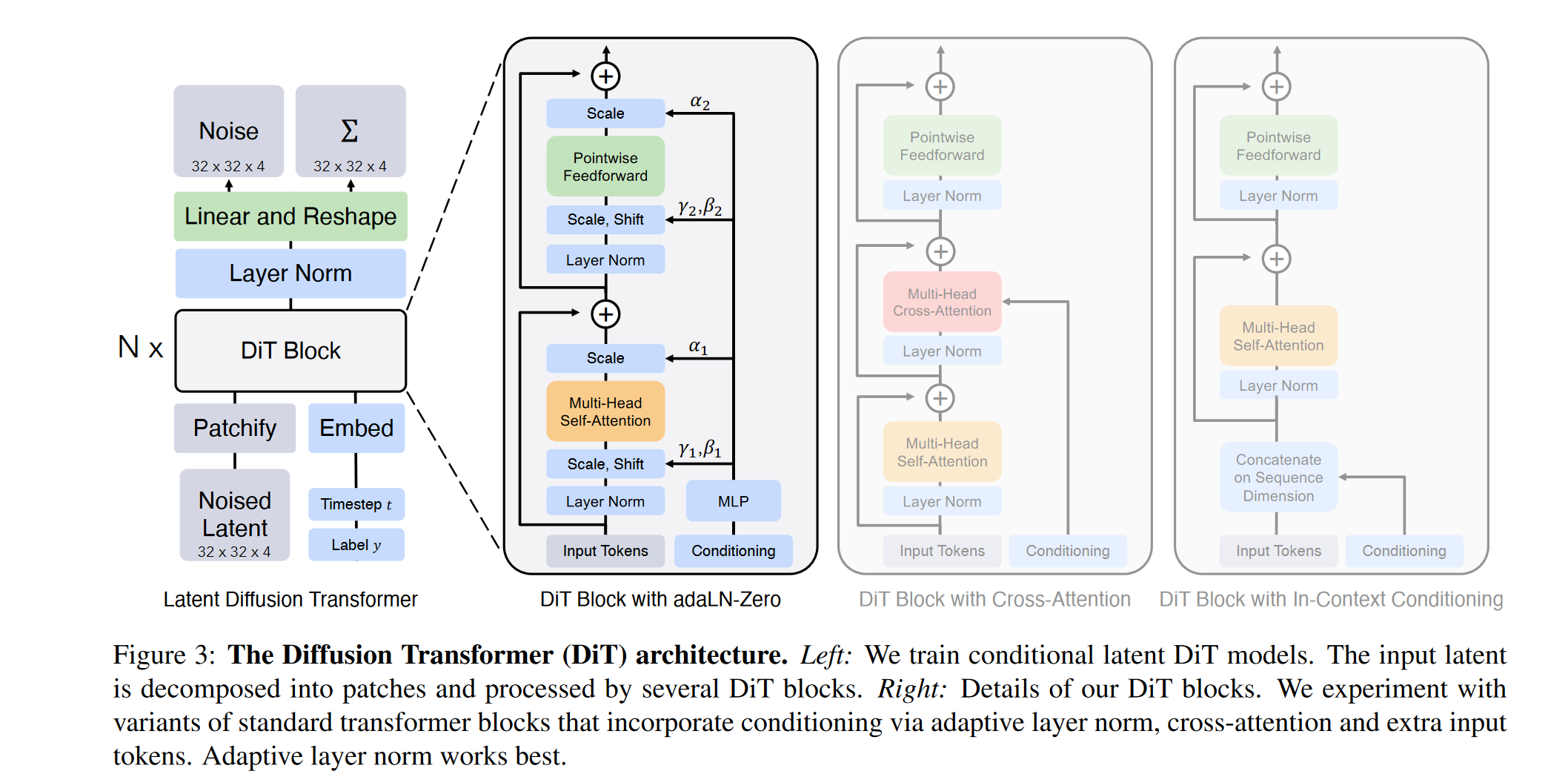
提出了使用ViT代替U-Net的思想,不同的是DiT中没有引入long skip connection也依然取得了杰出的效果。UVIT作者推测原因可能有:
- DiT 出色的Adaptive layer norm以及零初始化的设计能够有效提升生成质量;
- DiT 在建模特征空间表现良好,但在建模像素空间表现欠缺,可能在用扩散概率模型建模像素空间分布时long skip connection是至关重要的;
- 即使在建模特征空间上,DiT 没有long skip connection也能取得很好的效果,但long skip connection在加速收敛方面也起着关键的作用,如下图所示:
D a t a M o d e l P a r a m s ( M ) F l o p s ( G ) B a t c h S i z e T r a i n i n g I t e r a t i o n F i d I m a g e N e t 256 ( L a t e n t D i f f u s i o n ) U − V i T − H / 2 501 133 1024 50 k 2.29 I m a g e N e t 256 ( L a t e n t D i f f u s i o n ) D i T − X L / 2 675 118 256 700 k 2.27 \begin{array}{|c|c|c|c|c|c|c|} \hline Data & Model & Params(M) & Flops(G) & Batch Size & Training Iteration & Fid \\ \hline ImageNet256 (Latent Diffusion) & U-ViT-H/2 & 501 & 133 & 1024 & 50k & 2.29 \\ \hline ImageNet256 (Latent Diffusion) & DiT-XL/2 & 675 & 118 & 256 & 700k & 2.27 \\ \hline \end{array} DataImageNet256(LatentDiffusion)ImageNet256(LatentDiffusion)ModelU−ViT−H/2DiT−XL/2Params(M)501675Flops(G)133118BatchSize1024256TrainingIteration50k700kFid2.292.27
相对来说,UVIT比DIT多做了跳接,两者侧重点不同
总结
| 特性 | Diffusion Model | ViT | DiT | U-ViT |
|---|---|---|---|---|
| 模型目标 | 图像生成、修复、去噪 | 图像分类、分割等任务 | 扩散模型中的图像生成 | 高分辨率图像生成和修复 |
| 主干架构 | 通常是 U-Net | 标准 Transformer | 基于 ViT 的扩散模型 | ViT + U-Net 结构 |
| 特征建模 | 局部特征为主 | 全局特征建模 | 全局特征建模 | 全局与局部特征结合 |
| 条件处理 | 时间步、类别标签等 | 无条件 | 强条件(文本嵌入等) | 强条件(多模态支持) |
| 适用场景 | 图像生成、修复、去噪 | 图像分类、检测、分割 | 条件和无条件图像生成 | 多尺度生成、多模态生成 |
| 创新点 | 基于去噪的生成过程 | 引入 Transformer 替代 CNN | 在扩散模型中引入 ViT | 融合 ViT 和 U-Net 特性 |
参考
# 『论文精读』Vision Transformer(VIT)论文解读
# ViT(Vision Transformer)解析
# U-ViT: A ViT Backbone for Diffusion Models
# U-ViT(CVPR2023)——ViT与Difussion Model的结合
# 一文带你搞懂DiT(Diffusion Transformer)
扩散模型解读 (一):DiT 详细解读 - 知乎专栏


















 616
616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









