







目录
XGBoost算法原理参考其他详细博客以及官方文档
LightGBM算法原理参考其他详细博客以及官方文档
这里介绍两个算法的简单案例应用。
1 XGBoosting案例:金融反欺诈模型
信用卡盗刷一般发生在持卡人信息被不法分子窃取后复制卡片进行消费或信用卡被他人冒领后激活并消费等情况下。一旦发生信用卡盗刷,持卡人和银行都会遭受一定的经济损失。因此,通过大数据技术搭建金融反欺诈模型对银行来说尤为重要。
1.1 模型搭建
XGBoost算法既能做分类分析,又能做回归分析,对应的模型分别为XGBoost分类模型(XGBClassifier)和XGBoost回归模型(XGBRegressor)。
这里以分类模型为例简单演示使用。
1.1.1 读取数据
通过如下代码读取1000条客户信用卡的交易数据。
特征变量有客户换设备次数、在本次交易前的支付失败次数、换IP的次数、换IP国的次数及本次交易的金额。
目标变量是本次交易是否存在欺诈,若是盗刷信用卡产生的交易则标记为1,代表欺诈,正常交易则标记为0。
其中有400个欺诈样本,600个非欺诈样本。

1.1.2 特征变量与目标变量提取、划分数据集与测试集
X = df.drop(columns='欺诈标签')
y = df['欺诈标签']
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=123)1.1.3 模型搭建及训练
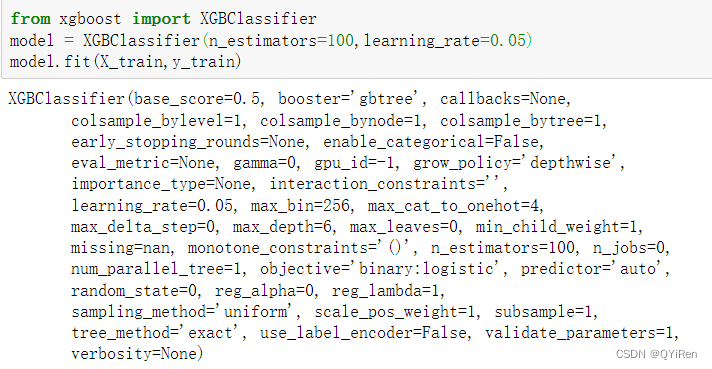
第2行代码将XGBClassifier()赋给变量model,并设置弱学习器的最大迭代次数,或者说弱学习器的个数n_estimators参数为100,以及弱学习器的权重缩减系数learning_rate为0.05,其余参数都使用默认值。
1.2 模型预测及评估
模型搭建完毕后,通过如下代码对测试集数据进行预测。

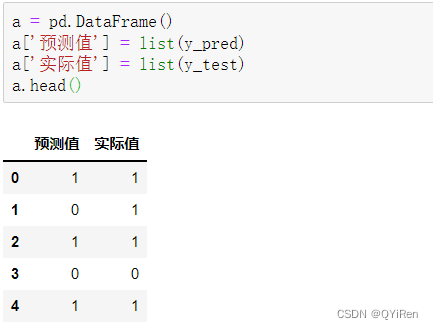
通过如下代码可以汇总预测值和实际值,以便进行对比。

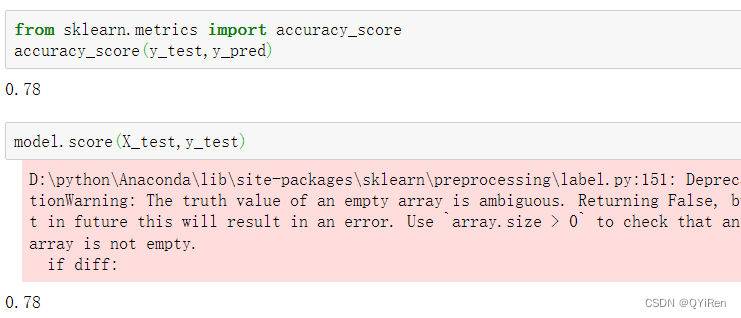
可以看到,前5项的预测准确度为60%。通过如下代码可以查看所有测试集数据的预测准确度。

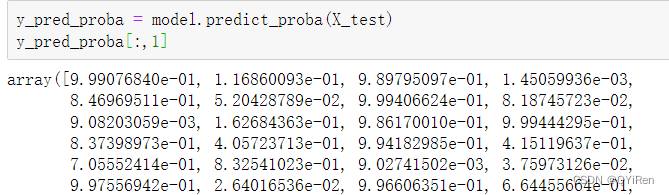
XGBoost分类模型在本质上预测的并不是准确的0或1的分类,而是预测样本属于某一分类的概率,可以用predict_proba()函数查看预测属于各个分类的概率,代码如下。
y_pred_proba = model.predict_proba(X_test)
y_pred_proba[:,1]获得的y_pred_proba是一个二维数组,其中第1列为分类为0(即非欺诈)的概率,第2列为分类为1(即欺诈)的概率,如上是查看欺诈(分类为1)的概率。
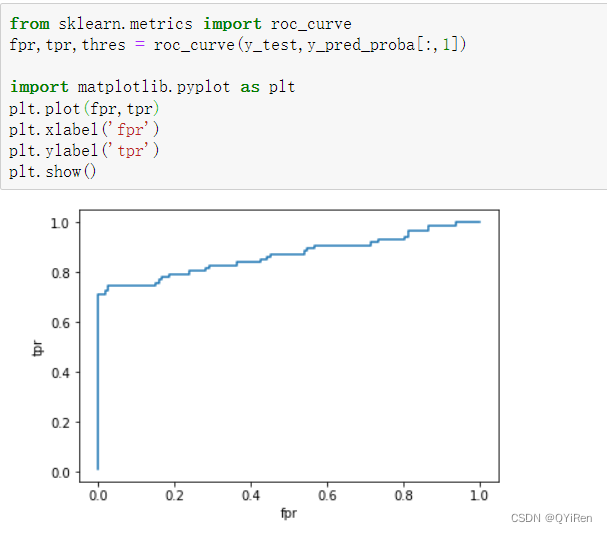
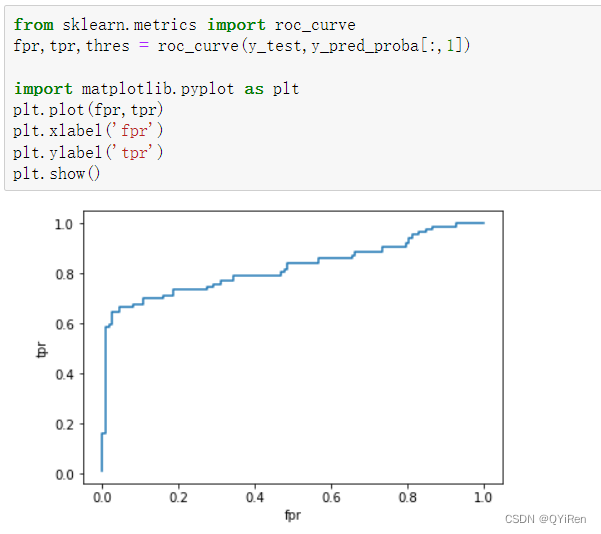
下面通过绘制ROC曲线来评估模型的预测效果,代码如下。
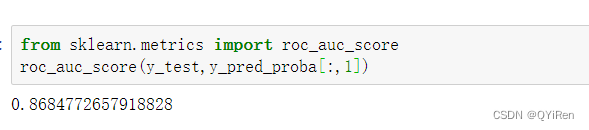
通过如下代码计算模型的AUC值。
通过如下代码可以查看各个特征变量的特征重要性,以便筛选出信用卡欺诈行为判断中最重要的特征变量。

1.3 模型参数调优
使用GridSearch网格搜索进行参数调优。
from sklearn.model_selection import GridSearchCV
parameters = {'max_depth':[1,3,5],'n_estimators':[50,100,150],'learning_rate':[0.01,0.05,0.1,0.2]}
model = XGBClassifier()
grid_search = GridSearchCV(model,parameters,scoring='roc_auc',cv=5)
grid_search.fit(X_train,y_train)
grid_search.best_params_
# 输出最佳参数
# {'learning_rate': 0.05, 'max_depth': 1, 'n_estimators': 100}从上述结果可以看出,针对本案例的数据,弱学习器决策树的最大深度限制为1,弱学习器的最大迭代次数设置为100,弱学习器的权重缩减系数设置为0.05时,模型的预测效果最佳。
2 LightGBM案例:客户违约预测模型
银行等金融机构经常会根据客户的个人资料、财产等情况,来预测借款客户是否会违约,以便进行贷前审核、贷中管理、贷后违约处理等工作。金融处理的就是风险,需要在风险和收益之间寻求一个平衡点,现代金融在某种程度上是一个风险定价的过程。通过海量数据对客户进行风险评估并进行合适的借款利率定价,这便是一个典型的风险定价过程,又称为大数据风控。
2.1 模型搭建
LightGBM算法既能做分类分析,又能做回归分析,对应的模型分别为LightGBM分类模型(LGBMClassifier)和LightGBM回归模型(LGBMRegressor)。
这里以分类模型为例简单演示。
2.1.1 读取数据

先读取1000条客户信息及违约表现数据。
特征变量有收入、年龄、性别、历史授信额度、历史违约次数;
目标变量为是否违约,若违约则标记为1,否则标记为0。
2.1.2 提取特征变量和目标变量、划分训练集和测试集
X = df.drop(columns='是否违约')
y = df['是否违约']
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=123)2.1.3 模型训练和搭建

2.2 模型预测及评估
模型搭建完毕后,通过如下代码对测试集数据进行预测。
通过如下代码汇总预测值和实际值,以便进行对比。
通过如下代码可以查看模型整体的预测准确度。
LGBMClassifier在本质上预测的并不是准确的0或1的分类,而是预测样本属于某一分类的概率,可以用predict_proba()函数查看预测属于各个分类的概率,代码如下。
通过如下代码可以绘制ROC曲线来评估模型的预测效果。
通过如下代码计算模型的AUC值。

通过如下代码对特征名称和特征重要性进行汇总,以便筛选出客户违约预测中最重要的特征变量。

可以看到,“收入”的特征重要性最高,“历史授信额度”的特征重要性为第二高,“性别”的特征重要性最低。“历史违约次数”的特征重要性不是很高,这与经验认知不符,可能的原因是本案例的数据较少,而实际应用中当数据量较大时,该特征还是有较高的特征重要性的。
另外需要注意的一点是,之前学过的机器学习模型的特征重要性为小数,而LightGBM模型的特征重要性均为整数。
2.3 模型参数调优
使用GridSearch网格搜索进行参数调优,代码如下。
from sklearn.model_selection import GridSearchCV
parameters = {'num_leaves':[10,15,31],'n_estimators':[10,20,30],'learning_rate':[0.05,0.1,0.2]}
model = LGBMClassifier()
grid_search = GridSearchCV(model,parameters,scoring='roc_auc',cv=5)
grid_search.fit(X_train,y_train)
grid_search.best_params_
# 输出
# {'learning_rate': 0.1, 'n_estimators': 20, 'num_leaves': 10}也就是说,针对本案例的数据,弱学习器的权重缩减系数设置为0.1,最大迭代次数设置为20,决策树的最大叶子节点数设置为10时,模型的预测效果最佳。
参考书籍
《Python大数据分析与机器学习商业案例实战》















 7218
7218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









