







本系列文章如果没有特殊说明,正文内容均解释的是文字上方的图片
卷积神经网络 | DeepLearning.AI
2021吴恩达深度学习-卷积神经网络_bilibili
2 深度卷积网络模型:案例研究
2-2 经典网络
LeNet-5
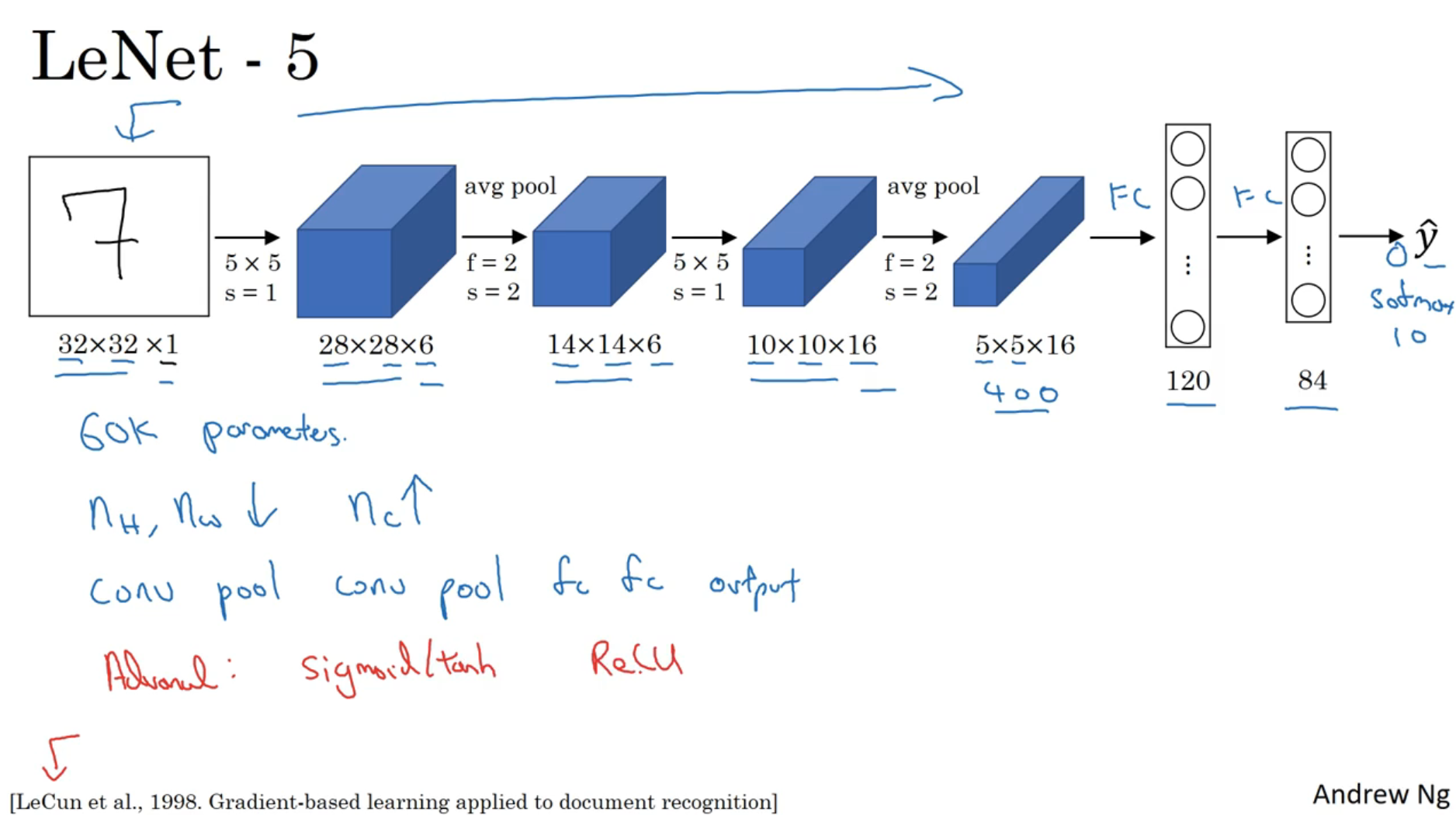
LeNet-5的结构为conv-avg pool-conv-avg pool-fc-fc-分类器
- 上图中没有画出最后一个池化层输出的结果展开为400维向量的过程
- LeNet-5论文中使用的分类器现在已经不用,现在用softmax层来替代
- 产生了60k个参数,而现在的神经网络中可能会有上亿个参数
- LeNet-5论文中用了sigmoid/tanh非线性函数,现在一般用ReLU非线性函数
- 能看到在神经网络中,图像的宽度和高度逐渐变小,而通道数逐渐增加
AlexNet
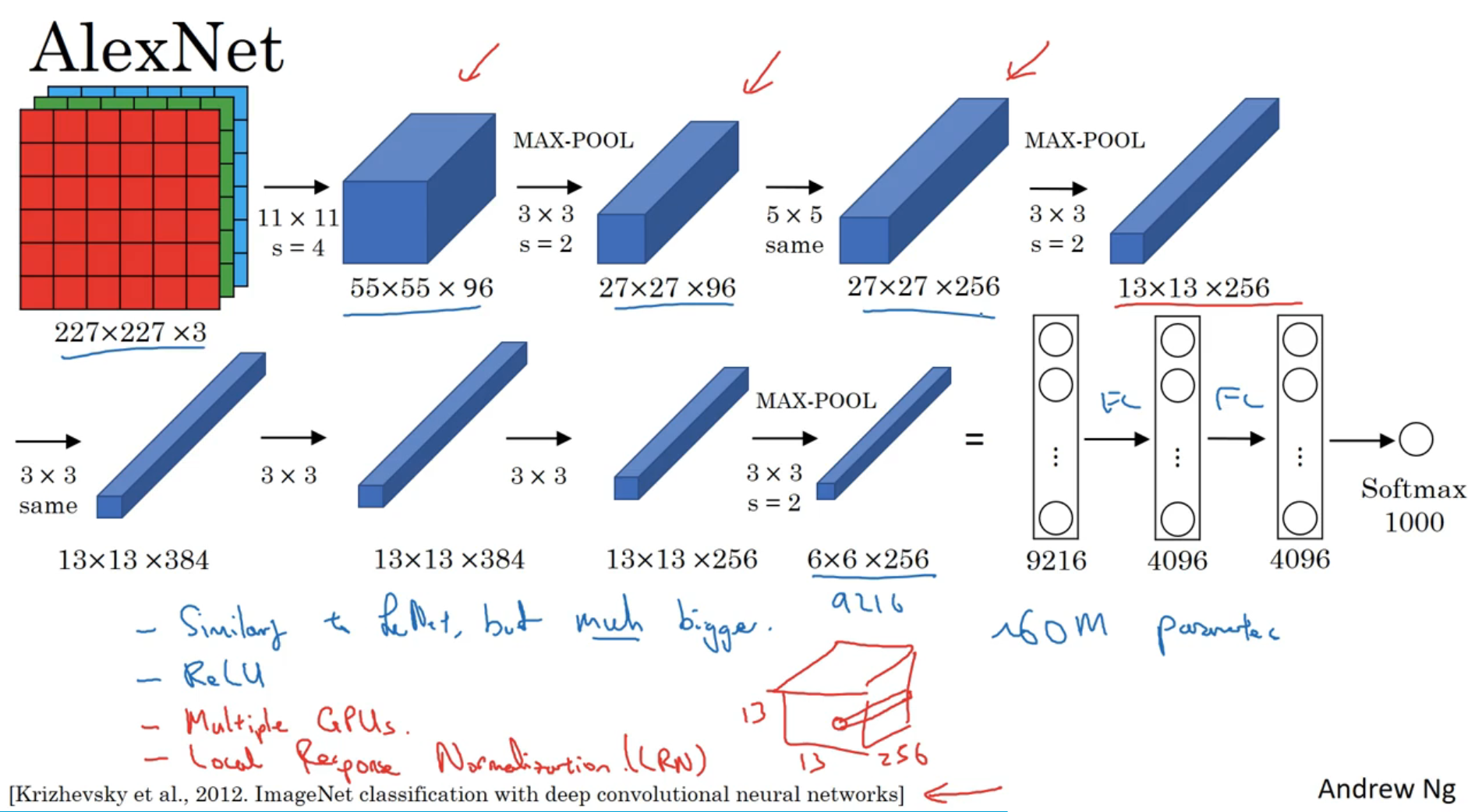
AlexNet的结构为conv-max pool-conv-max pool-conv-conv-conv-max pool-fc-fc-softmax
(上图中的same指的是使用same padding)
- AlexNet用Softmax输出结果
- AlexNet使用ReLU非线性函数
- 有60M个参数
- 由于当时的GPU性能不足,使用了较复杂的算法:将算法交给了2个GPU处理
- 原始的AlexNet还是用了局部响应归一层(LRN),现在不常用
VGG-16
“16”表示该网络中有16层是带权重的,现在也有VGG-19,但一般用VGG-16
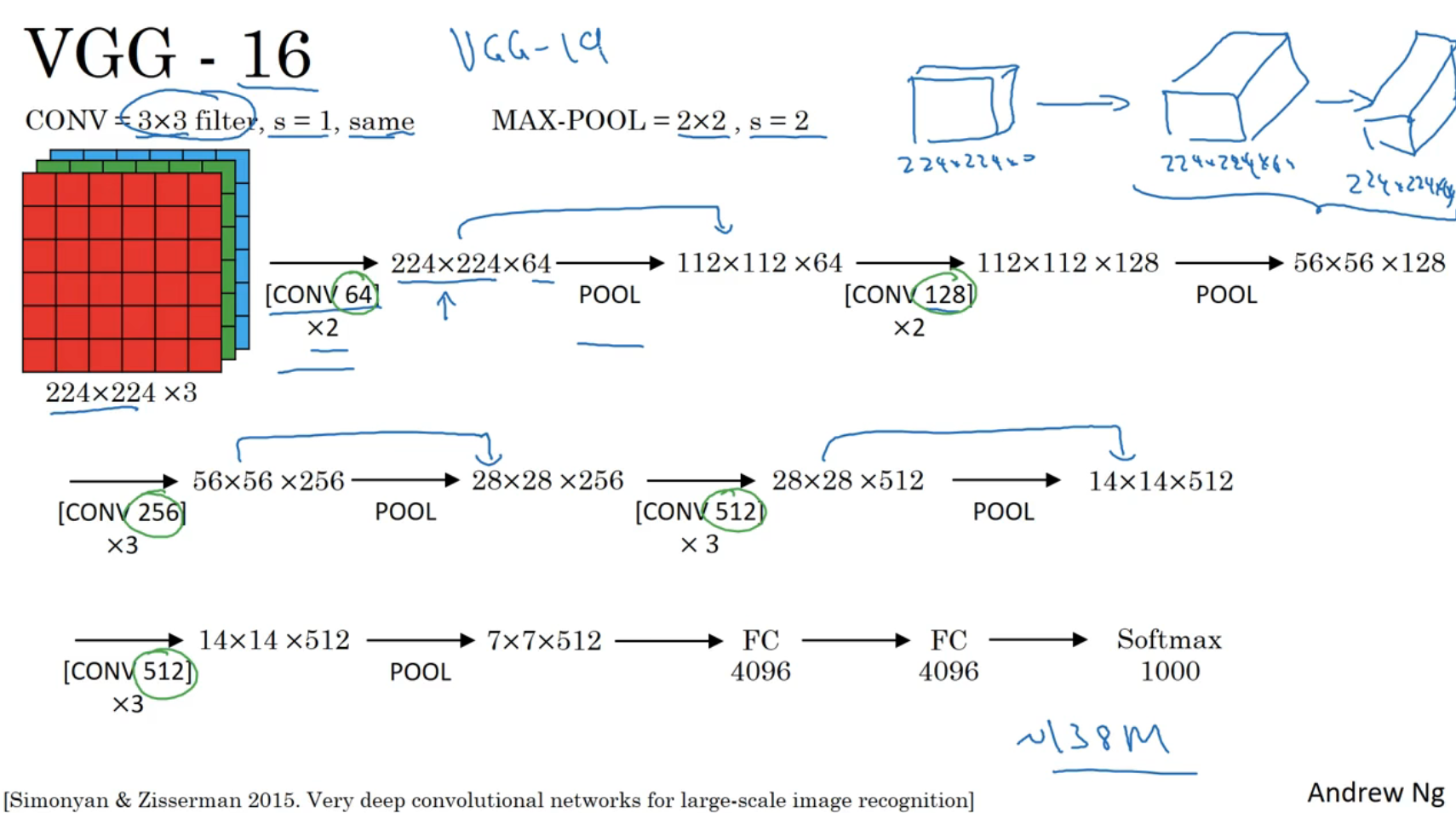
VGG-16的组成如上
- 卷积核是固定的3×3,s=1
- max-pool也是固定的2×2,s=2
- [ CONV 64 ] × 2 \begin{array}{c} {[\text { CONV } 64]} \\ \times 2 \end{array} [ CONV 64]×2表示以64个卷积核进行两次卷积
- 池化层均是max pool
2-3 残差网络(ResNet)

残差网络由残差结构(Residual block)组成
- 如上图,有 l l l、 l + 1 l+1 l+1、 l + 2 l+2 l+2三层神经网络
- 本来由 a [ l ] a^{[l]} a[l]到 a [ l + 2 ] a^{[l+2]} a[l+2]的计算过程为 z [ l + 1 ] = W [ l + 1 ] a [ l ] + b [ l + 1 ] a [ l + 1 ] = g ( z [ l + 1 ] ) z [ l + 2 ] = W [ l + 2 ] a [ l + 1 ] + b [ l + 2 ] a [ l + 2 ] = g ( z [ l + 2 ] ) \begin{array}{c} z^{[l+1]}=W^{[l+1]} a^{[l]}+b^{[l+1]} \\ a^{[l+1]}=g\left(z^{[l+1]}\right)\\ z^{[l+2]}=W^{[l+2]} a^{[l+1]}+b^{[l+2]}\\ a^{[l+2]}=g\left(z^{[l+2]}\right)\\ \end{array} z[l+1]=W[l+1]a[l]+b[l+1]a[l+1]=g(z[l+1])z[l+2]=W[l+2]a[l+1]+b[l+2]a[l+2]=g(z[l+2])
- 用流程来表示就是上图中划绿线部分的内容
- 残差结构是将 a [ l ] a^{[l]} a[l]也代入到第二步的ReLU中计算(称为跳跃连接skip connection),使 a [ l + 2 ] a^{ [l+2]} a[l+2]的激活单元除了与第 l + 2 l+2 l+2层的 z z z相关,还与第 l l l层的 a a a相关
- 在残差结构中由 a [ l ] a^{[l]} a[l]到 a [ l + 2 ] a^{[l+2]} a[l+2]的计算过程变为 z [ l + 1 ] = W [ l + 1 ] a [ l ] + b [ l + 1 ] a [ l + 1 ] = g ( z [ l + 1 ] ) z [ l + 2 ] = W [ l + 2 ] a [ l + 1 ] + b [ l + 2 ] a [ l + 2 ] = g ( z [ l + 2 ] + a [ l ] ) \begin{array}{c} z^{[l+1]}=W^{[l+1]} a^{[l]}+b^{[l+1]} \\ a^{[l+1]}=g\left(z^{[l+1]}\right)\\ z^{[l+2]}=W^{[l+2]} a^{[l+1]}+b^{[l+2]}\\ a^{[l+2]}=g\left(z^{[l+2]}+a^{[l]}\right)\\ \end{array} z[l+1]=W[l+1]a[l]+b[l+1]a[l+1]=g(z[l+1])z[l+2]=W[l+2]a[l+1]+b[l+2]a[l+2]=g(z[l+2]+a[l])

- 没有残差结构的神经网络称为普通网络(plain network),上图是一个残差网络
- 每两层称为一个残差块(上图有5个残差块)
- 如果用普通网络,如上图左侧坐标系,理论上训练误差会像绿色曲线一样逐渐下降,而实际上会如左侧蓝色线一样先下降再上升
- 如果用残差网络,如上图右侧坐标系,训练误差会逐渐下降
2-4 为什么使用残差网络

即便函数是一个恒等函数,残差网络也能够输出恒等函数(即便多了一个残差块)
如果
a
[
l
+
2
]
a^{[l+2]}
a[l+2]是一个256维矩阵,而
a
[
l
]
a^{[l]}
a[l]是一个128维矩阵,则可以对
a
[
l
]
a^{[l]}
a[l]左乘一个256×128的矩阵
W
s
W_s
Ws,它可以是通过学习得到的,也可以直接用0来补全
a
[
l
]
a^{[l]}
a[l]成256维
2-5 网络中的网络及1×1卷积

用一个一维的输入和一维的1×1卷积核来计算看起来没什么意义
但如果用32维的,他本质上就是一个全连接的神经网络
当然,这里也可以运用多个卷积核来生成一个6×6×#filters的结果矩阵
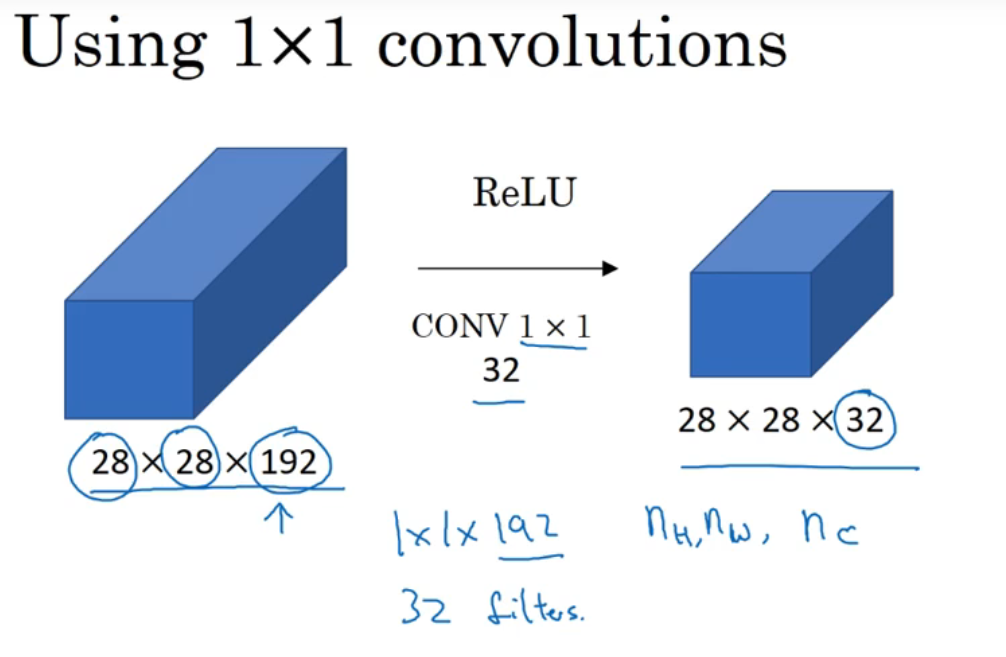
运用池化层可以让矩阵的高、宽减小,而运用1×1卷积核可以让矩阵的通道数减少,如上图
- 运用32个1×1×192的卷积核可以让原来的28×28×192变成28×28×32,(卷积核个数决定了输出矩阵的通道数,卷积核的通道数要与输入矩阵的通道数相等)
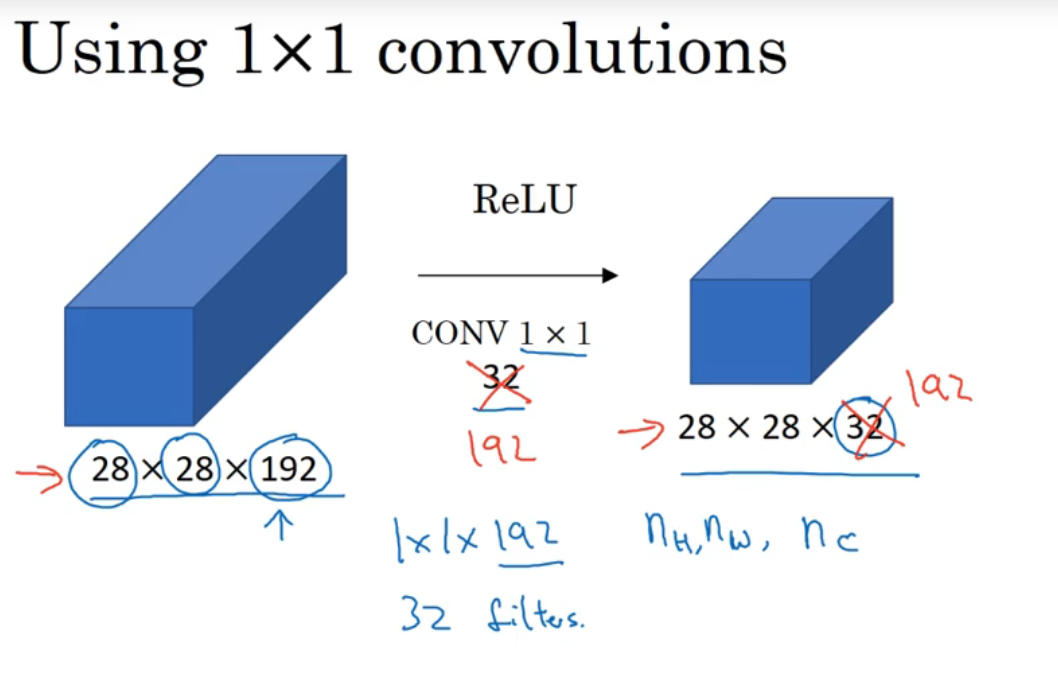
当然也可以运用192个1×1×192的卷积核使得输出矩阵与输入矩阵的高、宽、通道数相同,这样可以增加函数的非线性,使得神经网络能学习到更复杂的函数
2-6 初始网络(Inception network) motivation
如果不想决定用几乘几的过滤器,那就用inception网络
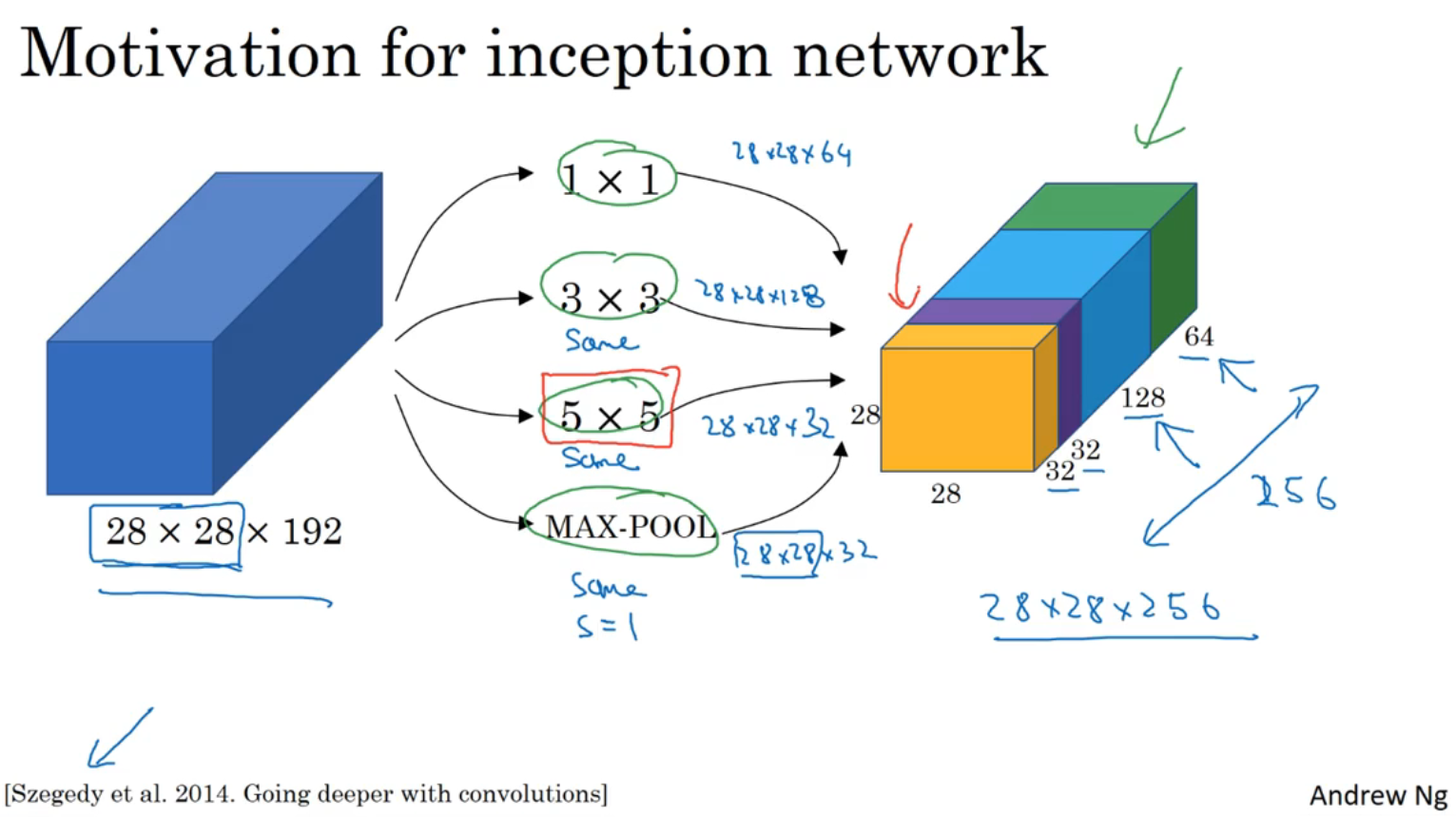
如上图
(绿色)用1×1过滤器生成的28×28×64矩阵
(蓝色)用3×3过滤器(same padding)生成的28×28×128矩阵
(紫色)用5×5过滤器(same padding)生成的28×28×32矩阵
(黄色)用max pool(same padding,s=1)生成的28×28×32矩阵
上述四个矩阵拼成一个28×28×256的矩阵
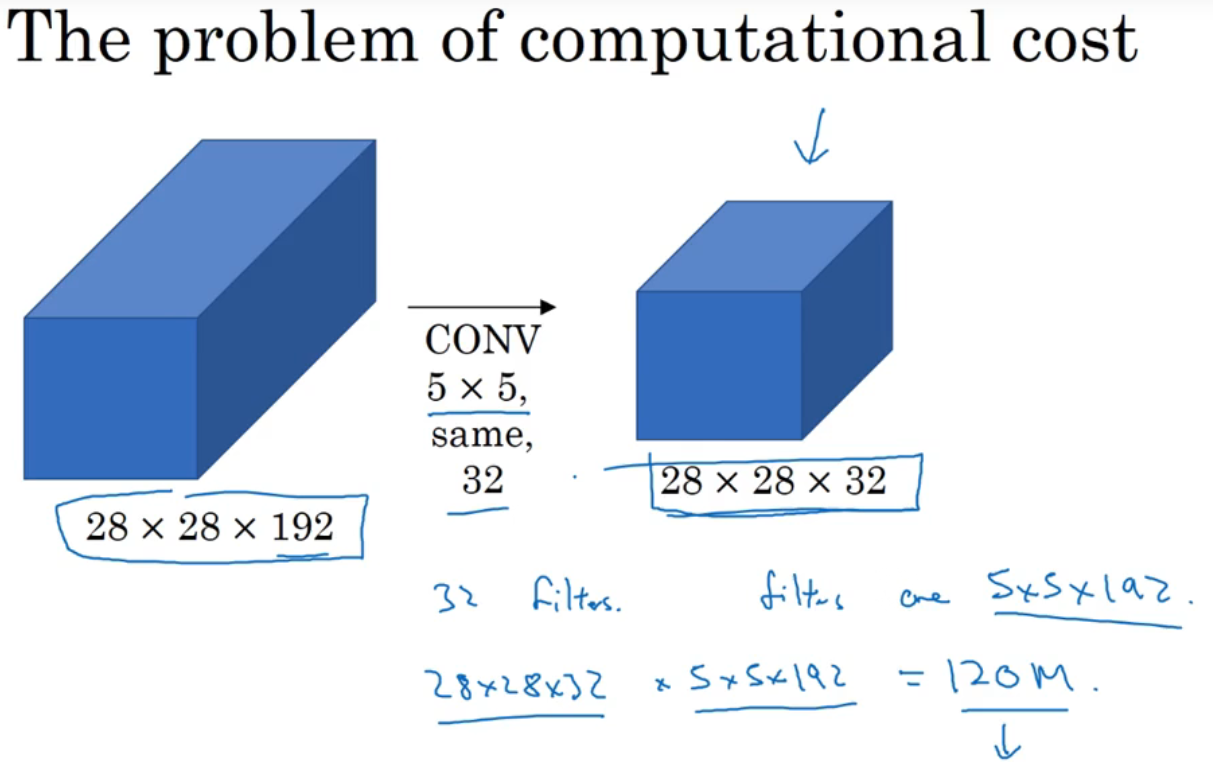
这里以用5×5过滤器时为例,一共要用32个过滤器
按照这样的方法卷积,一共要计算1.2亿次
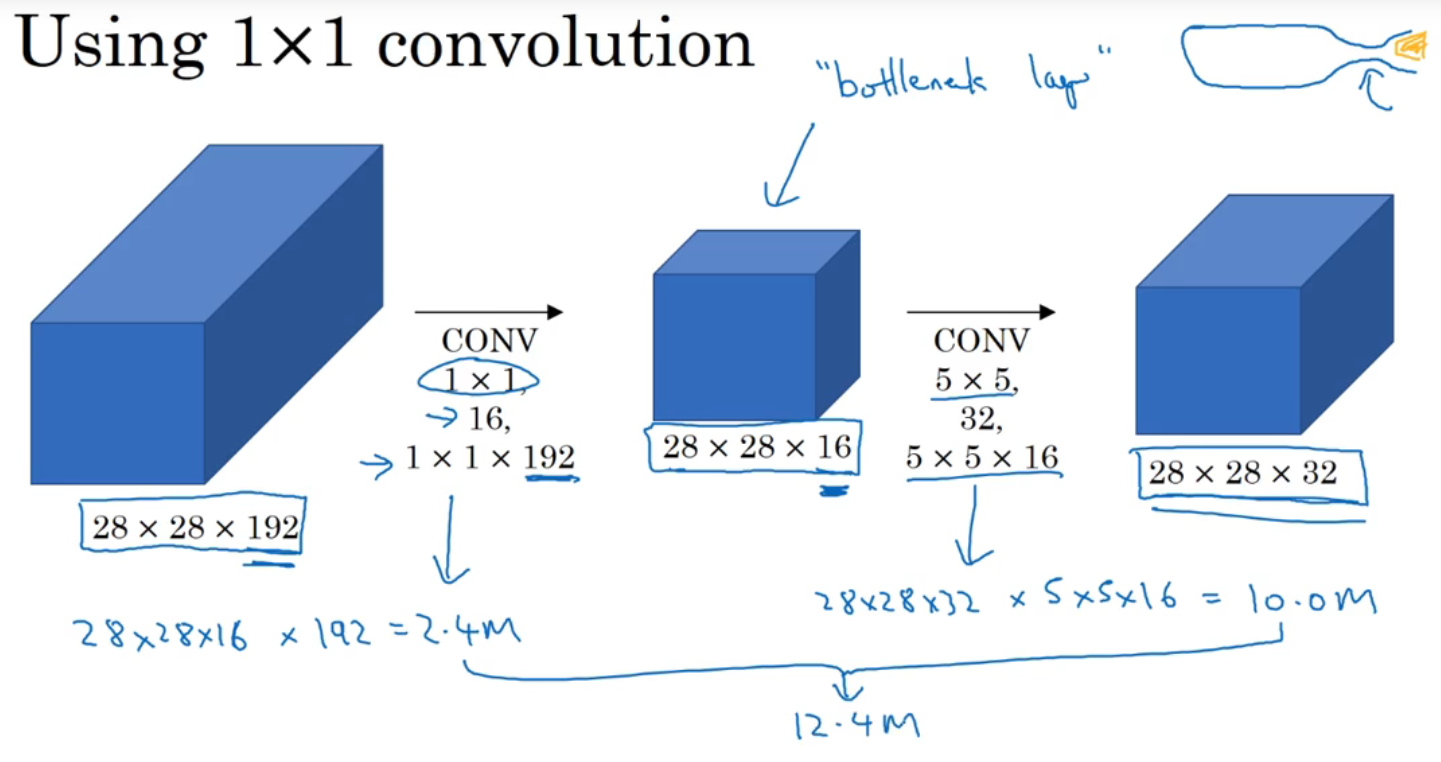
还是以用5×5过滤器时为例,这里在中间插入了1×1卷积核
先用16个1×1×192的卷积核对原矩阵处理,使通道数减小为16个,(这一层被称为瓶颈层),然后再进行5×5过滤器的计算,输出的结果同样是28×28×32,但这样计算量由之前的1.2亿次减少到了1240万
2-7 初始网络(Inception network)
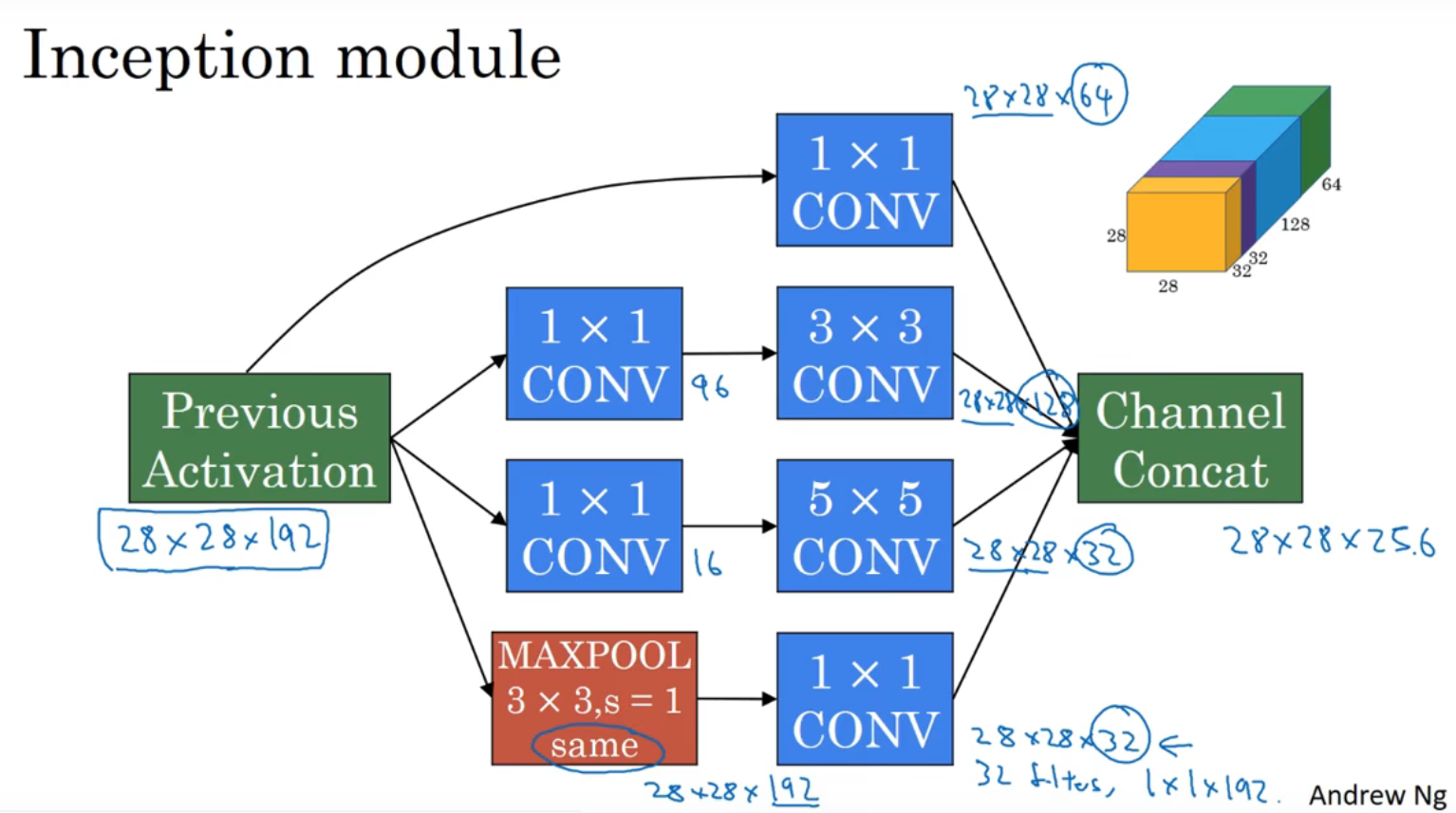
Inception网络的流程如上图
maxpool由于计算出来是28×28×192的矩阵,所以用32个1×1卷积核使输出矩阵变为28×28×32,最后所有计算出来的矩阵拼起来

一个Inception网络如上图,是由很多个Inception模块拼接而成的
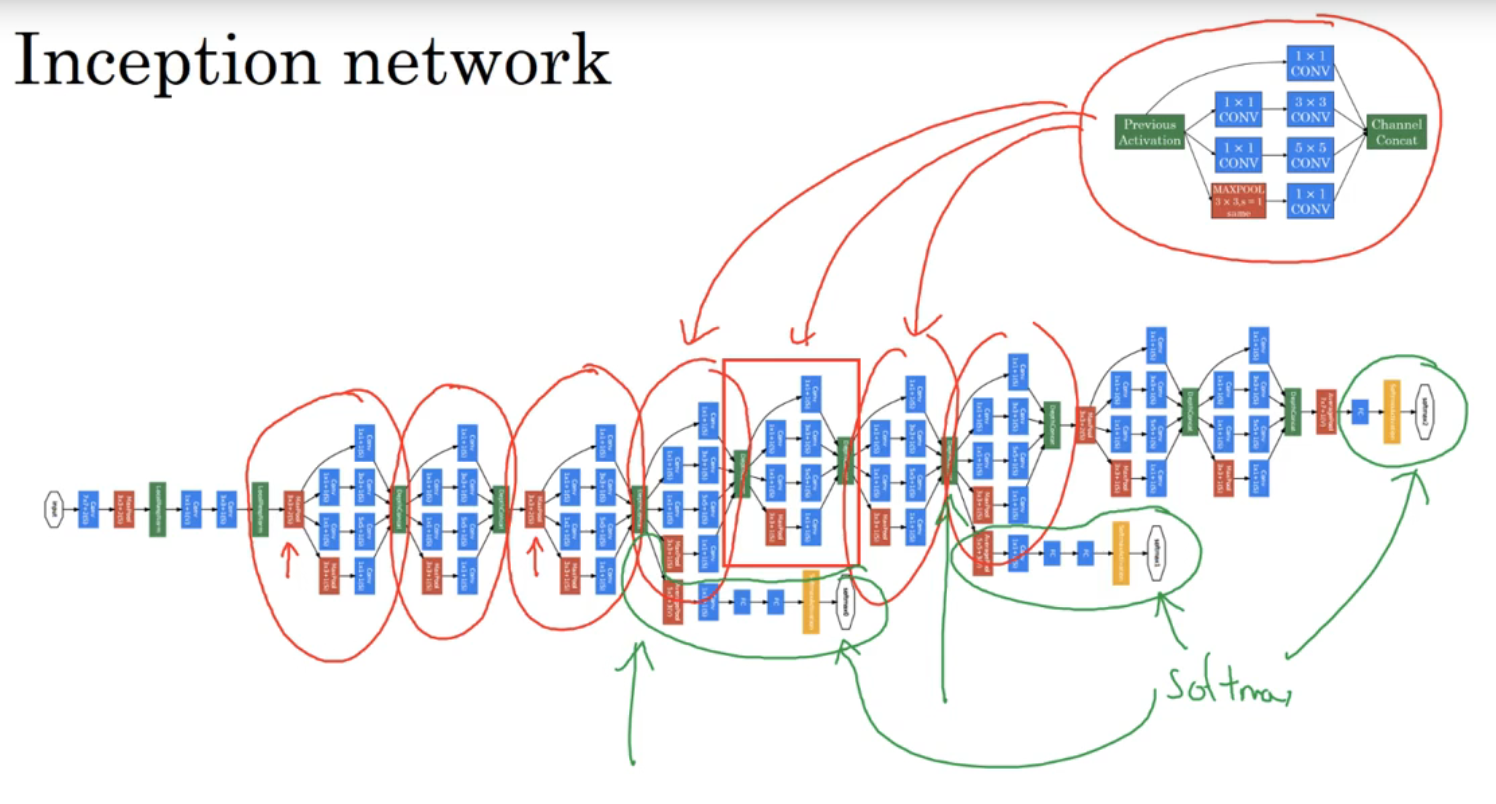
在隐藏层中,有一些softmax的输出分支,这些分支与最后的输出模块是一样的,他的作用是输出隐藏层中的结果,用来保证神经网络不会过拟合
(上图的这个网络被称为GooLenet)
2-8 MobileNet
主要用于低计算能力的处理器,比如手机
工作原理:深度可分离卷积
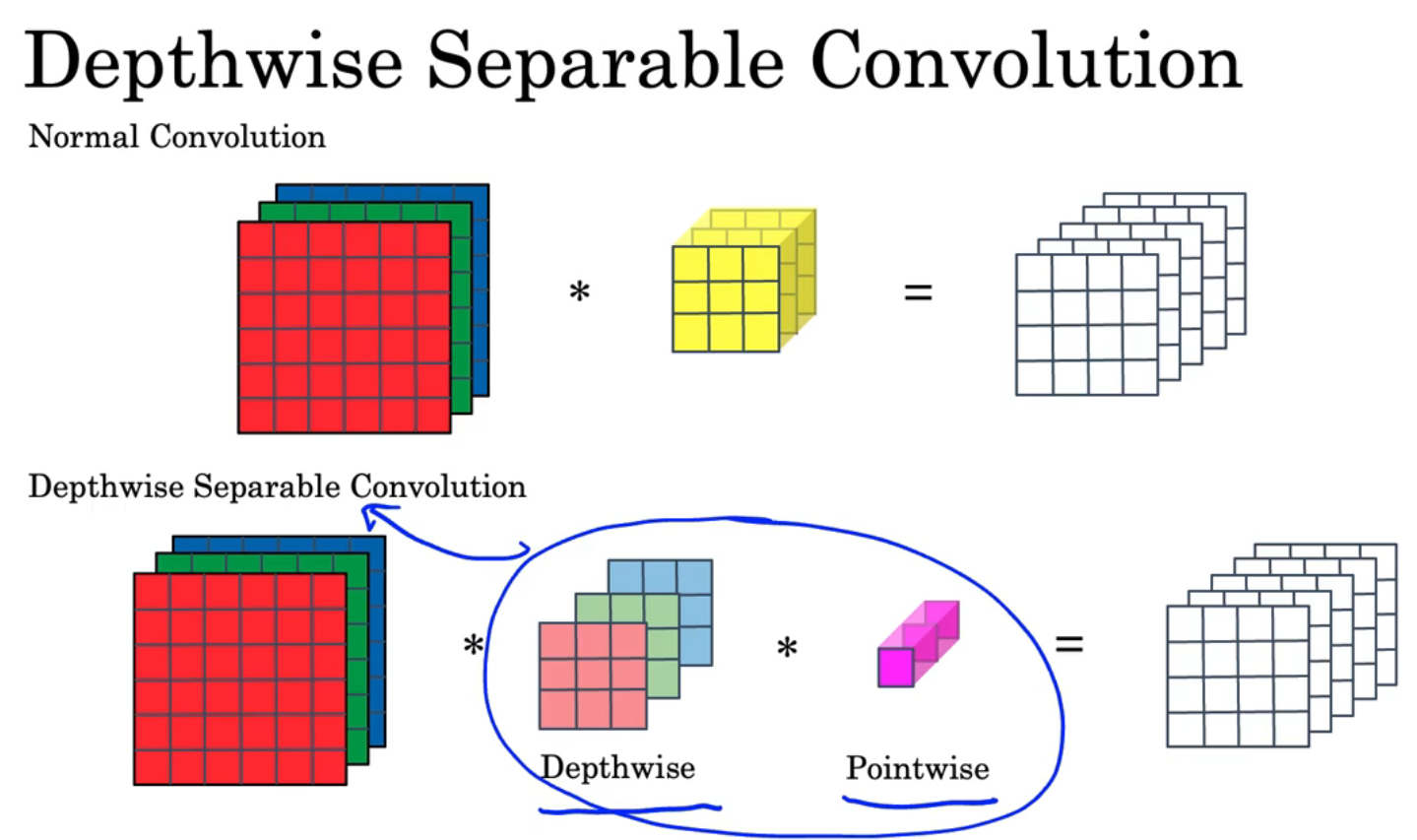
深度可分离卷积分为两个步骤:深度卷积(Depthwise)和逐点卷积(Pointwise)
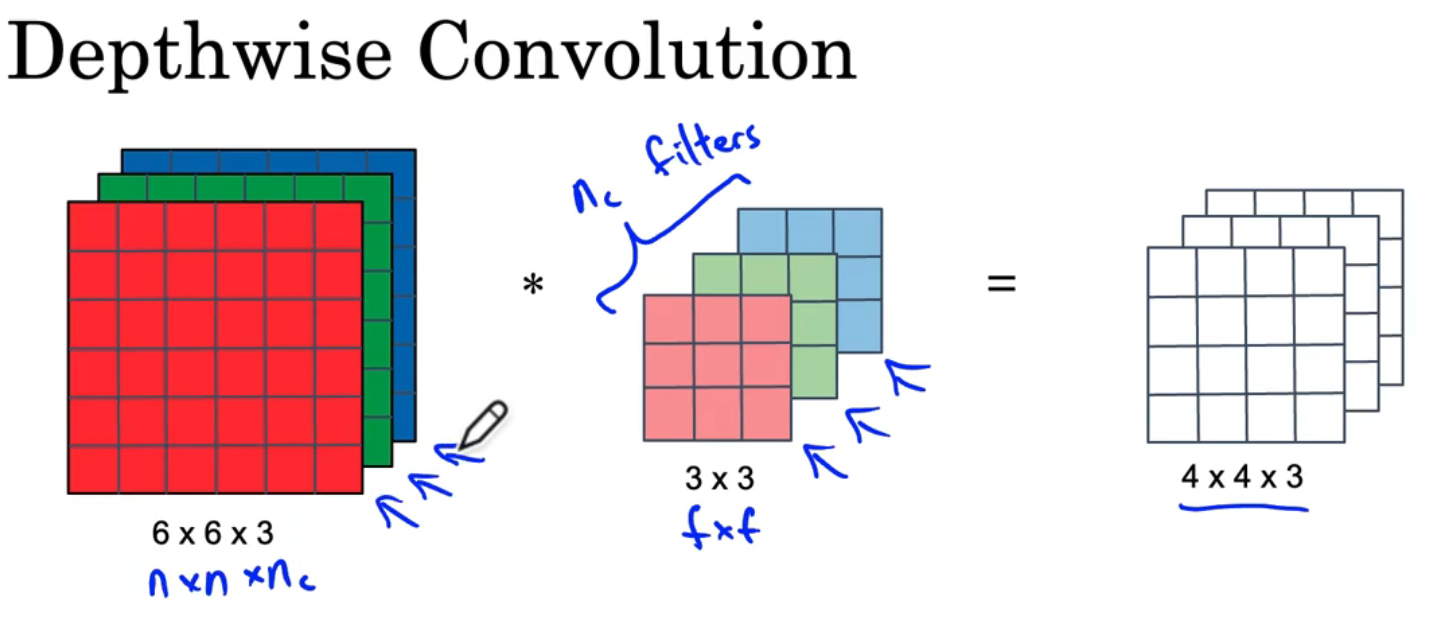
深度卷积↑
- 卷积核每一层对应原矩阵的一层分别作卷积运算(在上图的例子里相当于共有3个一层的卷积核分别参与了运算),原矩阵为 n × n × n c n\times n\times n_c n×n×nc,滤波器为 f × f × n c f\times f\times n_c f×f×nc,最后得到的结果为 ? × ? × n c ?\times ?\times n_c ?×?×nc,(问号部分可以通过之前的公式算出,这里略写)

逐点卷积↑
- 从左上角开始,进行卷积计算,比如结果矩阵的第一行第一列为输入矩阵的第一行第一列的每一层乘上卷积核的每一层再相加(上图的例子是三个数相加)
- 输入矩阵为 n o u t × n o u t × n c n_{out}\times n_{out}\times n_c nout×nout×nc,卷积核为 1 × 1 × n c 1\times 1\times n_c 1×1×nc,输出的矩阵为 n o u t × n o u t × 1 n_{out}\times n_{out}\times 1 nout×nout×1
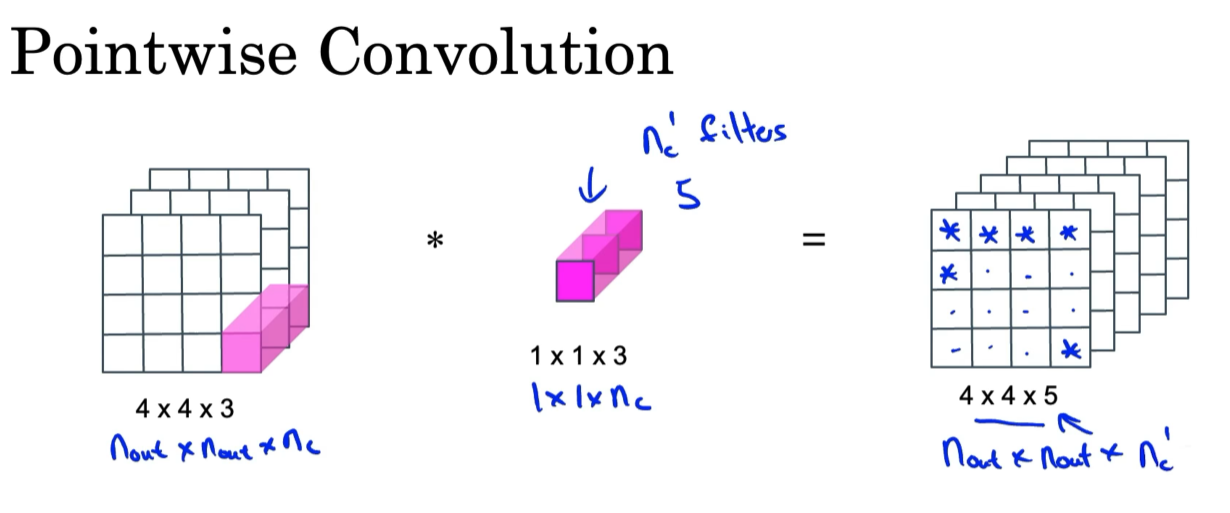
用
n
c
′
n_c^{\prime}
nc′来表示用的卷积核的数量,(上图
n
c
′
=
5
n_c^{\prime}=5
nc′=5),那么输出矩阵就是
n
o
u
t
×
n
o
u
t
×
n
c
′
n_{out}\times n_{out}\times n_c^{\prime}
nout×nout×nc′
深度可分离卷积后得到的矩阵维度与普通卷积是一样的,但运算次数减少很多
深度可分离卷积的运算次数为普通卷积次数的
1
n
c
′
+
1
f
2
\frac{1}{n_{c}^{\prime}}+\frac{1}{f^{2}}
nc′1+f21
2-9 MobileNet架构

上一节是MobileNet v1,上图下半部分是MobileNet v2,
v2增加了残差连接(跳跃连接),并且由(扩展层+深度卷积+投射)组成,这也被称为瓶颈层,投射与逐点卷积的操作相同,只是命名不同
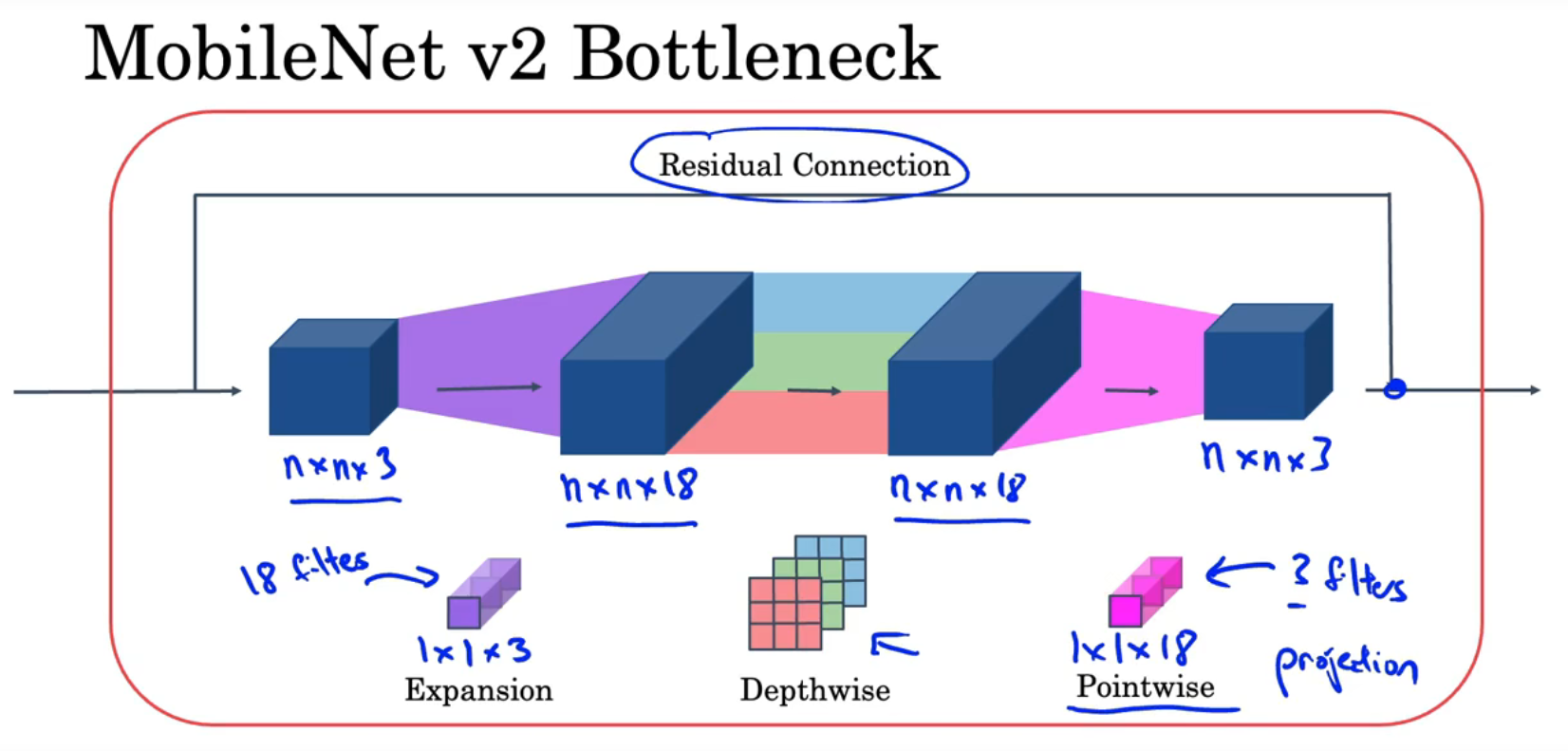
以上图为例,输入的矩阵经过残差连接直接传到最后,另外,
n
×
n
×
3
n\times n\times 3
n×n×3的输入矩阵经过18个
1
×
1
×
3
1\times 1\times 3
1×1×3的卷积核变为
n
×
n
×
18
n\times n\times 18
n×n×18,然后经过深度卷积、逐点卷积得到最后的结果
2-9 EfficientNet
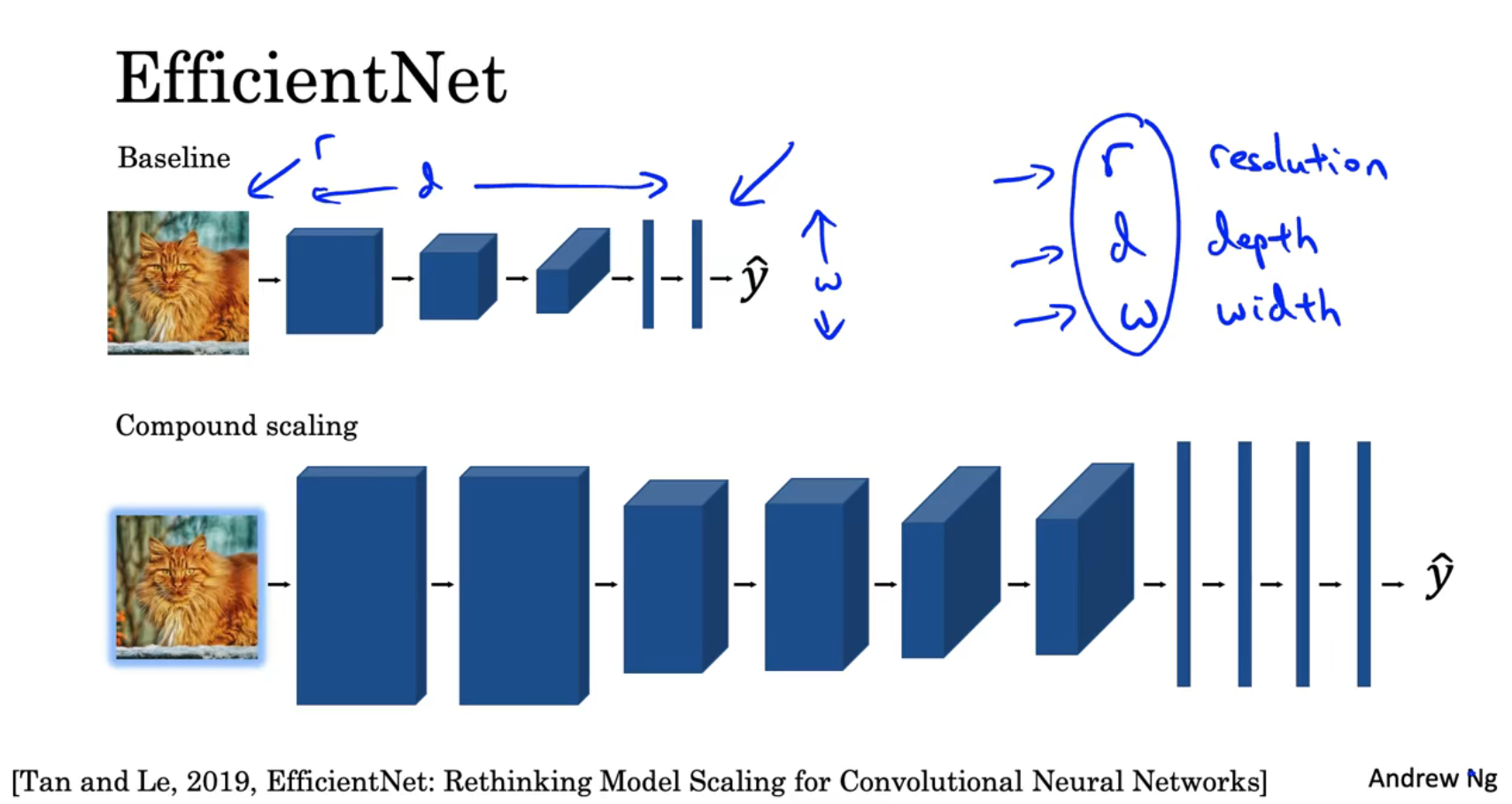
通过改变神经网络的深度(depth)、宽度(width)和分辨率(resolution)可以改变神经网络的运行效率和效果
深度——神经网络的层数
宽度——每层的通道数
分辨率——是指网络中特征图的分辨率
神经网络的深度、宽度和分辨率_CSDN博客
运用EfficientNet可以自动确定以上参数之间的最佳组合
2-10 使用ConvNets的实用建议:使用开放源码
GitHub
2-11 使用ConvNets的实用建议:迁移学习
如果不想从随机初始化开始训练神经网络,可以用已经训练好的开源的权重来应用到自己的项目中
已经训练好的开源数据库有ImageNet、MS COCO、PASCAL等
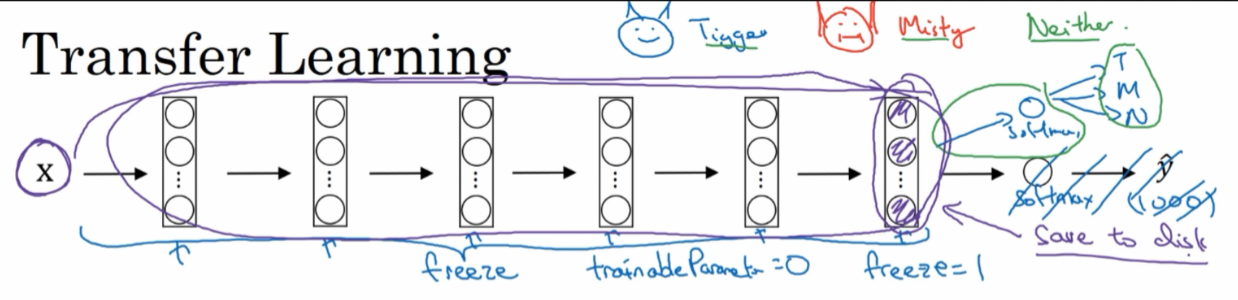
以识别猫是Tigger还是Misty还是其他猫为例,如果你对猫Tigger和猫Misty的数据集太少,你可以这样做:
用一个训练好的猫分类器,冻结他的参数,然后重新训练他的softmax
这样,输入的猫图像直接套用一个训练好的固定的函数输出它的特征值,然后再用自己的softmax训练,就能对猫是Tigger还是Misty还是其他猫作出判断

如果你拥有比较多的猫Tigger和猫Misty的数据集,你可以少冻结几层神经网络,比如上图的冻结前面的4层,训练后面两层和softmax,(当然也可以把后面的神经网络替换为自己的神经元),把前4层输出的参数值作为自己的神经网络的初始值,然后训练
2-12 使用ConvNets的实用建议:数据增强
用于解决计算机视觉中数据集不足的问题
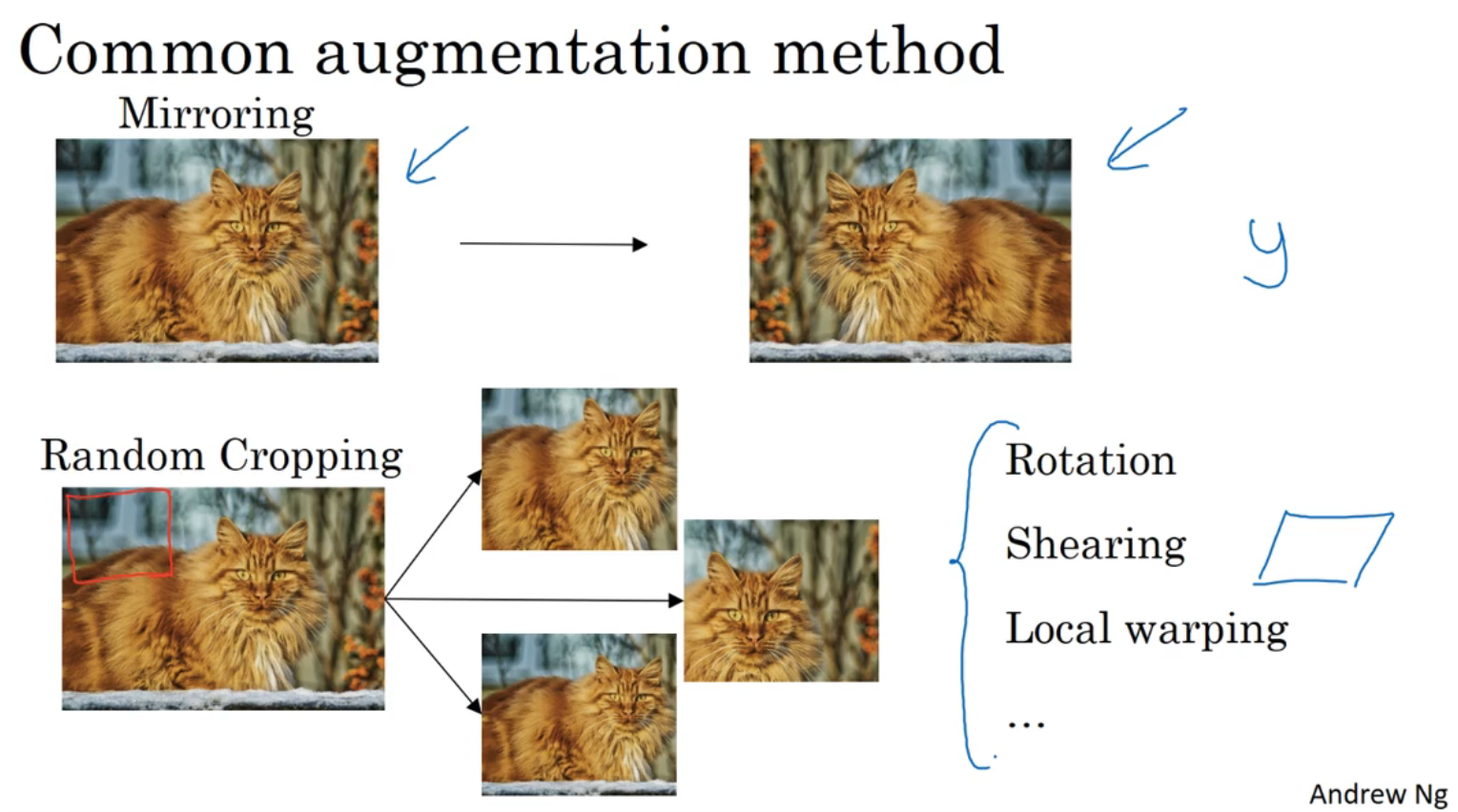
使用镜像、随机裁剪、旋转、剪切变换、局部弯曲等

使用色彩变换:对R、G、B通道添加一定的扰动,使颜色发生改变
色彩变换可以用PCA主成分分析算法
2-12 使用ConvNets的实用建议:计算机视觉状态
可以用对多个神经网络预测出的值求平均值的方法提高准确性

也可以用多重剪切:对一张图片取中心部分剪切(如上图最左侧的猫上面覆盖的蓝色区域就是剪切的区域)、取左上角剪切(用稍微小一些的长方形贴住图片左上角进行剪切)、取右上角剪切、取左下角剪切、取右下角剪切,然后输入到神经网络中,取预测值的平均值作为最后输出结果
在构建产品时,不建议用以上两种方法,尽管他们在竞赛和论文中表现不错

















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











