







对联邦学习中的数据集non-iid问题,这篇文章提出采用联合关注消息传递的新方法,促进类似客户进行更多协作。它允许每个用户拥有不同的模型,所以属于个性化联邦学习。
-
首先明确优化目标
优化目标由两部分组成,第一部分是所有用户模型训练损失之和,第二部分是通过注意力函数提升用户间的合作效率,其衡量了两个模型参数的差异。
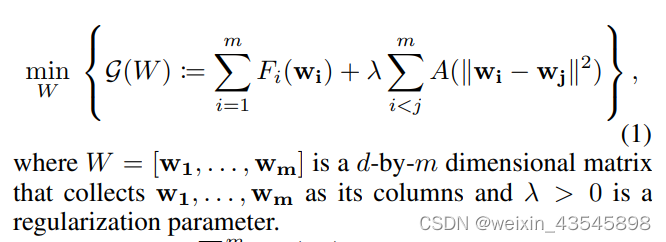
-
怎么满足这个优化目标?
在第k个iteration,利用梯度下降步骤(下图第一个式(3))计算中间矩阵 U k U^k Uk优化注意力函数,并且通过最优化下图中式(4)优化所有用户模型训练损失之和,这个过程重复直到达到最大循环数。

通过在云服务器上为每个客户端维护一个个性化的云模型,并在个性化模型和个性化云模型之间传递加权模型聚合消息,在客户端-服务器框架中实现通用方法的优化步骤。
首先求
U
k
U^k
Uk,写成线性形式,表示通过接收到的所有消息的加权凸组合来更新每个客户端的个性化云模型。其中
ϵ
\epsilon
ϵ是各个模型参数的权重,权和为1,各个
w
w
w就是其他模型聚合的信息。计算好
U
k
U^k
Uk后就能正常优化
F
(
W
)
F(W)
F(W)了。
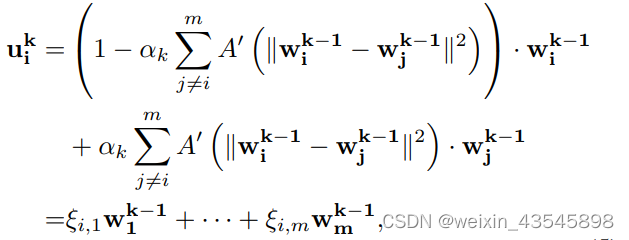
3. 有一个关键是各个模型参数的权重怎么算出来?
就是下图这个式子,其中的
α
\alpha
α是学习率,A’(*)是衡量两个模型参数相似度的函数,当他们的 Euclidean距离小时,相似度就高。也即是说,相似度高的权重越大。

值得注意的是,此方法在用户很多时通信与计算开销大,所以作者强调了Cross-Silo。














 1210
1210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









