









【Ultralytics YOLO11 】不分析论文,只看源码,从环境配置到训练、检验、预测模型及数据集YOLO化
一、引言
麻将识别在多种应用场景中具有重要价值,如游戏辅助、文化研究等。计算机视觉技术,特别是目标检测算法,为实现自动麻将识别提供了可能。
二、数据集准备
(一)数据集来源
使用 Camerash/mahjong-dataset 数据集。
(二)数据集结构
- 原始未分割图像:
./raw-images - 未缩放的麻将牌图像:
./raw-tiles - 缩放后的图像:
./tiles-resized - 标注数据:
./tiles-data - 未标注的图像:
./untagged-images-raw和./untagged-tiles
(三)数据集特点
- 图像主要从 Google 图像搜索、Ebay 和 Alibaba 收集。
- 缩放后的图像尺寸为 240x320 像素,格式为 .jpg。
- 提供
train.zip文件,包含images文件夹和data.csv标注文件。
三、数据预处理
(一)标注格式转换
将标注信息从原始格式转换为 YOLO 格式。
(二)代码实现
我不需要花牌部分,提取出了剩余部分
import os
import shutil
import pandas as pd
# 设置文件夹路径
train_folder = r"E:\Downloads\mahjong-dataset-master\train"
images_folder = os.path.join(train_folder, "images")
output_folder = os.path.join(train_folder, "filtered_images")
# 创建输出文件夹(如果不存在)
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 加载 data.csv 文件
data_csv = os.path.join(train_folder, "data.csv")
data = pd.read_csv(data_csv)
# 定义花牌的类别索引
bonus_tiles = [35, 36, 37, 38, 39, 40, 41, 42]
# 筛选出非花牌的行
filtered_data = data[~data['label'].isin(bonus_tiles)]
# 将筛选后的数据保存到新的 CSV 文件中
filtered_csv = os.path.join(train_folder, "filtered_data.csv")
filtered_data.to_csv(filtered_csv, index=False)
# 复制对应的图像文件到新的文件夹
for image_name in filtered_data['image-name']:
source_image_path = os.path.join(images_folder, image_name)
target_image_path = os.path.join(output_folder, image_name)
if os.path.exists(source_image_path):
shutil.copy(source_image_path, target_image_path)
else:
print(f"Image not found: {source_image_path}")
print("完成筛选和复制操作!")
import os
import pandas as pd
# 设置文件夹路径
train_folder = r"E:\Downloads\mahjong-dataset-master\train"
images_folder = os.path.join(train_folder, "images")
output_folder = os.path.join(train_folder, "labels")
# 创建输出文件夹(如果不存在)
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 加载 data.csv 文件
data_csv = os.path.join(train_folder, "data.csv")
data = pd.read_csv(data_csv)
# 定义花牌的类别索引
bonus_tiles = [35, 36, 37, 38, 39, 40, 41, 42]
# 筛选出非花牌的行
filtered_data = data[~data['label'].isin(bonus_tiles)]
# 遍历筛选后的数据,生成 YOLO 格式的标注文件
for index, row in filtered_data.iterrows():
image_name = row['image-name']
label = row['label'] - 1 # YOLO 的类别索引从 0 开始
label_name = row['label-name']
# 假设目标框占据整个图像
# YOLO 格式的标注信息:类别索引 <x_center> <y_center> <width> <height>
# 坐标和尺寸归一化到 [0, 1] 范围内
yolo_label_file = os.path.join(output_folder, os.path.splitext(image_name)[0] + '.txt')
# 写入 YOLO 格式的标注信息
with open(yolo_label_file, 'w') as f:
f.write(f"{label} 0.5 0.5 1.0 1.0\n") # 目标框占据整个图像
print("完成 YOLO 格式转换!")
(三)划分训练集和验证集
将数据集划分为训练集和验证集。
import os
import shutil
from sklearn.model_selection import train_test_split
# 设置文件夹路径
filtered_images_folder = r"E:\Downloads\mahjong-dataset-master\train\filtered_images"
labels_folder = r"E:\Downloads\mahjong-dataset-master\train\labels"
dataset_folder = r"E:\Downloads\mahjong-dataset-master\dataset"
# 创建 dataset 文件夹及其子文件夹
os.makedirs(os.path.join(dataset_folder, "images", "train"), exist_ok=True)
os.makedirs(os.path.join(dataset_folder, "images", "val"), exist_ok=True)
os.makedirs(os.path.join(dataset_folder, "labels", "train"), exist_ok=True)
os.makedirs(os.path.join(dataset_folder, "labels", "val"), exist_ok=True)
# 获取所有图像文件名
image_files = [f for f in os.listdir(filtered_images_folder) if f.endswith('.jpg')]
# 划分训练集和验证集(80% 训练,20% 验证)
train_images, val_images = train_test_split(image_files, test_size=0.2, random_state=42)
# 复制图像和标注文件到对应的训练集和验证集文件夹
def copy_files(file_list, source_folder, target_images_folder, target_labels_folder):
for file_name in file_list:
# 复制图像文件
source_image_path = os.path.join(source_folder, file_name)
target_image_path = os.path.join(target_images_folder, file_name)
shutil.copy(str(source_image_path), str(target_image_path))
# 复制对应的标注文件
label_file_name = os.path.splitext(file_name)[0] + '.txt'
source_label_path = os.path.join(labels_folder, label_file_name)
target_label_path = os.path.join(target_labels_folder, label_file_name)
shutil.copy(str(source_label_path), str(target_label_path))
# 复制训练集文件
copy_files(train_images, filtered_images_folder,
os.path.join(dataset_folder, "images", "train"),
os.path.join(dataset_folder, "labels", "train"))
# 复制验证集文件
copy_files(val_images, filtered_images_folder,
os.path.join(dataset_folder, "images", "val"),
os.path.join(dataset_folder, "labels", "val"))
print("数据集划分完成!")
四、数据增强
(一)拼接图像
通过随机选择图像并将其放置在大画布上,生成新的训练样本。
(二)重叠检测
计算边界框的交并比(IoU),确保放置的图像之间重叠面积不超过设定的阈值。
(三)代码实现
import os
import random
from PIL import Image
# 设置路径
image_dir = r"E:\Downloads\mahjong-dataset-master\train\filtered_images"
label_dir = r"E:\Downloads\mahjong-dataset-master\train\labels"
output_image_dir = r"E:\Downloads\mahjong-dataset-master\train\augmented_images"
output_label_dir = r"E:\Downloads\mahjong-dataset-master\train\augmented_labels"
os.makedirs(output_image_dir, exist_ok=True)
os.makedirs(output_label_dir, exist_ok=True)
# 获取所有图像和标注文件
image_files = [os.path.join(image_dir, f) for f in os.listdir(image_dir) if f.endswith('.jpg')]
label_files = [os.path.join(label_dir, f) for f in os.listdir(label_dir) if f.endswith('.txt')]
# 定义拼接图像的大小
canvas_size = (1280, 1280) # 定义画布大小
num_images_to_place = 14 # 每张拼接图像放置的麻将牌数量
overlap_threshold = 0.1 # 重叠面积阈值(0.1 表示重叠面积不超过 10%)
max_attempts = 50 # 最大尝试次数
def compute_iou(box1, box2):
"""计算两个边界框的交并比(IoU)"""
x1, y1, w1, h1 = box1
x2, y2, w2, h2 = box2
# 计算交集区域
inter_x1 = max(x1, x2)
inter_y1 = max(y1, y2)
inter_x2 = min(x1 + w1, x2 + w2)
inter_y2 = min(y1 + h1, y2 + h2)
inter_area = max(0, inter_x2 - inter_x1) * max(0, inter_y2 - inter_y1)
# 计算并集区域
area1 = w1 * h1
area2 = w2 * h2
union_area = area1 + area2 - inter_area
return inter_area / union_area if union_area != 0 else 0
def place_image(canvas, image, position, placed_boxes):
"""将图像放置到画布上,并检查重叠情况"""
x, y = position
w, h = image.size
# 检查与已放置的图像的重叠情况
for box in placed_boxes:
iou = compute_iou((x, y, w, h), box)
if iou > overlap_threshold:
return False, placed_boxes # 重叠超过阈值,返回 False
# 如果没有重叠或重叠在允许范围内,则放置图像
# 检查图像是否有透明通道
if image.mode == 'RGBA':
canvas.paste(image, position, image) # 使用透明通道作为遮罩
else:
canvas.paste(image, position) # 不使用遮罩
placed_boxes.append((x, y, w, h))
return True, placed_boxes
# 遍历生成新的拼接图像
for i in range(1280): # 生成100张拼接图像
canvas = Image.new('RGB', canvas_size, (255, 255, 255)) # 创建白色画布
labels = [] # 用于存储YOLO格式的标注信息
placed_boxes = [] # 用于存储已放置的边界框
for _ in range(num_images_to_place):
# 随机选择一张图像和对应的标注文件
image_path = random.choice(image_files)
label_path = os.path.join(label_dir, os.path.basename(image_path).replace('.jpg', '.txt'))
# 加载图像
image = Image.open(image_path).convert('RGB')
# 加载标注文件
with open(label_path, 'r') as f:
label = f.read().strip().split()
class_id = int(label[0]) # 获取类别索引
x_center, y_center, width, height = map(float, label[1:5]) # 获取归一化的标注信息
# 将标注信息转换为像素坐标
x = int((x_center - width / 2) * image.width)
y = int((y_center - height / 2) * image.height)
w = int(width * image.width)
h = int(height * image.height)
placed = False
attempts = 0
while not placed and attempts < max_attempts:
position = (random.randint(0, canvas_size[0] - w),
random.randint(0, canvas_size[1] - h))
placed, placed_boxes = place_image(canvas, image, position, placed_boxes)
attempts += 1
if placed:
# 更新YOLO格式的标注
new_x_center = (position[0] + w / 2) / canvas_size[0]
new_y_center = (position[1] + h / 2) / canvas_size[1]
new_width = w / canvas_size[0]
new_height = h / canvas_size[1]
labels.append(f"{class_id} {new_x_center:.6f} {new_y_center:.6f} {new_width:.6f} {new_height:.6f}")
# 保存拼接后的图像
output_image_path = os.path.join(output_image_dir, f"augmented_{i}.jpg")
canvas.save(output_image_path)
# 保存YOLO格式的标注文件
output_label_path = os.path.join(output_label_dir, f"augmented_{i}.txt")
with open(output_label_path, 'w') as f:
for label in labels:
f.write(label + '\n')
print("数据增强完成,生成的图像和标注文件已保存到", output_image_dir, "和", output_label_dir)
(四)划分训练集和验证集
将增强后的数据集划分为训练集和验证集。
import os
import random
import shutil
images_dir = r"/home/aistudio/ultralytics/dataset/augmented_images"
labels_dir = r"/home/aistudio/ultralytics/dataset/augmented_labels"
train_images_dir = r"/home/aistudio/ultralytics/dataset/mj-dataset/aug-images/train/images"
train_labels_dir = r"/home/aistudio/ultralytics/dataset/mj-dataset/aug-images/train/labels"
val_images_dir = r"/home/aistudio/ultralytics/dataset/mj-dataset/aug-images/val/images"
val_labels_dir = r"/home/aistudio/ultralytics/dataset/mj-dataset/aug-images/val/labels"
os.makedirs(train_images_dir, exist_ok=True)
os.makedirs(train_labels_dir, exist_ok=True)
os.makedirs(val_images_dir, exist_ok=True)
os.makedirs(val_labels_dir, exist_ok=True)
image_files = [f for f in os.listdir(images_dir) if f.endswith('.jpg')]
label_files = [f.replace('.jpg', '.txt') for f in image_files]
train_ratio = 0.8
random.seed(42)
random.shuffle(image_files)
split_index = int(len(image_files) * train_ratio)
train_images = image_files[:split_index]
val_images = image_files[split_index:]
for image_file in train_images:
shutil.copy(os.path.join(images_dir, image_file), os.path.join(train_images_dir, image_file))
label_file = image_file.replace('.jpg', '.txt')
shutil.copy(os.path.join(labels_dir, label_file), os.path.join(train_labels_dir, label_file))
for image_file in val_images:
shutil.copy(os.path.join(images_dir, image_file), os.path.join(val_images_dir, image_file))
label_file = image_file.replace('.jpg', '.txt')
shutil.copy(os.path.join(labels_dir, label_file), os.path.join(val_labels_dir, label_file))
print(f"数据集划分完成,训练集图像数量: {len(train_images)},验证集图像数量: {len(val_images)}")
六、模型训练
(一)使用原数据集训练300轮
使用 YOLOv11 模型进行训练。
from ultralytics import YOLO
import os
if __name__ == '__main__':
# 加载模型配置
model = YOLO('ultralytics/cfg/models/11/yolo11.yaml')
# 构建last.pt文件的路径
last_weights_path = os.path.join('/home/aistudio/ultralytics/', 'yolo11n.pt')
# 加载最后保存的权重(如果有)
model.load(last_weights_path)
# 开始训练模型
results = model.train(
data='/home/aistudio/ultralytics/mj-data.yaml',
epochs=300, # 训练的总轮数
imgsz=640, # 输入图像的大小
cache=False, # 是否缓存数据增强效果
batch=32, # 每批处理的图像数量
device='0', # 指定训练设备,'0'表示使用第一个GPU
single_cls=False, # 是否为单类别检测
optimizer='SGD', # 使用SGD优化器
resume=True, # 从上次训练中断处继续训练
amp=False, # 使用自动混合精度训练
lr0=0.01, # 初始学习率
momentum=0.937, # SGD的动量参数
weight_decay=0.0005, # 权重衰减,L2正则化
close_mosaic=10, # 在前10个epoch不使用mosaic数据增强
save_period=10, # 每10个epoch保存一次模型
workers=8, # 数据加载的工作线程数,根据您的CPU核心数调整
project='mj-train/runs/', # 训练项目的保存路径
)
# 打印训练结果
print(results)
mj-data.yaml
# 数据集路径
train: /home/aistudio/ultralytics/dataset/mj-dataset/images/train
val: /home/aistudio/ultralytics/dataset/mj-dataset/images/val
# 类别数量
nc: 34 # 类别数量(不包括花牌)
# 类别名称(中文)
names: [
'一饼', '二饼', '三饼', '四饼', '五饼', '六饼', '七饼', '八饼', '九饼',
'一条', '二条', '三条', '四条', '五条', '六条', '七条', '八条', '九条',
'一万', '二万', '三万', '四万', '五万', '六万', '七万', '八万', '九万',
'东风', '南风', '西风', '北风', '红中', '发财', '白板'
]
(二)使用数据增强继续训练 300 轮
进行 300 轮训练后,使用数据增强继续训练 300 轮。
from ultralytics import YOLO
import os
if __name__ == '__main__':
model = YOLO('ultralytics/cfg/models/11/yolo11.yaml')
last_weights_path = os.path.join('/home/aistudio/ultralytics/mj-train/runs/train/train/weights/', 'best.pt')
model.load(last_weights_path)
results = model.train(
data='/home/aistudio/ultralytics/aug-mj-data.yaml',
epochs=300,
imgsz=640,
cache=False,
batch=32,
device='0',
single_cls=False,
optimizer='SGD',
resume=True,
amp=False,
lr0=0.01,
momentum=0.937,
weight_decay=0.0005,
close_mosaic=10,
save_period=10,
workers=8,
project='aug-mj-train/runs/',
)
print(results)
aug-mj-data.yaml
# 数据集路径
train: /home/aistudio/ultralytics/dataset/mj-dataset/aug-images/train
val: /home/aistudio/ultralytics/dataset/mj-dataset/aug-images/val
# 类别数量
nc: 34 # 类别数量(不包括花牌)
# 类别名称(中文)
names: [
'一饼', '二饼', '三饼', '四饼', '五饼', '六饼', '七饼', '八饼', '九饼',
'一条', '二条', '三条', '四条', '五条', '六条', '七条', '八条', '九条',
'一万', '二万', '三万', '四万', '五万', '六万', '七万', '八万', '九万',
'东风', '南风', '西风', '北风', '红中', '发财', '白板'
]
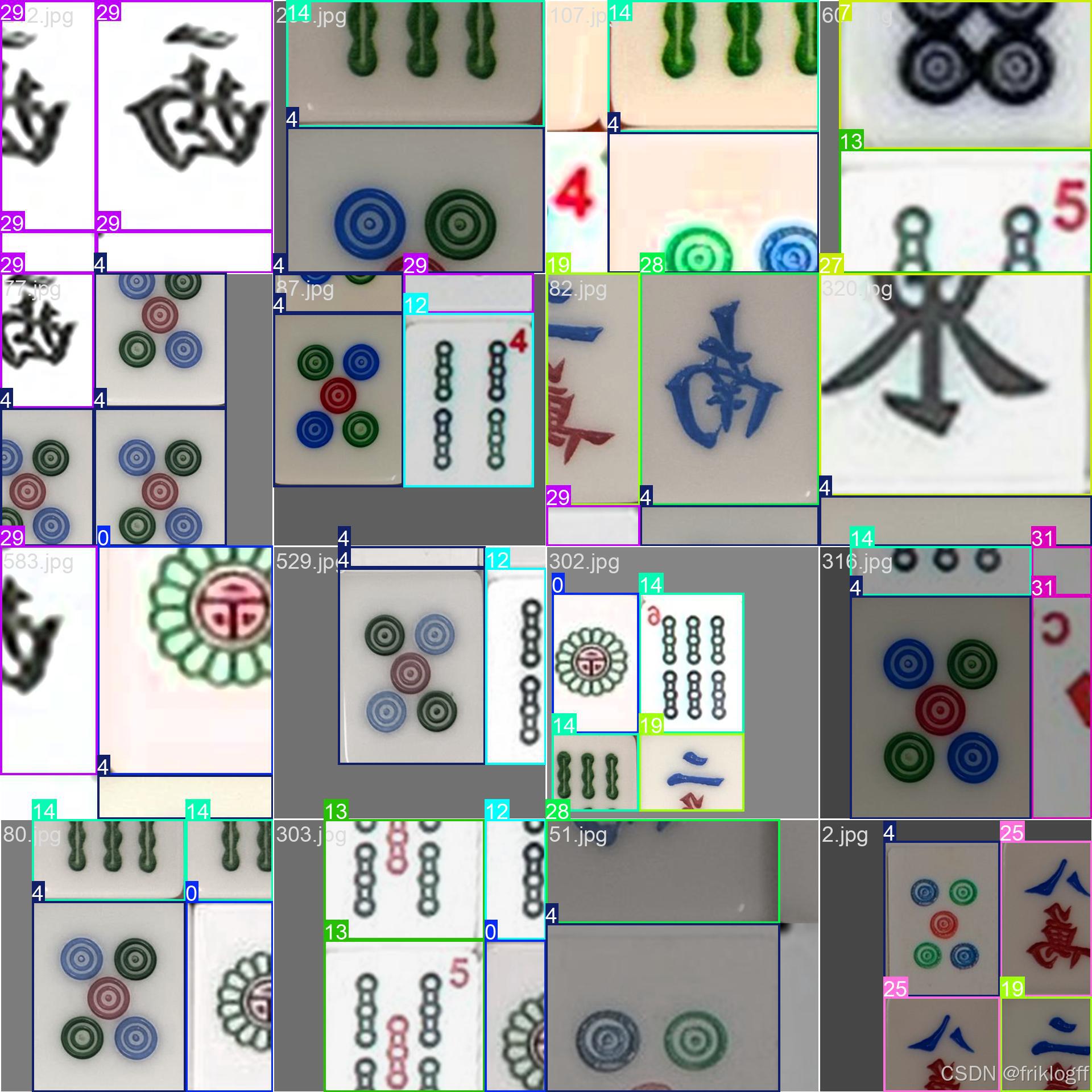
七、模型评估
(一)评估指标
使用 Precision、Recall、mAP50 和 mAP50-95 等指标评估模型性能。
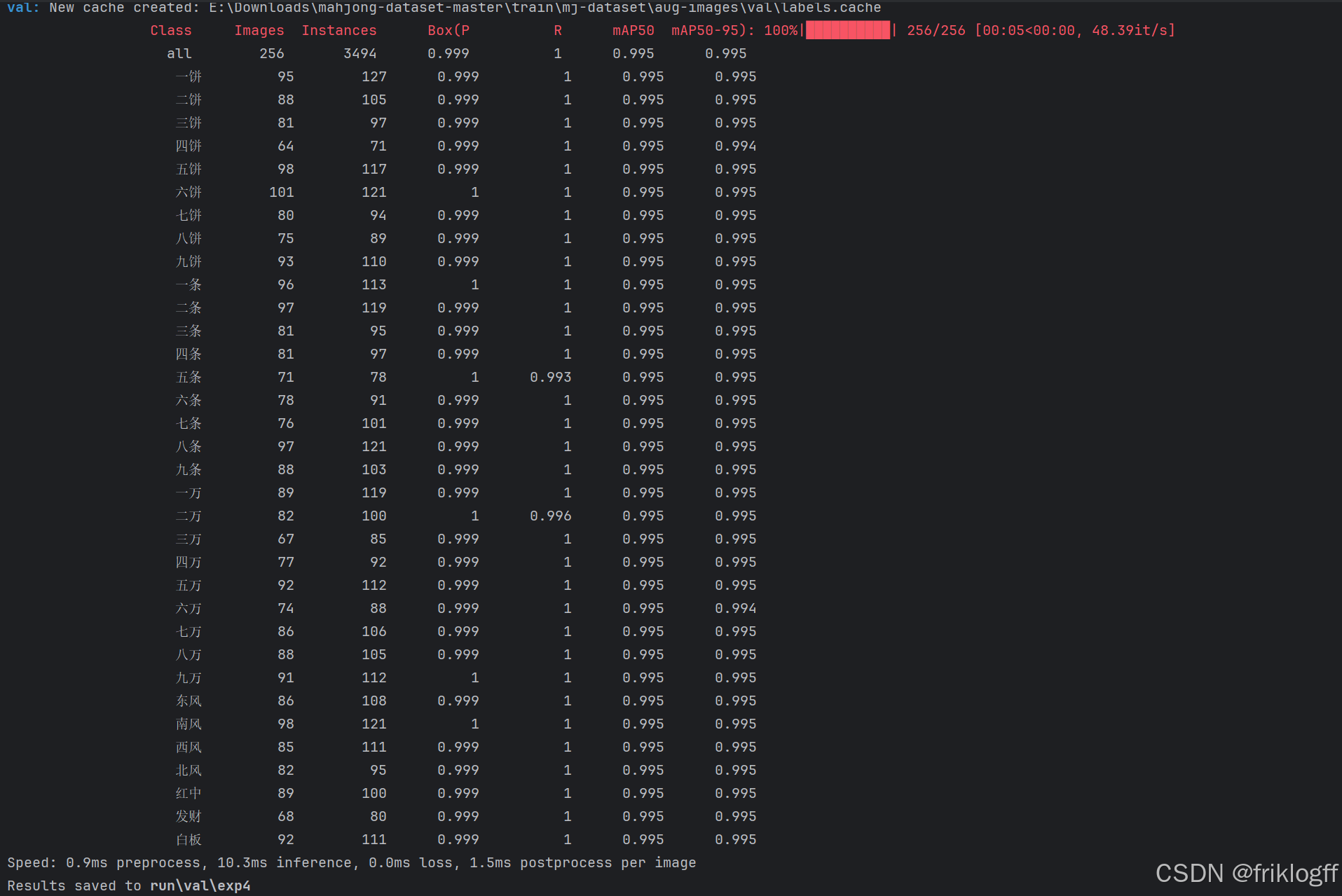
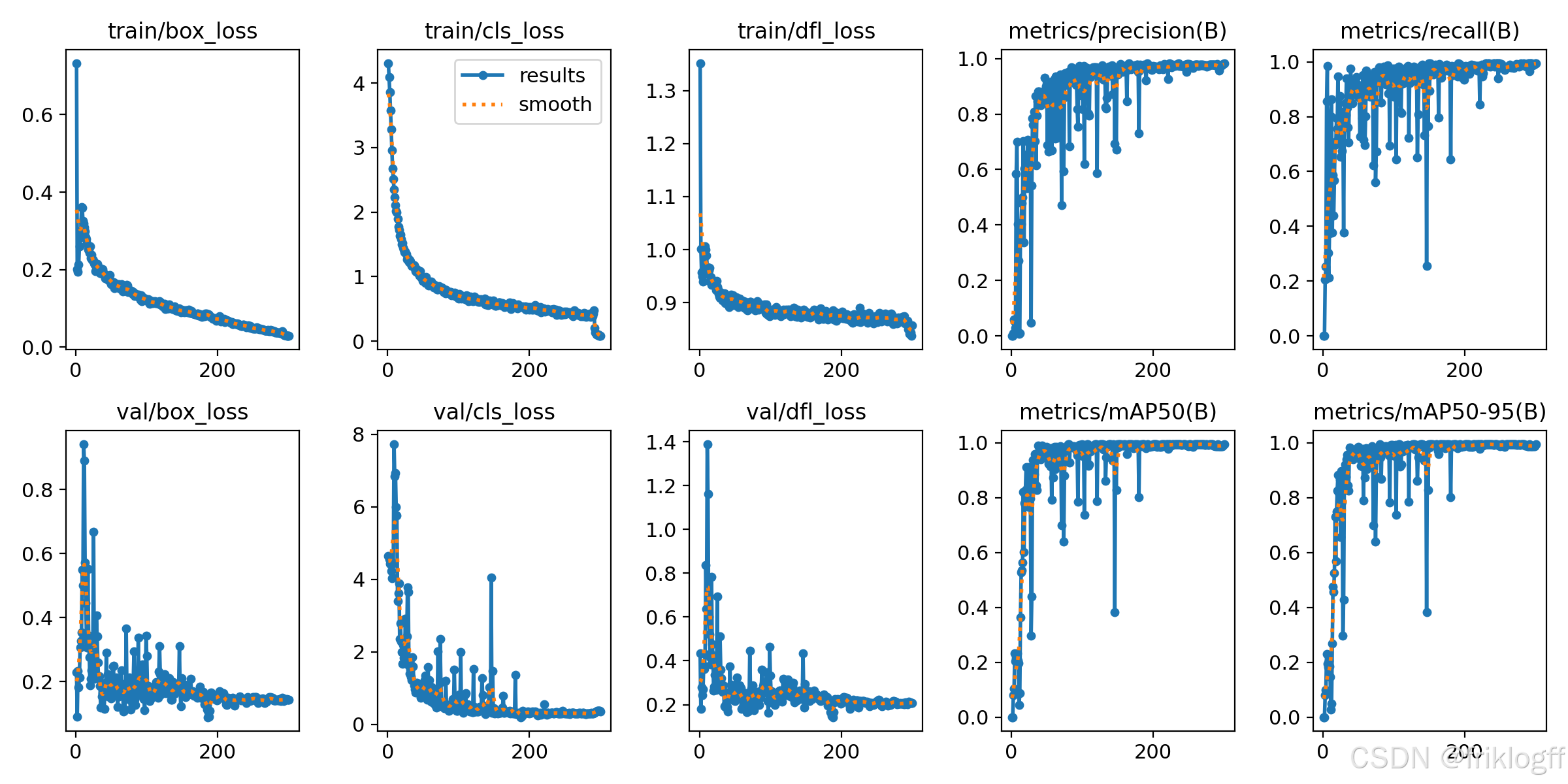
(二)结果分析
分析模型在不同类别上的表现,调整置信度阈值以优化预测结果。
项目链接
欢迎加星⭐️和贡献代码!如果您对项目感兴趣,请点击上面的链接访问项目页面,并点击右上角的"Star"按钮来表示您的支持。



















 433
433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











