







【阿旭机器学习实战】系列文章主要介绍机器学习的各种算法模型及其实战案例,欢迎点赞,关注共同学习交流。
本文对机器学习中的KMeans算法原理进行了简单介绍,并且通过实战案例:足球队分类详细介绍了其使用方法。
目录
一. 聚类—K均值算法(K-means)介绍
【关键词】K个种子,均值
1. K-means算法原理
聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中。
K-Means算法是一种聚类分析(cluster analysis)的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。
K-Means算法主要解决的问题如下图所示。我们可以看到,在图的左边有一些点,我们用肉眼可以看出来有四个点群,但是我们怎么通过计算机程序找出这几个点群来呢?于是就出现了我们的K-Means算法
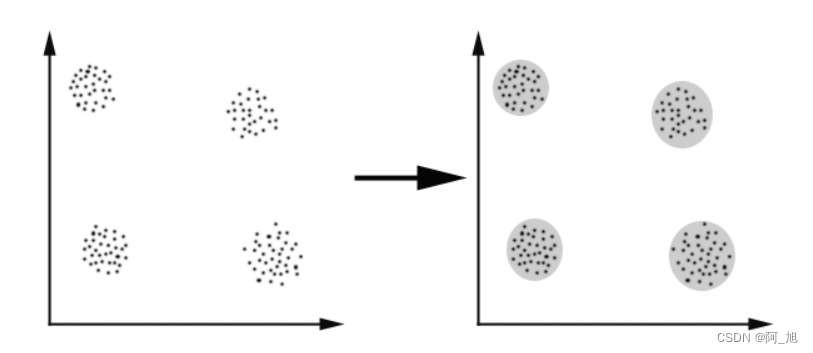
这个算法其实很简单,如下图所示:

从上图中,我们可以看到,A,B,C,D,E是五个在图中点。而灰色的点是我们的种子点,也就是我们用来找点群的点。有两个种子点,所以K=2。
然后,K-Means的算法步骤如下:
- 随机在图中取K(这里K=2)个种子点。
- 然后对图中的所有点求到这K个种子点的距离,假如点Pi离种子点Si最近,那么Pi属于Si点群。(上图中,我们可以看到A,B属于上面的种子点,C,D,E属于下面中部的种子点)
- 接下来,我们要移动种子点到属于他的“点群”的中心。(见图上的第三步)
- 然后重复第2)和第3)步,直到,种子点没有移动(我们可以看到图中的第四步上面的种子点聚合了A,B,C,下面的种子点聚合了D,E)。
这个算法很简单,重点说一下“求点群中心的算法”:欧氏距离(Euclidean Distance):差的平方和的平方根

2. K-Means主要缺陷——都和初始值K有关:
K是事先给定的,这个K值的选定是非常难以估计的。很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适。(ISODATA算法通过类的自动合并和分裂,得到较为合理的类型数目K)
K-Means算法需要用初始随机种子点来搞,这个随机种子点太重要,不同的随机种子点会有得到完全不同的结果。(K-Means++算法可以用来解决这个问题,其可以有效地选择初始点)
3. K-Means算法步骤:
- 从数据中选择k个对象作为初始聚类中心;
- 计算每个聚类对象到聚类中心的距离来划分;
- 再次计算每个聚类中心,(求平均)
- 计算标准测度函数,直到达到最大迭代次数,则停止,否则,继续操作。
- 确定最优的聚类中心
4. K-Means算法应用
看到这里,你会说,K-Means算法看来很简单,而且好像就是在玩坐标点,没什么真实用处。而且,这个算法缺陷很多,还不如人工呢。是的,前面的例子只是玩二维坐标点,的确没什么意思。但是你想一下下面的几个问题:
1)如果不是二维的,是多维的,如5维的,那么,就只能用计算机来计算了。
2)二维坐标点的X,Y 坐标,其实是一种向量,是一种数学抽象。现实世界中很多属性是可以抽象成向量的,比如,我们的年龄,我们的喜好,我们的商品,等等,能抽象成向量的目的就是可以让计算机知道某两个属性间的距离。如:我们认为,18岁的人离24岁的人的距离要比离12岁的距离要近,鞋子这个商品离衣服这个商品的距离要比电脑要近,等等。
二. 聚类算法示例
重要参数:
- n_clusters:聚类的个数
重要属性:
- cluster_centers_ : [n_clusters, n_features]的数组,表示聚类中心点的坐标
- labels_ : 每个样本点的标签
2.1 使用make_blobs生成模型样本
from sklearn import datasets
# 使用make_blobs生成随机点:100个样本,2个分类,2个特征
samples,target = datasets.make_blobs(n_samples=100,centers=2,n_features=2,random_state=0)
import matplotlib.pyplot as plt
%matplotlib inline
# 查看生成的样本
plt.scatter(samples[:,0],samples[:,1],c=target)
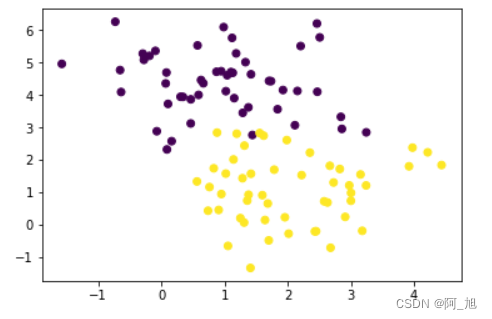
2.1 用k-means对以上的100个样本点做聚类划分
from sklearn.cluster import KMeans
# 如果将上面样本划分为3个类别,看此时kMeans是如何划分的,当然此处n_clusters也可以取2
km = KMeans(n_clusters=3)
km
KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,
n_clusters=3, n_init=10, n_jobs=1, precompute_distances='auto',
random_state=None, tol=0.0001, verbose=0)
# 训练
# 无监督学习算法无需标签
km.fit(samples)
# 这算法在训练阶段,根据km模型,引入相关的种子点,并且确定其位置,
# 并且不断的根据种子点进行聚类划分,直至所有的种子点不在移动
KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,
n_clusters=3, n_init=10, n_jobs=1, precompute_distances='auto',
random_state=None, tol=0.0001, verbose=0)
# 预测
y_ = km.predict(samples)
# 这个预测和监督学习理念不同,经过训练以后,已经把所有的点划分出了对应的聚类,
# 这个方法把这些聚类进行编号,然后输出
y_
array([2, 0, 1, 1, 2, 2, 1, 2, 1, 0, 1, 0, 1, 1, 2, 2, 0, 1, 0, 0, 1, 1,
2, 1, 0, 1, 0, 1, 1, 2, 0, 1, 0, 0, 2, 1, 0, 2, 2, 0, 1, 1, 1, 1,
1, 2, 0, 0, 1, 1, 0, 0, 1, 1, 2, 1, 2, 0, 2, 0, 0, 1, 1, 2, 1, 2,
1, 2, 2, 1, 1, 0, 2, 1, 1, 1, 0, 2, 1, 1, 2, 1, 1, 1, 1, 1, 0, 1,
0, 0, 2, 0, 2, 0, 1, 1, 0, 2, 1, 0])
# 求聚类中心点
centers = km.cluster_centers_
centers
array([[1.68009421, 0.44810043],
[0.78041206, 4.46050581],
[2.5938845 , 2.15788282]])
plt.scatter(samples[:,0],samples[:,1],c=y_)
plt.scatter(centers[:,0],centers[:,1],c="r")
<matplotlib.collections.PathCollection at 0x26d97ad4710>
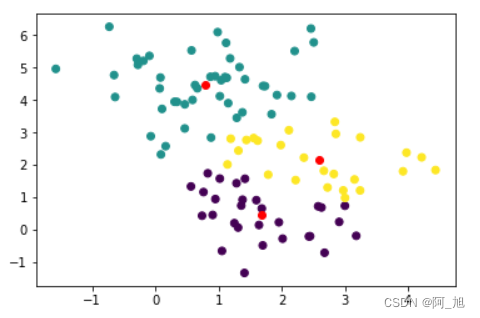
图中红色的点点表示3个聚类的中心
三. 聚类实战—依据3年排名进行最球队分类划分
问题描述:通过3年的亚洲球队排名,对亚洲球队做聚类,看看哪几个队属于一类。
3.1 读取数据
import pandas as pd
data = pd.read_csv("../data/AsiaZoo.txt",header=None)
data
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 中国 | 50 | 50 | 9 |
| 1 | 日本 | 28 | 9 | 4 |
| 2 | 韩国 | 17 | 15 | 3 |
| 3 | 伊朗 | 25 | 40 | 5 |
| 4 | 沙特 | 28 | 40 | 2 |
| 5 | 伊拉克 | 50 | 50 | 1 |
| 6 | 卡塔尔 | 50 | 40 | 9 |
| 7 | 阿联酋 | 50 | 40 | 9 |
| 8 | 乌兹别克斯坦 | 40 | 40 | 5 |
| 9 | 泰国 | 50 | 50 | 9 |
| 10 | 越南 | 50 | 50 | 5 |
| 11 | 阿曼 | 50 | 50 | 9 |
| 12 | 巴林 | 40 | 40 | 9 |
| 13 | 朝鲜 | 40 | 32 | 17 |
| 14 | 印尼 | 50 | 50 | 9 |
上面数据的2-4列,代表各国足球队在某3年世界杯的排名
3.2 提取样本,并用KMeans算法进行分类
# 提取样本
samples = data.iloc[:,1:4]
samples
| 1 | 2 | 3 | |
|---|---|---|---|
| 0 | 50 | 50 | 9 |
| 1 | 28 | 9 | 4 |
| 2 | 17 | 15 | 3 |
| 3 | 25 | 40 | 5 |
| 4 | 28 | 40 | 2 |
| 5 | 50 | 50 | 1 |
| 6 | 50 | 40 | 9 |
| 7 | 50 | 40 | 9 |
| 8 | 40 | 40 | 5 |
| 9 | 50 | 50 | 9 |
| 10 | 50 | 50 | 5 |
| 11 | 50 | 50 | 9 |
| 12 | 40 | 40 | 9 |
| 13 | 40 | 32 | 17 |
| 14 | 50 | 50 | 9 |
# 将足球队分为3类
km = KMeans(n_clusters=3)
km.fit(samples)
KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,
n_clusters=3, n_init=10, n_jobs=1, precompute_distances='auto',
random_state=None, tol=0.0001, verbose=0)
y_ = km.predict(samples)
y_
array([0, 1, 1, 2, 2, 0, 0, 0, 2, 0, 0, 0, 2, 2, 0])
3.3 查看分类结果
# 打印出3个分类中,各个足球队的名称
for i in range(3):
items = data[0][y_== i]
print(items)
0 中国
5 伊拉克
6 卡塔尔
7 阿联酋
9 泰国
10 越南
11 阿曼
14 印尼
Name: 0, dtype: object
1 日本
2 韩国
Name: 0, dtype: object
3 伊朗
4 沙特
8 乌兹别克斯坦
12 巴林
13 朝鲜
Name: 0, dtype: object
通过上面模型分类结果可以看到:
- 中国、伊拉克、伊拉克、阿联酋、泰国、越南、阿曼、印尼,为同一分类;
- 日本与韩国为一类;
- 伊朗、沙特、乌兹别克斯坦、巴林、朝鲜为一类
3.4 模型评估
-
轮廓系数: 聚类问题大多数情况下是没有类别的,对于没有标签的一般用轮廓系数来评测聚类的质量,它同时兼顾了聚类凝聚度和离散程度。
轮廓系数(Silhouette Coefficient)结合了聚类的凝聚度(Cohesion)和分离度(Separation),用于评估聚类的效果。该值处于-1~1之间,值越大,表示聚类效果越好。 -
ARI指标: (在知道分类的标签数据情况下才能用)ARI指标和监督学习中准确率(score)非常类似,只不过兼顾了聚类的下标与标签数据不能一一对应的问题。
from sklearn import metrics
metrics.adjusted_rand_score(y_,y_test)
在此例中,由于没有标签数据,因此我们使用轮廓系数进行评估
from sklearn import metrics
metrics.silhouette_score(samples, km.labels_)
0.5349542135842207
如果内容对你有帮助,感谢记得点赞+关注哦!
更多干货内容持续更新中…
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











