







《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~
👍感谢小伙伴们点赞、关注!
《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
引言
本文主要分享一个最新的ChatTTS语音合成项目的自制一键启动程序【部分界面英文进行了汉化处理】,开箱即用,无需配置运行环境,供小伙伴们学习交流。感兴趣的小伙伴可以文末免费获取。
启动后界面如下:

ChatTTS 简介
ChatTTS 是一款为对话场景设计的语音合成模型,专为 LLM 助手任务优化。它不仅支持多语言,还能预测和控制细粒度的韵律特征,包括笑声、停顿和插话等。实测语音生成效果还是十分不错的。
一键启动包使用说明

下载压缩包后解压,然后双击一键启动.exe运行压缩包。弹出的控制台会显示运行状态,如下所示:
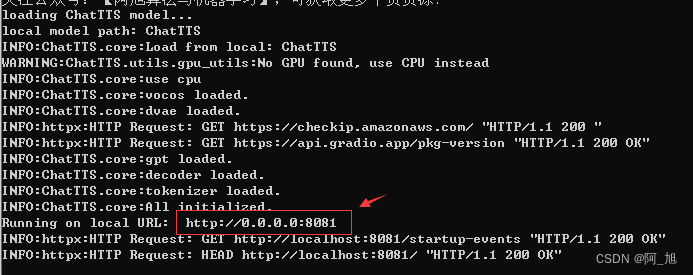
启动完成后,会自动弹出如下网页。如果没有自动弹出网页,可在浏览器输入控制台显示的url地址即可显示页面,如上方显示的:http://0.0.0.0:8081。
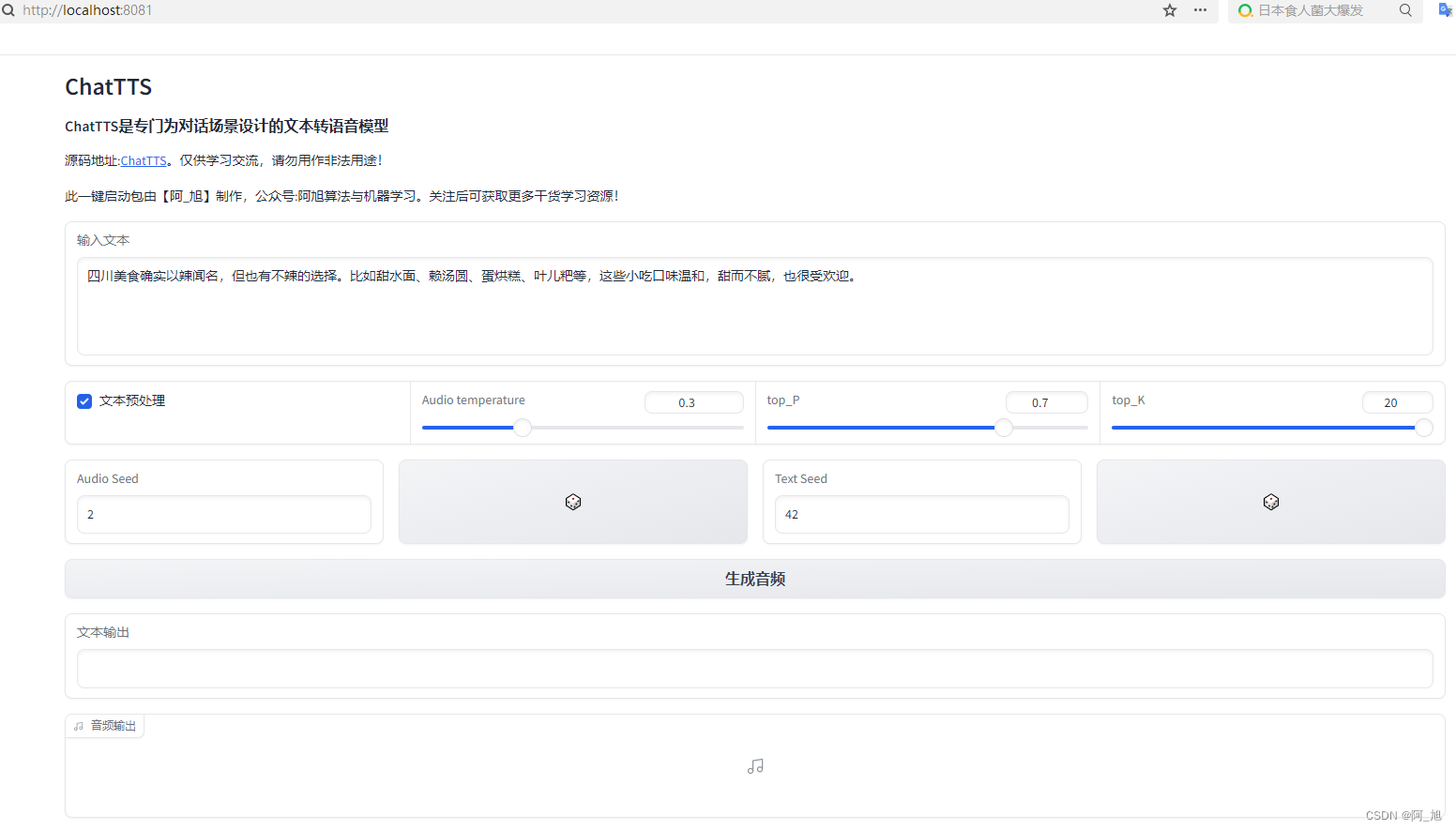
输入想生成语音的文字内容,点击生成音频按钮即可生成音频文件,控制台会显示处理进度。语音生成完成后,点击语音播放即可播放生成的音频文件。点击音频右上角下载标识,即可下载生成的音频文件。

下面对界面中的主要参数进行详细说明。
页面参数说明
文本预处理
表示是否对输入的文本先进行预处理后再进行生成音频。默认勾选。勾选此选项可以对输入文本进行优化或修改,提升语音的自然度和可理解性。
Audio Seed

用于初始化随机数生成器的种子值,可用于生成不同音色的音频文件。设置相同的 Audio Seed 可以确保重复生成一致的语音,便于实验和调试。点击旁边的骰子按钮,可对音色进行随机抽卡。
Text Seed

类似于 Audio Seed,在文本生成阶段用于初始化随机数生成器的种子值。点击旁边的骰子按钮,可对文本进行随机抽卡。,处理后会随机加一些更细粒度的控制,比如调整笑声、停顿和口音等。
Audio Temperature
用于控制输出的随机性。数值越高,生成的语音越可能包含意外变化;数值较低则趋向于更平稳的输出。
Top_P 和 Top_K
Top_P: 核采样策略,定义概率累积值,模型将只从这个累积概率覆盖的最可能的词中选择下一个词。
Top_K: 限制模型考虑的可能词汇数量,设置为一个具体数值,模型将只从这最可能的 K 个词中选择下一个词。
进阶使用技巧
除了基本的参数设置,还可以进行更细粒度的控制,比如调整笑声、停顿和口音。以下是一些常用的控制标记:
[oral_(0-9)]: 控制口音强度
[laugh_(0-2)]: 控制笑声
[break_(0-7)]: 控制停顿时间
试试不同的组合,比如 [oral 2][laugh 0][break 4],探索更多有趣的语音效果。
项目地址:https://github.com/2noise/ChatTTS
资料获取
关于本文的一键启动包等文件都已打包好,供需要的小伙伴们学习,免费获取方式如下:
















 542
542











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











