







深度学习_神经网络的学习
参考书籍:深度学习入门_基于python的 理论与实现
- 神经网络学习:从训练数据中自动获取最优权重参数的过程
- 学习的目的:以该损失函数为基准,找出能使它的值达到最小的权重参数
- 深 度 学 习 :端 到 端 机 器 学 习(end-to-end machine learning)。这里所说的端到端是指从一端到另一端的意思,也就是从原始数据(输入)中获得目标结果(输出)的意思
- 训练数据:使用训练数据进行学习,寻找最优的参数
- 测试数据(监督数据):使用测试 数据评价训练得到的模型的实际能力
- 泛化能力:处理未被观察过的数据(不包含在训练数据中的数据)的能力;获得泛化能力是机器学习的最终目标
- 过拟合:虽然训练数据中的数字图像能被正确辨别,但是不在训练数据中的数字图像却无法被识别的现象。
- 损失函数:神经网络性能的“恶劣程度”的指标,即当前的神经网络对监督数据在多大程度上不拟合,在多大程度上不一致
- 均方误差: 均方误差会计算神经网络的输出和正确解监督数据的各个元素之差的平方,再求总和;yk是表示神经网络的输出,tk表示监督数据,k表示数据的维数
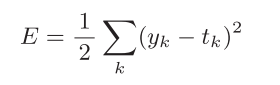
- 交叉熵误差:交叉熵误差的值是由正确解标签所对应的输出结果决定的;。比如,假设正确解标签的索引是“2”,与之对应的神经网络的输出是0.6,则交叉熵误差是−log 0.6 = 0.51;log表示以e为底数的自然对数(loge),yk是神经网络的输出,tk是正确解标签;
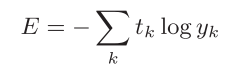
- mini-batch学习:从训练数据中选出一批数据(称为mini-batch,小批量),然后对每个mini-batch进行学习;随机选择的小批量数据(mini-batch作为全体训练数据的近似值。
- 中心差分:计算函数F在(x + h)和(x − h)之间的差分,因为这种计算方法以x为中心,计算它左右两边的差分,所以也称为中心差分
- 前向差分:(x + h)和x之间的差分称为前向差分
- 数值微分:利用微小的差分求导数的过程称为数值微分
- 解析性求解(解析性求导):基于数学式的推导求导数的过程,则用“解析
性”(analytic)一词,称为“解析性求解”或者“解析性求导”。 - 偏导数:多个变量的函数的导数;偏导数需要将多个变量中的某一个变量定为目标变量,并将其他变量固定为某个值
- 梯度指示的方向:各点处的函数值减小最多的方向
- 梯度法:函数的取值从当前位置沿着梯度方向前进一定距离,然后在新的地方重新求梯度,再沿着新梯度方向前进,如此反复,不断地沿梯度方向前进。像这样,通过不断地沿梯度方向前进,逐渐减小函数值的过程就是梯度法(gradient method)
- 梯度下降法:寻找最小值的梯度法
- 梯度上升法:寻找最大值的梯度法
- 学习率(超参数):学习率决定在一次学习中,应该学习多少,以及在多大程度上更新参数;相对于神经网络的权重参数是通过训练数据和学习算法自动获得的,学习率这样的超参数则是人工设定的
- 随机梯度下降法(SGD):对随机选择的数据进行的梯度下降法















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









