







首先总结一下核心过程:
导入数据,建立网络,设置相关标准,进行训练,评估模型,进行预测。
导入数据要具体问题具体分析,因此我先了解一下建立网络。
给大家剧透先,我经历一番学习之后,基本上大家达成共识的就是:
建议用现成的网络照着需求改点参数。
原来大家的教程不提及自己的网络为什么那么搭并不是藏着掖着,而是很有可能真的不知道为啥。不过到了真的能搞清楚这些层的根本用法的时候,可能真的就是机密级的知识了吧。
构建网络的代码
你可以通过将网络层实例的列表传递给 Sequential 的构造器,来创建一个 Sequential 模型:
from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential([
Dense(32, input_shape=(784,)),
Activation('relu'),
Dense(10),
Activation('softmax'),
])
也可以简单地使用 .add() 方法将各层添加到模型中:
model = Sequential()
model.add(Dense(32, input_dim=784))
model.add(Activation('relu'))
各种例子下建立的网络
以下用到的层有:
Dense
Conv1D
Conv2D
MaxPooling1D
MaxPooling2D
GlobalAveragePooling1D
Dropout
Flatten
Embedding
LSTM 循环神经网络
基于多层感知器 (MLP) 的 softmax 多分类:
model.add(Dense(64, activation='relu', input_dim=20))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
基于多层感知器的二分类:
model.add(Dense(64, input_dim=20, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
类似 VGG 的卷积神经网络
# 输入: 3 通道 100x100 像素图像 -> (100, 100, 3) 张量。
# 使用 32 个大小为 3x3 的卷积滤波器。
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(100, 100, 3)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
基于 LSTM 的序列分类:
model.add(Embedding(max_features, output_dim=256))
model.add(LSTM(128))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
基于 1D 卷积的序列分类:
model.add(Conv1D(64, 3, activation='relu', input_shape=(seq_length, 100)))
model.add(Conv1D(64, 3, activation='relu'))
model.add(MaxPooling1D(3))
model.add(Conv1D(128, 3, activation='relu'))
model.add(Conv1D(128, 3, activation='relu'))
model.add(GlobalAveragePooling1D())
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
基于栈式 LSTM 的序列分类
model.add(LSTM(32, return_sequences=True,
input_shape=(timesteps, data_dim))) # 返回维度为 32 的向量序列
model.add(LSTM(32, return_sequences=True)) # 返回维度为 32 的向量序列
model.add(LSTM(32)) # 返回维度为 32 的单个向量
model.add(Dense(10, activation='softmax'))
第一层需要给定尺寸
某些 2D 层,例如 Dense,支持通过参数 input_dim 指定输入尺寸,某些 3D 时序层支持 input_dim 和 input_length 参数。
层
基础层:
tf.keras.layers.Input():输入层。通常使用Functional API方式构建模型时作为第一层
tf.keras.layers.DenseFeature():特征列接入层,用于接收一个特征列列表并产生一个密集连接层。
tf.keras.layers.Flatten():压平层,用于将多维张量压成一维。
tf.keras.layers.Reshape():形状重塑层,改变输入张量的形状。
tf.keras.layers.Concatenate():拼接层,将多个张量在某个维度上拼接。
tf.keras.layers.Add():加法层。
tf.keras.layers.Subtract(): 减法层。
tf.keras.layers.Maximum():取最大值层。
tf.keras.layers.Minimum():取最小值层。
tf.keras.layers.SpatialDropout2D():空间随机置零层。训练期间以一定几率将整个特征图置0,一种正则化手段,有利于避免特征图之间过高的相关性。
tensorflow2.0——神经网络的层(层全连接层、卷积层、池化层、BN层、激活层、dropout层及其他层)
激活函数
只有全连接层和卷积层要用到激活函数,是因为他们本身是线性运算。他们将输入的数据线性运算完之后再经过激活函数输出激活值
深度学习笔记(二):激活函数的前世今生
全连接层
每个神经元与前后相邻层的每一个神经元都有连接关系。
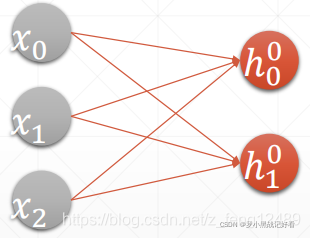
每一条线上都有各自的权值W 每个输出位置都要加一个偏置b
所以

而Dense()封装了全连接层的处理
layers.Dense(输出节点数Units ,激活函数类型)
输入节点数将根据第一次运算时的输入shape 确定【全连接层运算数据量非常大,不可能作为第一层处理源数据】,同时根据输入、输出节点数自动创建并初始化权值矩阵W 和偏置向量b。其中activation 参数指定当前层的激活函数,可以为常见的激活函数或自定义激活函数,也可以指定为None 无激活函数。
我们可以通过类内部的成员名kernel 和bias 来获取权值矩阵W 和偏置b
fc = layers.Dense(512, activation=tf.nn.relu)
h1 = fc(x) # 通过fc 类完成一次全连接层的计算
fc.kernel # 获取Dense 类的权值矩阵
fc.bias # 获取Dense 类的偏置向量
卷积层
layers.Conv2D(48, kernel_size=3, strides=1, padding='same')
Conv2D 这个是二维图像卷积 RGB图像有3通道,但也是2D的,一个卷积核会自动分出3个通道去卷这张图片,这三个通道的核的数值不同,是随机的。
卷积核个数:48 每张图片都要被48个不同的卷积核卷一次
卷积核尺寸:3 卷积核是33的 里面数值随机 等着训练
步长:1 当步长为1时,可以保证输出的图片与输入的图片尺寸一致。在卷积层中,可以通过调节步长参数 s 实现特征图的高宽成倍缩小,从而降低网络的参数量。不过池化层可以专门实现尺寸缩减功能。
填充=‘same’ 把0填充上去
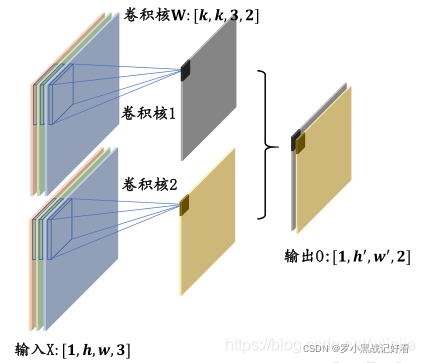
如上图,3通道的图片,经过两个卷积核卷积之后输出的是两个通道的图片。
其中,卷积核1这一层图示简化了,实际上是有3个33的不同数值的核分别卷3个通道的原图,然后数值相加后形成的输出值,如下图。
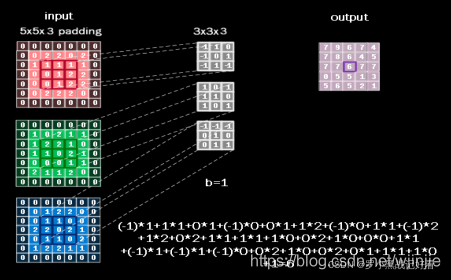
池化层
池化层同样基于局部相关性的思想,通过从局部相关的一组元素中进行采样或信息聚合,从而得到新的元素值。通常我们用到两种池化进行下采样:
(1)最大池化(Max Pooling),从局部相关元素集中选取最大的一个元素值。
tf.keras.layers.MaxPool2D()
pool_size:池化窗口的维度,包括长和宽,默认是(2,2)。
strides:卷积核在做池化时移动步幅的大小,默认与pool_size相同为(2,2)。
padding:处理图像数据进行池化在边界补零的策略。SAME表示补零,VALID表示不补零。
data_format:输入图像数据的格式,默认格式是channels_last,也可以是根据需要设置成channels_fitst。在进行图像数据处理时,图像数据的格式分为channels_last(batch, height, width, channels)和channels_first(batch, channels, height, width)两种。
(2)平均池化(Average Pooling),从局部相关元素集中计算平均值并返回。
BN层(batchnorm)
batchnorm位于X=WU+B 激活值获得之后,非线性函数变换之前。训练的时候均值与方差用的是batch样本的方差,测试与预测时用的是每个batch的均值和方差平均之后得到的滑动均值与滑动方差。
在训练过程中,隐层的输入分布老是变来变去,这就是所谓的内部协变量偏移“Internal Covariate Shift”,为了让每个隐层节点的激活输入分布固定下来,BN层对深层神经网络每个隐层神经元的激活值做简化版本的白化操作。白化,就是对输入数据分布变换到0均值,单位方差的正态分布。
就,在训练过程中,数据会越来越向Sigmoid函数的平缓部分靠近,就会导致在反向传播的时候梯度变小甚至消失,BN层就是把数据范围拉回斜率比较大的部分。同时 BN为了保证非线性的获得,对变换后的满足均值为0方差为1的x又进行了scale加上shift操作(y=scale*x+shift),核心思想应该是想找到一个线性和非线性的较好平衡点,既能享受非线性的较强表达能力的好处,又避免太靠非线性区两头使得网络收敛速度太慢。

在BN出现之前,我们的归一化操作一般都在数据输入层,对输入的数据进行求均值以及求方差做归一化,但是BN的出现打破了这一个规定,我们可以在网络中任意一层进行归一化处理.
内部协变量偏移(Internal Covariate Shift)和批归一化(Batch Normalization)
顺便还有个残差连接的知识点
深度学习模型中的残差连接
dropout
我们知道如果要训练一个大型的网络,而训练数据很少的话,那么很容易引起过拟合,一般情况我们会想到用正则化、或者减小网络规模。然而Hinton在2012年文献:《Improving neural networks by preventing co-adaptation of feature detectors》提出了,在每次训练的时候,随机让一半的特征检测器停过工作,这样可以提高网络的泛化能力,Hinton又把它称之为dropout。
过拟合是深度神经网(DNN)中的一个常见问题,现在神经网络经常用到dropout来避免过拟合。
dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。需要注意的是如果采用dropout,训练时间大大延长,但是对测试阶段没影响。
理解神经网络中的Dropout
Residual
Residual【残差】。在数理统计中,残差是指实际观察值与估计值(拟合值)之间的差。
非常非常深的神经网络是很难训练的,因为存在梯度消失和梯度爆炸问题。跳跃连接(Skip connection)可以从某一层网络层获取激活,然后迅速反馈给另外一层,甚至是神经网络的更深层。利用跳跃连接构建能够训练深度网络的ResNets,有时深度能够超过100层。
Residual模块是由两个子模块convBlock和skipLayer构成的,参数是输入层数和输出层数。
convBlock子模块相对复杂,由三组batchNormalization+ReLU+convolution串联构成。 skipLayer比较简单,如果输入层数等于输出层数,就直接输出,如果不等,就通过一个卷积层让输出层数变成设定值。
最后两个子模块的输出合在一起,作为Residual模块的输出。
残差网络(ResNets)的残差块(Residual block)
ResNet中残差块的理解(附代码)
怎么选择每个层
BP神经网络主要由输入层、隐藏层、输出层构成
对于一般简单的数据集,一两层隐藏层通常就足够了
没有隐藏层:仅能够表示线性可分函数或决策
隐藏层数=1:可以拟合任何“包含从一个有限空间到另一个有限空间的连续映射”的函数
隐藏层数=2:搭配适当的激活函数可以表示任意精度的任意决策边界,并且可以拟合任何精度的任何平滑映射
隐藏层数>2:多出来的隐藏层可以学习复杂的描述(某种自动特征工程)
在CV、NLP等特殊领域,可以使用CNN、RNN、attention等特殊模型,不能不考虑实际而直接无脑堆砌多层神经网络。尝试迁移和微调已有的预训练模型,能取得事半功倍的效果。
在隐藏层中使用太少的神经元将导致欠拟合(underfitting)。
隐藏层中的神经元过多可能会导致过拟合(overfitting)。当神经网络具有过多的节点(过多的信息处理能力)时,训练集中包含的有限信息量不足以训练隐藏层中的所有神经元,因此就会导致过拟合。即使训练数据包含的信息量足够,隐藏层中过多的神经元会增加训练时间,从而难以达到预期的效果。
通常,对所有隐藏层使用相同数量的神经元就足够了【因为一般最多也就放2层隐藏层】。对于某些数据集,拥有较大的第一层并在其后跟随较小的层将导致更好的性能,因为第一层可以学习很多低阶的特征,这些较低层的特征可以馈入后续层中,提取出较高阶特征。
需要注意的是,与在每一层中添加更多的神经元相比,添加层层数将获得更大的性能提升。因此,不要在一个隐藏层中加入过多的神经元。
神经元数量通常可以由一下几个原则大致确定:
隐藏神经元的数量应在输入层的大小和输出层的大小之间。
隐藏神经元的数量应为输入层大小的2/3加上输出层大小的2/3。
隐藏神经元的数量应小于输入层大小的两倍。
【啧,这不胡闹呢嘛。】

总而言之,隐藏层神经元是最佳数量需要自己通过不断试验获得,建议从一个较小数值比如1到5层和1到100个神经元开始,如果欠拟合然后慢慢添加更多的层和神经元,如果过拟合就减小层数和神经元。此外,在实际过程中还可以考虑引入Batch Normalization, Dropout, 正则化等降低过拟合的方法。
如何确定神经网络的层数和隐藏层神经元数量
在经典分类网络,比如LeNet、AlexNet中,在前面的卷积层提取特征之后都串联全连接层来做分类。但是近些年来【文章发布于2019年】,越来越多的网络,比如SSD,FasterRCNN的RPN,MTCNN中的PNet,都使用卷积层来代替全连接,也一样可以做到目标分类的效果,而且
- 更灵活,不需要限定输入图像的分辨率;
- 更高效,只需要做一次前向计算。
全连接层输入10 x 10 x 3 = 300个神经元,卷积的时候每次卷积只是连接了其中的一个3 x 3 x 3 =
27的子集,那么可以在做全连接的时候,除了这27个神经元设置连接关系,其余的 300 - 27 =
273个连接系数直接设置为0就可以了。做 10 x 10 x 1 =
100次这样的全连接,就可以得到100个输出神经元,再reshape成10 x 10 x 1的形状就可以了。所以,由上面的讨论可以得到,卷积层只是全连接层的一个子集,把全连接的某些连接系数设置为0,就可以达到和卷积相同的效果
CNN中使用卷积代替全连接【所以卷积神经网络中可以没有全连接层】














 1874
1874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









