







 Boruta算法是一种基于随机森林的特征选择方法,通过对比特征与影子特征的重要性和二项分布来确定有效特征。它创建特征的随机版本(影子特征),并用随机森林模型训练,比较原始特征与影子特征的重要性。如果一个特征的重要性高于其所有影子特征,那么该特征被视为重要。通过多次迭代和二项分布分析,确定特征的确定性水平,最终选出预测性强的特征。案例展示了如何使用BorutaPy库进行特征选择。
Boruta算法是一种基于随机森林的特征选择方法,通过对比特征与影子特征的重要性和二项分布来确定有效特征。它创建特征的随机版本(影子特征),并用随机森林模型训练,比较原始特征与影子特征的重要性。如果一个特征的重要性高于其所有影子特征,那么该特征被视为重要。通过多次迭代和二项分布分析,确定特征的确定性水平,最终选出预测性强的特征。案例展示了如何使用BorutaPy库进行特征选择。
Boruta介绍
链接:https://github.com/scikit-learn-contrib/boruta_py
Boruta算法是目前非常流行的一种特征筛选方法,其核心是基于两个思想:shadow features 和 binomial distribution。
1、shadow features
在Boruta中,特征之间并不会相互竞争,相反地,它们会和他们的随机版本相互竞争。实践中,假设我们的特征是X,
我们对X中的每个特征进行随机shuffle,这些shuffle过后的特征被称为shadow features;
这个时候,我们将shadow dataframe附加到原始dataframe以获得一个新的dataframe(我们称之为X_boruta),它的特征列数是原先X的两倍。然后我们使用一个模型对其进行训练,得到每个特征的特征重要性。
一个特征如果是有用的话,那么它的特征重要性肯定要比它的随机版本要好。
这个时候我们只需要将原始特征中特征重要性高于随机版本中最高的特征重要性分数的那些原始特征进行保留即可。但这可能会存在一个问题,这个模型或许训练的不是很好,特征重要性不是很准,于是我们就需要第二个策略。
2、binomial distribution
这一步相信大家并不陌生,核心就是不断迭代,如果一次存在侥幸,那么我们就迭代多次,比如20次,100次,然后取特重要性的均值,在进行比较筛选。这是最基础的想法,在Boruta中,特征的最大不确定性水平以50%的概率表示,就像扔硬币一样。由于每个独立的实验可以给出一个二元结果(命中或不命中),一系列的n个试验遵循二项分布,在python中,二项式分布的概率mass函数可以通过下面方式计算得到:
import scipy as sp
trials = 20
pmf = [sp.stats.binom.pmf(x, trials, .5) for x in range(trials + 1)]
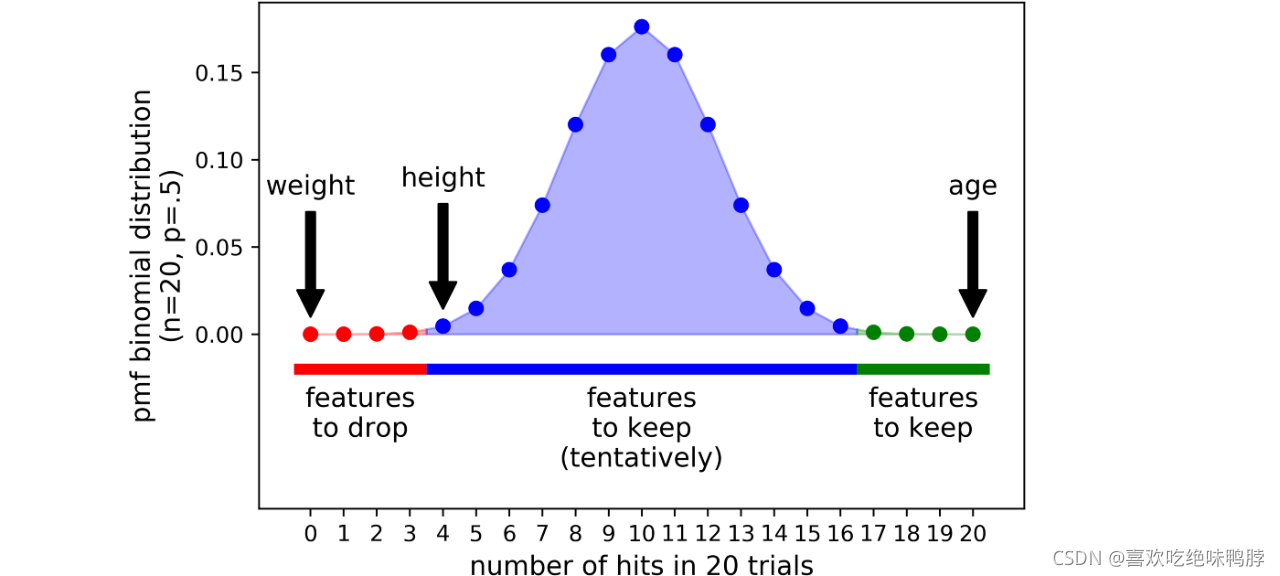
其中:
红色区域是拒绝区域:这块区域的特征被认为是噪声,因此它们可以被直接丢弃;
蓝色区域是犹豫区域:Boruta对这个区域的特征难以抉择;
绿色区域是可接受区域:这里的特征被认为是预测性的,一般可以被保留。
案例1:
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from boruta import BorutaPy
# load X and y
# NOTE BorutaPy accepts numpy arrays only, hence the .values attribute
X = pd.read_csv('examples/test_X.csv', index_col=0).values
y = pd.read_csv('examples/test_y.csv', header=None, index_col=0).values
y = y.ravel()
# define random forest classifier, with utilising all cores and
# sampling in proportion to y labels
rf = RandomForestClassifier(n_jobs=-1, class_weight='balanced', max_depth=5)
# define Boruta feature selection method
feat_selector = BorutaPy(rf, n_estimators='auto', verbose=2, random_state=1)
# find all relevant features - 5 features should be selected
feat_selector.fit(X, y)
# check selected features - first 5 features are selected
feat_selector.support_
# check ranking of features
feat_selector.ranking_
# call transform() on X to filter it down to selected features
X_filtered = feat_selector.transform(X)
案例2
from boruta import BorutaPy
from sklearn.ensemble import RandomForestRegressor
import numpy as np
rf = RandomForestRegressor(n_jobs = -1, max_depth = 5)
boruta = BorutaPy(
estimator = rf,
n_estimators = 'auto',
max_iter = 100 # number of trials to perform
)
# 模型训练
boruta.fit(np.array(X), np.array(y))
# 输出结果
green_area = X.columns[boruta.support_].to_list()
blue_area = X.columns[boruta.support_weak_].to_list()
print('features in the green area:', green_area)
print('features in the blue area:', blue_area)
参考文献
- Kursa M., Rudnicki W., “Feature Selection with the Boruta Package”
Journal of Statistical Software, Vol. 36, Issue 11, Sep 2010 - https://github.com/scikit-learn-contrib/boruta_py
- Boruta Explained Exactly How You Wished Someone Explained to You


















 2841
2841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









