






基于OpenCL的多维卷积计算实现
1 摘要
多维卷积是基于深度学习的图像处理中常用的一种算法,它可以实现对图像的平滑、滤波等操作。本文将介绍如何使用 OpenCL C++实现多维卷积计算。首先,需要了解多维卷积的计算原理。多维卷积是指将4维卷积滤波器应用到3维图像上,得到三维输出图像。多维卷积的计算可以分解为多个3维卷积的计算,然后再将它们合并起来。这个过程可以通过并行计算来实现,以提高计算效率。实现多维卷积计算的关键在于选择合适的并行计算模型,以及编写高效的计算代码。使用 OpenCL C++实现多维卷积计算,需要准备一个合适的并行场景,并为每个线程分配计算资源,如 GPU 核心、内存等。此外,还需要编写一些特殊的代码来处理数据并行和代码并行。本文介绍了如何使用 OpenCL C++实现多维卷积计算,包括计算原理、并行计算模型、代码实现等。通过实践发现,使用 OpenCL C++实现多维卷积计算可以提高计算效率,减少计算时间。
2 背景介绍
2.1 OpenCL开发平台
OpenCL 是一种开放标准的并行计算框架,它允许开发人员在不同的计算平台上编写可移植的并行应用程序,包括 CPU、GPU、FPGA 和 DSP 等。它最初由英特尔和 NVIDIA 两家公司发起,并于 2008 年正式发布。
OpenCL 提供了一个通用并行计算模型,它允许开发人员将任务分解成小块并分配给多个计算节点进行并行计算。OpenCL 还提供了一组 API(应用程序编程接口),使开发人员可以轻松地编写并行应用程序,包括 CLD(并行数据流图)、CLFFT(并行快速傅里叶变换) 和 CLBLAS(并行低级 BLAS 操作) 等。
OpenCL 应用程序可以在不同的计算平台上运行,例如在 Linux、Windows 和 macOS 等操作系统上,并且可以与其他开源和商业并行计算框架共存,如 CUDA(用于 NVIDIA GPU 计算) 和 OpenMP(用于多线程应用程序开发)。
OpenCL(Open Computing Language) 是一种用于在通用计算机体系结构上进行高性能计算编程的开放标准。它提供了一种跨平台的解决方案,可以让开发者使用 C++ 或其他编程语言编写 OpenCL 程序,然后运行在支持 OpenCL 的硬件上。
下面是 OpenCL 开发的一般流程:
①确定需求:确定需要实现的计算需求,例如图像处理、机器学习等。
②确定硬件平台:选择支持 OpenCL 的硬件平台,如 GPU、FPGA 等。
③编写 OpenCL 程序:使用 C++ 或其他编程语言编写 OpenCL 程序,并使用 OpenCL 接口库进行编译和链接。
④准备硬件资源:为 OpenCL 程序分配所需的硬件资源,如 GPU 核心、内存等。
⑤调试和测试:对 OpenCL 程序进行调试和测试,以确保其在不同硬件平台上的性能和稳定性。
⑥发布应用程序:将 OpenCL 程序发布到目标硬件平台上,并使用 OpenCL 应用程序接口 (API) 进行运行和调试。
在开发 OpenCL 程序时,需要了解 OpenCL 的规范和接口库,以及硬件平台的详细信息。此外,还需要了解如何使用 OpenCL 的并行计算模型,以实现高效的计算性能。开发者可以使用 OpenCL 接口库提供的函数和工具来编写和调试 OpenCL 程序。
推荐参考书目:
2.2 卷积神经网络及其加速
卷积神经网络(CNN)是一种常用的深度学习网络,它可以有效地处理图像、语音、自然语言等数据。CNN的基本思想是利用卷积运算来提取局部特征,然后通过池化层来降低维度和增加不变性,最后通过全连接层或其他输出层来完成分类或回归等任务。
在卷积神经网络流行起来之前,计算机识别问题涉及从所提供的数据中提取特征,这些数据不够有效或精度不高 5 。然而,近年来,卷积神经网络试图在其应用的所有领域中提供更高水平的效率和准确性,其中最流行的领域是对象检测、数字和图像识别。它采用了一个明确的步骤算法,包括反向传播、卷积层、特征形成和池化等方法。此外,本文还将探讨涉及CNN模型的各种框架和工具的使用。从一开始,神经网络工作背后的基本理念就是尽可能模仿人脑的工作。卷积神经网络通过与生物的视觉感觉器官合作,并在识别各种类型的物体的过程中,使用一系列按特定顺序遵循的各种技术,即卷积运算、ReLu层、池化、平坦化和Softmax交叉熵,识别数字、图像或任何物体中的特定动作。下图展示了在计算机中图像数据如何以举证的形式保存。

下图展示了卷积操作的基本原理:

对于卷积计算的加速研究一直是领域的重点。6提出来基于FPGA深度可分离卷积加速的方法,设计的加速器在可以加速深度可分离卷积的情况下,可以实现32位浮点17.11GOPS。7为加速方法提出了三个层次的分类法,即结构层次、算法层次和实现层次。我们还从CNN架构压缩、算法优化和基于硬件的改进等方面分析了加速方法。最后,我们从各个层面对这些加速和优化方法的不同角度进行了讨论。讨论表明,各个层次的方法仍有很大的探索空间。
然而,目前依然缺乏基于异构计算资源的并行卷积加速实现,现有的主流的cuda编程针对gpu,而其他的研究是针对某一种卷积或者是某一开发平台。因此,基于openCL实现一种多平台通用的异构并行卷积计算加速库是很有意义的。
3 开发平台配置
3.1 硬件配置
① Device name: Intel® FPGA Emulation Device
② Device units number: 12
③ Device frequence: 3400 MHz
3.2 软件环境
④ intel devcloud oneAPI平台;
⑤ opencl;
⑥ dpcpp;
⑦ sycl;
4 设计思路
4.1 工作组与并行化
卷积计算需要使用卷积滤波器kernel和输入img进行计算,并且计算的次数是输出的矩阵的体积,即ocohow。ocohow次计算之间并不会互相干扰,可以并行执行,且不同的计算之间对kernel和img是只读操作,对outputbuff是只写操作,且不存在写冲突。因此很自然的考虑就是把卷积计算分成ocohow个工作项,每个工作项完成一个输出像素点的卷积计算,通过这样的并行方式加速执行,如下图所示:

const char* programSource =
"__kernel void conv(__global float *covkernel,__global float*img, __global float *out,\n"
"const int kn,const int kc,const int kw,const int kh,const int xw,const int xh,const int oc,const int ow,const int oh){\n"
"int c = get_global_id(0);\n"
"int y = get_global_id(1);\n"
"int x = get_global_id(2);\n"
"int filterOffset=c*kc*kw*kh;\n"
"int outidx=c*ow*oh+y*ow+x;\n"
"float sum=0;\n"
"for(int i=0;i<kc;i++){\n"
" for(int j=0;j<kh;j++){\n"
" for(int k=0;k<kw;k++){\n"
"sum=sum+covkernel[filterOffset+i*kw*kh+j*kw+k]*img[i*xw*xh+j*xw+k+y*xw+x];\n"
"}\n"
" }\n"
"}\n"
"out[outidx]=sum;\n"
"}\n"
;
如上图所示,在内核程序中,通过调用get_global_id函数获得当前工作项的坐标,对应了当前计算的输出像素在输出矩阵中的坐标。通过该坐标我们获取对应的卷积滤波器参数,再从img矩阵中取出对应的像素值。最后进行卷积计算,将计算得到的结果赋值给out[outidx].
4.2 矩阵的实现方式
openCL内核函数对二维矩阵并不支持, 因此我们需要借助一维数组实现多维的矩阵。卷积滤波器convkernel是一个(kn,kc,kh,kw)的4维矩阵,输入图像img是一个(kc,xh,xw)的3维矩阵,输出是一个(oc,oh,ow)的三维矩阵。
- 三维索引
给定坐标c,x,y,我们可以通过三维索引的方式在一维空间上定位对应的坐标值,如下:
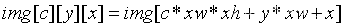
- convkernel
首先计算出滤波器的全局坐标偏移filteroffset,公式如下:
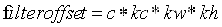
计算出filteroffset之后,我们可以使用三维索引获取对应的像素值。即:
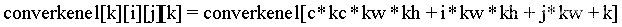
4.3 具体实现
#define CL_TARGET_OPENCL_VERSION 120
#include <CL/cl.h>
#include <stdio.h>
#include <string.h>
#include <malloc.h>
#include <stdlib.h>
#include <iostream>
#include<random>
#include<iomanip>
using namespace std;
//
const char* programSource =
"__kernel void conv(__global float *covkernel,__global float*img, __global float *out,\n"
"const int kn,const int kc,const int kw,const int kh,const int xw,const int xh,const int oc,const int ow,const int oh){\n"
"int c = get_global_id(0);\n"
"int y = get_global_id(1);\n"
"int x = get_global_id(2);\n"
"int filterOffset=c*kc*kw*kh;\n"
"int outidx=c*ow*oh+y*ow+x;\n"
"float sum=0;\n"
"for(int i=0;i<kc;i++){\n"
" for(int j=0;j<kh;j++){\n"
" for(int k=0;k<kw;k++){\n"
"sum=sum+covkernel[filterOffset+i*kw*kh+j*kw+k]*img[i*xw*xh+j*xw+k+y*xw+x];\n"
"}\n"
" }\n"
"}\n"
"out[outidx]=sum;\n"
"}\n"
;
void initarray(float *a,int n){
default_random_engine e;
normal_distribution<float> u(0,1);
for(int i=0;i<n;i++){
a[i]=u(e);
}
}
void showc(float *out,int oc,int oh,int ow){
return ;
for(int c=0;c<oc;c++){
cout<<"channel:"<<c<<endl;
for(int x=0;x<oh;x++){
for(int y=0;y<ow;y++){
cout<<setprecision(4)<<out[c*ow*oh+x*ow+y]<<"\t";
}
cout<<endl;
}
}
}
int main() {
int kn=100,kc=5,kw=13,kh=13;
int xw=1000,xh=1000;
float *kernel=new float[kn*kc*kw*kh];
float *img=new float[kc*xw*xh];
float *out=NULL;
int ow,oc,oh;
oc=kn;
ow=(xw-kw)+1;
oh=(xh-kh)+1;
out=new float[oc*ow*oh];
for(int i=0;i<oc*ow*oh;i++){
out[i]=-1;
}
initarray(kernel,kn*kc*kw*kh);
initarray(img,kc*xw*xh);
initarray(out,oc*ow*oh);
cout<<"初始化检查"<<endl;
showc(out,oc,oh,ow);
// Compute the size of the data
// 用来分配内存
int datasizeK = sizeof(float)*(kn*kc*kw*kh);
int datasizeI = sizeof(float)*(kc*xw*xh);
int datasizeO = sizeof(float)*(oc*ow*oh);
cout<<"数据内存分配正常!"<<endl;
cout<<"获取开始获取平台信息!"<<endl;
cl_int status;
// 获取平台信息
cl_uint numPlatforms = 0;
cout<<"clint status!"<<endl;
// 查询可用的平台个数
status = clGetPlatformIDs(0, NULL, &numPlatforms);
// Allocate enough space for each platform
cout<<"查询平台信息完毕!"<<endl;
cl_platform_id *platforms = NULL;
// 分配内存
cout<<"开始分配平台内存!"<<endl;
platforms = (cl_platform_id*)malloc(numPlatforms * sizeof(cl_platform_id));
// Fill in the platforms
// 得到可用的OpenCL列表
status = clGetPlatformIDs(numPlatforms, platforms, NULL);
cout<<"分配平台内存完毕!"<<endl;
// 获取设备信息
// Retrieve the number of devices
cl_uint numDevices = 0;
// 查询设备数量 OpenCL设备
status = clGetDeviceIDs(platforms[0], CL_DEVICE_TYPE_ALL, 0, NULL, &numDevices);
// Allocate enough space for each device
cl_device_id *devices;
// 分配内存
cout<<"开始分配设备内存!"<<endl;
devices = (cl_device_id*)malloc(numDevices * sizeof(cl_device_id));
cout<<"分配设备内存完毕!"<<endl;
// Fill in the devices
// 得到与platform关联的可用的OpenCL设备
status = clGetDeviceIDs(platforms[0], CL_DEVICE_TYPE_ALL, numDevices, devices, NULL);
cout<<"开始创建上下文!"<<endl;
// 创建上下文信息
// Create a context and associate it with the devices
cl_context context;
context = clCreateContext(NULL, numDevices, devices, NULL, NULL, &status);
char buffer[100];
//查询设备的名称
status=clGetDeviceInfo(devices[0],CL_DEVICE_NAME,100,buffer,NULL);
printf("Device name %s\n",buffer);
//查询设备计算单元数目
cl_uint unitnum;
status=clGetDeviceInfo(devices[0],CL_DEVICE_MAX_COMPUTE_UNITS,sizeof(cl_uint),&unitnum,NULL);
printf("Device units number %d\n",unitnum);
//查询设备核心频率
cl_uint fq;
status=clGetDeviceInfo(devices[0],CL_DEVICE_MAX_CLOCK_FREQUENCY,sizeof(cl_uint),&fq,NULL);
printf("Device frequence %d MHz\n",fq);
// 创建命令队列
// Create a command queue and associate it with the device
cl_command_queue cmdQueue;
// 指定上下文与设备创建
cmdQueue = clCreateCommandQueue(context, devices[0], CL_QUEUE_PROFILING_ENABLE, &status);
// 创建数据内存 内存对象 buffer
// Create a buffer object that will contain the data from the host array A
cout<<"开始分配缓冲区!"<<endl;
cl_mem buf_kn;
// 只读
buf_kn = clCreateBuffer(context, CL_MEM_READ_ONLY, sizeof(int),
NULL, &status);
cl_mem buf_kc;
// 只读
buf_kc = clCreateBuffer(context, CL_MEM_READ_ONLY, sizeof(int),
NULL, &status);
cl_mem buf_kw;
// 只读
buf_kw = clCreateBuffer(context, CL_MEM_READ_ONLY, sizeof(int),
NULL, &status);
cl_mem buf_kh;
// 只读
buf_kh = clCreateBuffer(context, CL_MEM_READ_ONLY, sizeof(int),
NULL, &status);
cl_mem buf_xw;
// 只读
buf_xw = clCreateBuffer(context, CL_MEM_READ_ONLY, sizeof(int),
NULL, &status);
cl_mem buf_xh;
// 只读
buf_xh = clCreateBuffer(context, CL_MEM_READ_ONLY, sizeof(int),
NULL, &status);
cl_mem buf_oc;
// 只读
buf_oc = clCreateBuffer(context, CL_MEM_READ_ONLY, sizeof(int),
NULL, &status);
cl_mem buf_ow;
// 只读
buf_ow = clCreateBuffer(context, CL_MEM_READ_ONLY, sizeof(int),
NULL, &status);
cl_mem buf_oh;
// 只读
buf_oh = clCreateBuffer(context, CL_MEM_READ_ONLY, sizeof(int),
NULL, &status);
cl_mem buf_kernel;
// 只读
buf_kernel = clCreateBuffer(context, CL_MEM_READ_ONLY, datasizeK,
NULL, &status);
// Create a buffer object that will contain the data from the host array B
cl_mem buf_img;
// 只读
buf_img = clCreateBuffer(context, CL_MEM_READ_ONLY, datasizeI,
NULL, &status);
// Create a buffer object that will hold the output data
cl_mem buf_out;
// 只写
buf_out = clCreateBuffer(context, CL_MEM_WRITE_ONLY, datasizeO,
NULL, &status);
// Write input array A to the device buffer bufferA
// 主机端内存数据传入到OpenCL buffer中
status = clEnqueueWriteBuffer(cmdQueue, buf_kn, CL_FALSE,
0, sizeof(int),&kn, 0, NULL, NULL);
status = clEnqueueWriteBuffer(cmdQueue, buf_kc, CL_FALSE,
0, sizeof(int), &kc, 0, NULL, NULL);
status = clEnqueueWriteBuffer(cmdQueue, buf_kw, CL_FALSE,
0, sizeof(int), &kw, 0, NULL, NULL);
status = clEnqueueWriteBuffer(cmdQueue, buf_kh, CL_FALSE,
0, sizeof(int), &kh, 0, NULL, NULL);
status = clEnqueueWriteBuffer(cmdQueue, buf_xw, CL_FALSE,
0, sizeof(int), &xw, 0, NULL, NULL);
status = clEnqueueWriteBuffer(cmdQueue, buf_xh, CL_FALSE,
0, sizeof(int), &xh, 0, NULL, NULL);
status = clEnqueueWriteBuffer(cmdQueue, buf_oc, CL_FALSE,
0, sizeof(int), &oc, 0, NULL, NULL);
status = clEnqueueWriteBuffer(cmdQueue, buf_ow, CL_FALSE,
0, sizeof(int), &ow, 0, NULL, NULL);
status = clEnqueueWriteBuffer(cmdQueue, buf_oh, CL_FALSE,
0, sizeof(int), &ow, 0, NULL, NULL);
status = clEnqueueWriteBuffer(cmdQueue, buf_kernel, CL_FALSE,
0, datasizeK, kernel, 0, NULL, NULL);
// Write input array B to the device buffer bufferB
status = clEnqueueWriteBuffer(cmdQueue, buf_img, CL_FALSE,
0, datasizeI, img, 0, NULL, NULL);
cout<<"缓冲区分配完毕!"<<endl;
// 创建CL程序
// Create a program with source code
// 创建一个OpenCL程序对象
cl_program program = clCreateProgramWithSource(context, 1,
(const char**)&programSource, NULL, &status);
// 编译CL程序
// Build (compile) the program for the device
status = clBuildProgram(program, numDevices, devices,
NULL, NULL, NULL);
// 创建CL内核
// Create the vector addition kernel
cl_kernel ckernel;
ckernel = clCreateKernel(program, "conv", &status);
// 指定每个kernel的参数
// Associate the input and output buffers with the kernel
status = clSetKernelArg(ckernel, 0, sizeof(cl_mem), &buf_kernel);
status = clSetKernelArg(ckernel, 1, sizeof(cl_mem), &buf_img);
status = clSetKernelArg(ckernel, 2, sizeof(cl_mem), &buf_out);
status = clSetKernelArg(ckernel, 3, sizeof(int), &kn);
status = clSetKernelArg(ckernel, 4, sizeof(int), &kc);
status = clSetKernelArg(ckernel, 5, sizeof(int), &kw);
status = clSetKernelArg(ckernel, 6, sizeof(int), &kh);
status = clSetKernelArg(ckernel, 7, sizeof(int), &xw);
status = clSetKernelArg(ckernel, 8, sizeof(int), &xh);
status = clSetKernelArg(ckernel, 9, sizeof(int), &oc);
status = clSetKernelArg(ckernel, 10, sizeof(int), &ow);
status = clSetKernelArg(ckernel, 11, sizeof(int), &oh);
cout<<"参数传递完毕!"<<endl;
size_t globalWorkSize[3];
// There are 'elements' work-items
globalWorkSize[0] = oc;
globalWorkSize[1] = oh;
globalWorkSize[2] = ow;
// 计算,执行kernel
// Execute the kernel for execution
cl_event event;
clEnqueueReadBuffer(cmdQueue, buf_out, CL_TRUE, 0,
datasizeO, out, 0, NULL, NULL);
cout<<"任务提交前检查buffer out:"<<endl;
showc(out,oc,ow,oh);
cout<<"准备提交执行任务!"<<endl;
status = clEnqueueNDRangeKernel(cmdQueue, ckernel, 3, NULL,
globalWorkSize, NULL, 0, NULL, &event);
cout<<"任务执行完毕!"<<endl;
clWaitForEvents(1, &event);
clFinish(cmdQueue);
cout<<"命令执行完毕!"<<endl;
cl_ulong time_start;
cl_ulong time_end;
cout<<"计算执行时间!"<<endl;
clGetEventProfilingInfo(event, CL_PROFILING_COMMAND_START, sizeof(time_start), &time_start, NULL);
clGetEventProfilingInfo(event, CL_PROFILING_COMMAND_END, sizeof(time_end), &time_end, NULL);
double nanoSeconds = time_end-time_start;
printf("OpenCl Execution time is: %0.3f milliseconds \n",nanoSeconds / 1000000.0);//转为毫秒级
// 读取结果,从OpenCL buffer读入主机端内存中
// Read the device output buffer to the host output array
cout<<"任务执行结束检查buffer out:"<<endl;
clEnqueueReadBuffer(cmdQueue, buf_out, CL_TRUE, 0,
datasizeO, out, 0, NULL, NULL);
showc(out,oc,ow,oh);
// Free OpenCL resources
clReleaseKernel(ckernel);
clReleaseProgram(program);
clReleaseCommandQueue(cmdQueue);
clReleaseMemObject(buf_kernel);
clReleaseMemObject(buf_img);
clReleaseMemObject(buf_out);
clReleaseMemObject(buf_kn);
clReleaseMemObject(buf_kc);
clReleaseMemObject(buf_kw);
clReleaseMemObject(buf_kh);
clReleaseMemObject(buf_xw);
clReleaseMemObject(buf_xh);
clReleaseMemObject(buf_oc);
clReleaseMemObject(buf_ow);
clReleaseMemObject(buf_oh);
clReleaseContext(context);
// Free host resources
delete []kernel;
delete []img;
delete []out;
// delete []tmpx;
free(platforms);
free(devices);
return 0;
}
6 实验
6.1 试运行与正确性验证
在Intel DevCloud上输入对应的编译和执行命令,输出以下结果:

6.2 加速性能的分析(单位:ms)
| 卷积滤波器kenerl | 输入img | 串行执行时间 | openCL执行时间 | 加速比 |
|---|---|---|---|---|
| (10,3,7,7) | (3,100,100) | 107 | 0.117 | 914.53 |
| (100,5,13,13) | (5,200,200) | 23896 | 63.42 | 376.79 |
| (100,5,13,13) | (5,300,300) | 55790 | 82.15 | 679.12 |
| (100,5,13,13) | (5,1000,1000) | 648385 | 983.93 | 658.97 |
OpenCL 异构并行计算:原理、机制与优化实践 / 刘文志等著. ——北京:机械工业出版社,2015.12 ↩︎
OpenCL 异构并行编程实战 / (美) 泰(Tay,R.)著;张立浩译 . ——北京:机械工业出版社,2015.9 ↩︎
OpenCL 异构计算/贾斯特(Gaster, R.B)等著; 张云泉等译. ——2版. ——北京:清华大学出版社, 2013 ↩︎
OpenCL 实战 / (美) 斯卡皮诺(Scarpino, M.) 著 ;陈睿译. ——北京: 人民邮电出版社, 2014.7 ↩︎
A. Ajit, K. Acharya and A. Samanta, “A Review of Convolutional Neural Networks,” 2020 International Conference on Emerging Trends in Information Technology and Engineering (ic-ETITE), Vellore, India, 2020, pp. 1-5, doi: 10.1109/ic-ETITE47903.2020.049. ↩︎
Liu B, Zou D, Feng L, Feng S, Fu P, Li J. An FPGA-Based CNN Accelerator Integrating Depthwise Separable Convolution. Electronics. 2019; 8(3):281. https://doi.org/10.3390/electronics8030281 ↩︎
Zhang, Qianru, et al. ‘Recent Advances in Convolutional Neural Network Acceleration’. Neurocomputing, vol. 323, 2019, pp. 37–51, https://doi.org10.1016/j.neucom.2018.09.038. ↩︎















 290
290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









