







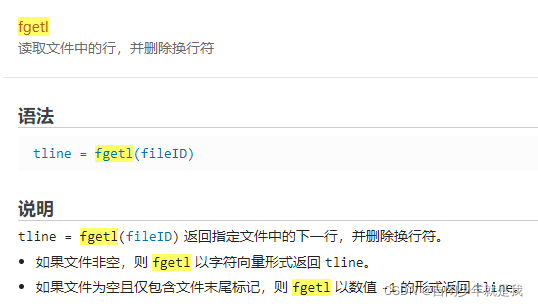
我们着重看一下fgetl的实现,lt返回的是换行符的ASCII代码值,0D0A,所以fgetl是能够返回指定文件的下一行并删除换行符的,fgets读取时会保留换行符。
当textscan和fgetl配合使用的时候,会碰到以下情况,textscan读取数据之后,fgetl再读取数据读出来的是空值。
原因: texscan是一个需要指定格式和调用次数的函数,他对文件的操作并不是以换行符为分界线的,所以fgetl在textscan之后调用时,需要对遗留的换行符进行处理,所以每次fgetl会有一次返回空值的情况。
C = textscan(fileID,formatSpec,N) /*按 formatSpec 读取文件数据 N 次,其中 N 是一个正整数。
要在 N 个周期后从文件读取其他数据,请使用原 fileID 再次调用 textscan 进行扫描。
如果通过调用具有相同文件标识符 (fileID) 的 textscan 恢复文件的文本扫描,则 textscan 将在上次终止读取的点处自动恢复读取*/
function tline = fgetl(fid)
%FGETL Read line from file, discard newline character.
% TLINE  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1559
1559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









