







目录
1.数据抽取
数据分析过程中,并不是所有的数据都是我们想要的,此时可以抽取部分数据,主要使用DataFrame对象的loc属性和iloc属性。
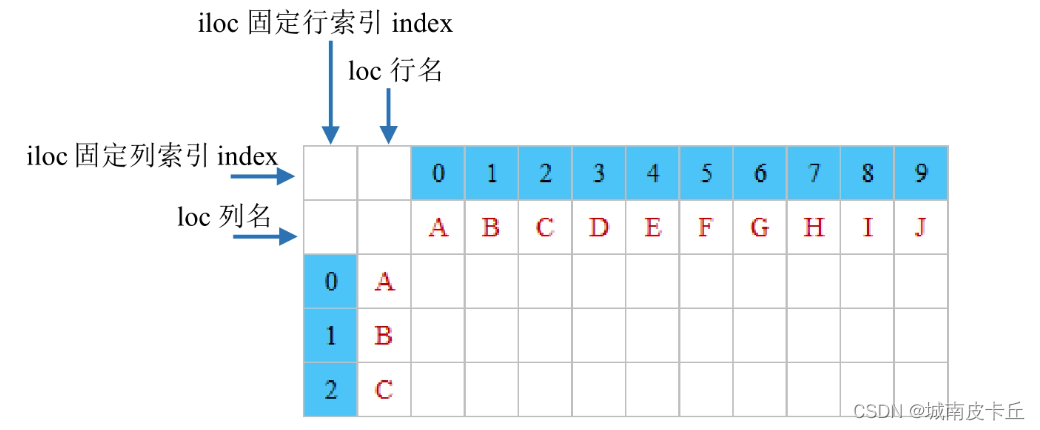
对象的loc属性和iloc属性都可以抽取数据,区别如下
- loc属性:以列名(columns)和行名(index)作为参数,当只有一个参数时,默认是行名,即抽取整行数据,包括所有列,如df.loc['A']
- iloc属性:以行和列位置索引(即0,1,2,…)作为参数,0表示第1行,1表示第2行,以此类推。当只有一个参数时,默认是行索引,即抽取整行数据,包括所有列。如抽取第1行数据,df.iloc[0]
1.1 抽取一行数据
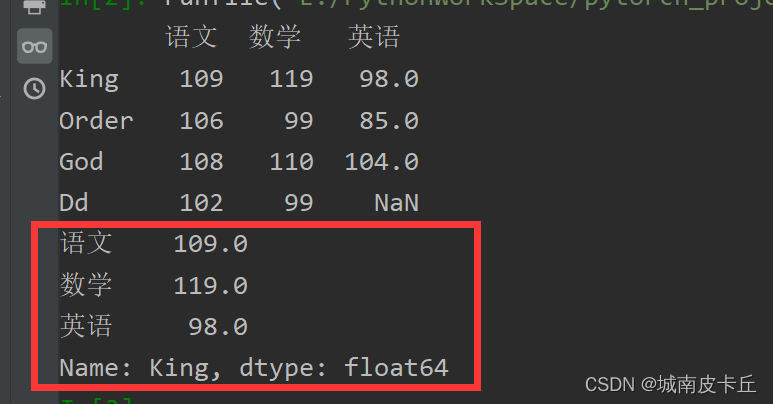
抽取一行数据主要使用loc属性。例如,抽取一行名为“King”的考试成绩数据(包括所有列),程序代码如下:
data=[[109,119,98],[106,99,85],[108,110,104],[102,99]]
name=['King','Order','God','Dd']
columns=['语文','数学',"英语"]
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
print(df.loc['King'])
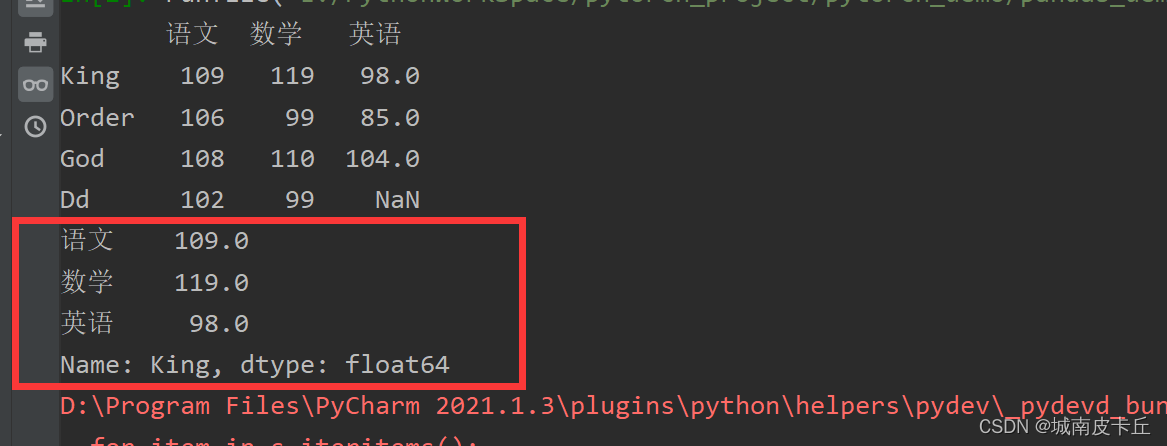
使用iloc属性抽取第1行数据,指定行索引即可,如df.iloc[0],输出结果同上图一样。
data=[[109,119,98],[106,99,85],[108,110,104],[102,99]]
name=['King','Order','God','Dd']
columns=['语文','数学',"英语"]
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
print(df.iloc[0])
1.2 抽取多行数据
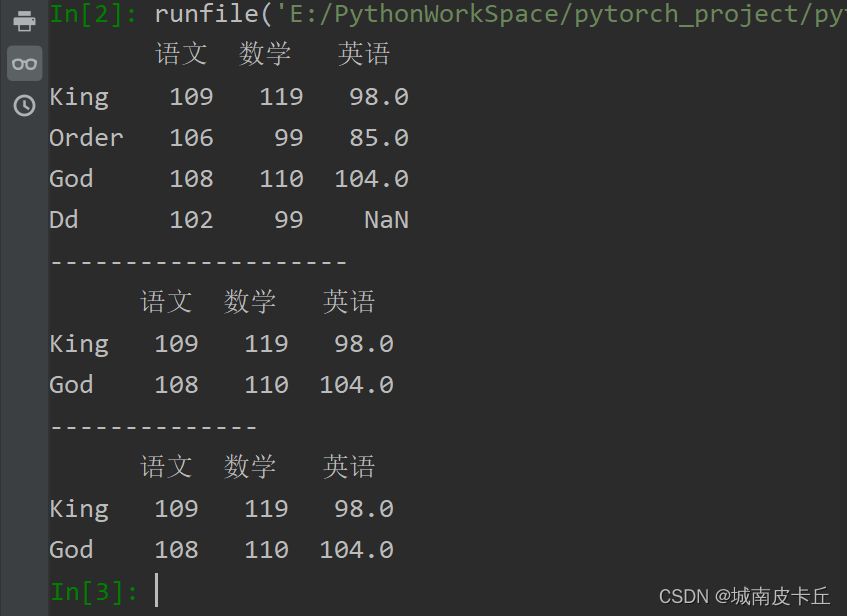
通过loc属性和iloc属性指定行名和行索引即可实现抽取任意多行数据。例如,抽取行名为“King”和“God”(即第1行和第3行数据)的考试成绩数据,可以使用loc属性,也可以使用iloc属性,其输出结果都是一样的,主要代码如下:
data=[[109,119,98],[106,99,85],[108,110,104],[102,99]]
name=['King','Order','God','Dd']
columns=['语文','数学',"英语"]
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
print("--------------------")
print(df.iloc[[0,2]])
print("--------------")
print(df.loc[['King','God']])
在loc属性和iloc属性中合理地使用冒号(:),即可抽取连续任意多行数据
print(df.iloc[0:2])#抽取第一行到第二行
print("--------------")
print(df.loc['King':'God'])#抽取King到God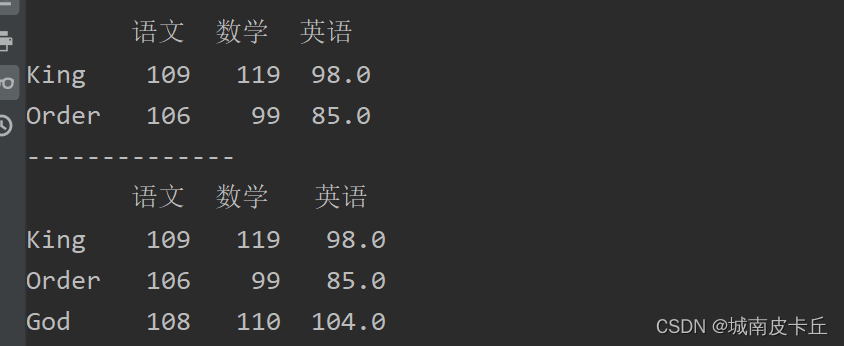
print(df.loc[:'God':])#抽取第一行到God
print("-------------------")
print(df.iloc[1::])#抽取第二行到最后一行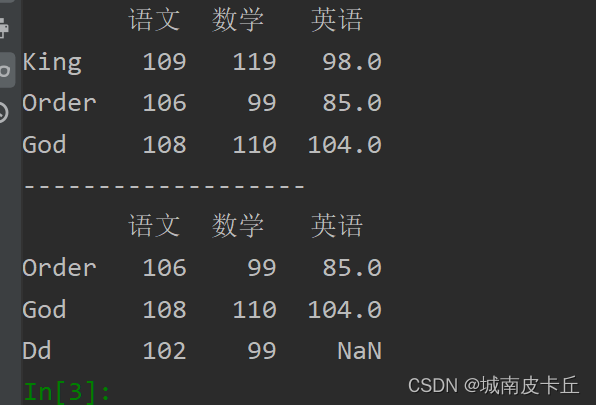
1.3 抽取指定列数据
抽取指定列数据,可以直接使用列名,也可以使用loc属性和iloc属性。
(1)使用列名
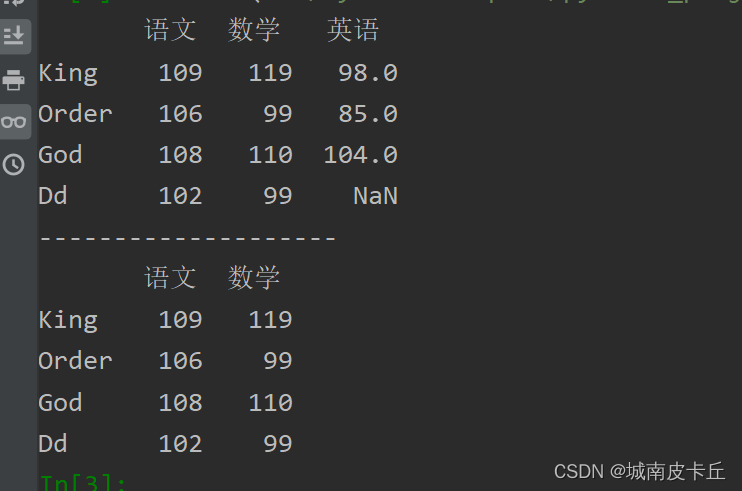
例如,抽取列名为“语文”和“数学”的考试成绩数据,程序代码如下:
data=[[109,119,98],[106,99,85],[108,110,104],[102,99]]
name=['King','Order','God','Dd']
columns=['语文','数学',"英语"]
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
print("--------------------")
print(df[['语文','数学']])
(2)使用loc属性和iloc属性
前面介绍loc属性和iloc属性均有两个参数:第一个参数代表行;第二个参数代表列。那么这里抽取指定列数据时,行参数不能省略。
下面使用loc属性和iloc属性抽取指定列数据,主要代码如下:
data=[[109,119,98],[106,99,85],[108,110,104],[102,99]]
name=['King','Order','God','Dd']
columns=['语文','数学',"英语"]
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
print("--------------------")
print(df.loc[:,['语文','数学']])#抽取语文和数学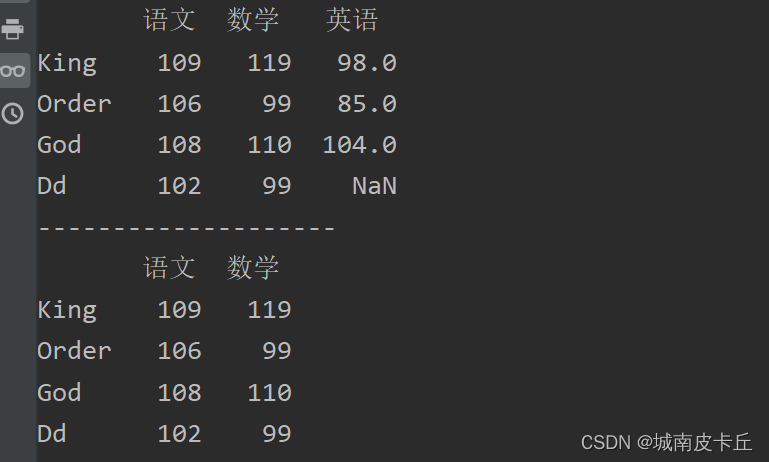
data=[[109,119,98],[106,99,85],[108,110,104],[102,99]]
name=['King','Order','God','Dd']
columns=['语文','数学',"英语"]
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
print("--------------------")
print(df.loc[:,'语文':])#抽取从语文到最后一列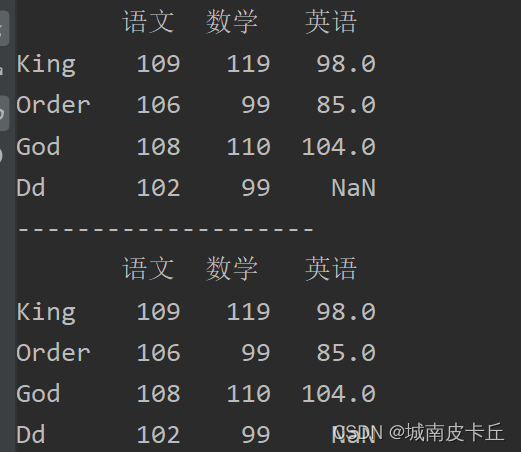
data=[[109,119,98],[106,99,85],[108,110,104],[102,99]]
name=['King','Order','God','Dd']
columns=['语文','数学',"英语"]
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
print("--------------------")
print(df.iloc[:,[0,1]])#抽取第一列和第二列
print("--------------------")
print(df.iloc[:,:2])#连续抽取从第1列开始到第3列,但不包括第3列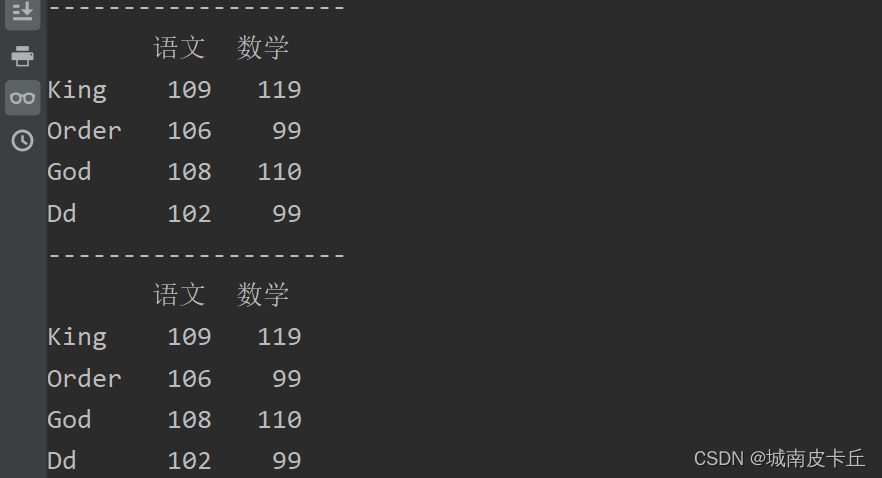
1.4 抽取指定行、列数据
抽取指定行、列数据主要使用loc属性和iloc属性,这两个方法的两个参数都指定就可以实现指定行、列数据的抽取。
使用loc属性和iloc属性抽取指定行、列数据,程序代码如下:
data=[[109,119,98],[106,99,85],[108,110,104],[102,99]]
name=['King','Order','God','Dd']
columns=['语文','数学',"英语"]
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
print("--------------------")
print(df.loc['King','数学'])#抽取King的数学成绩
print("--------------------")
print(df.loc['King',['数学']])#抽取King的数学成绩
print("--------------------")
print(df.loc[['King'],['数学']])#抽取King的数学成绩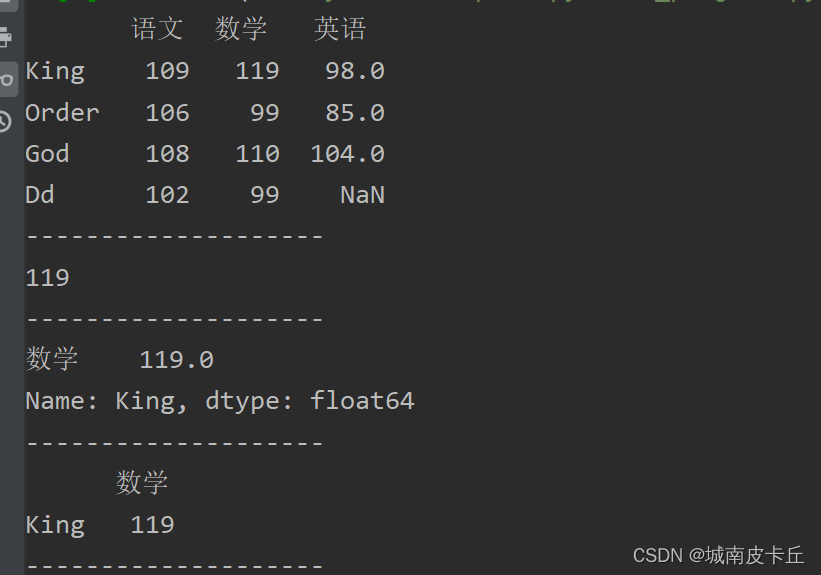
注意,在上述结果中,第一个输出结果是一个数,不是数据,是由于“df.loc['King','数学']”没有使用方括号[],导致输出的数据不是DataFrame类型。
data=[[109,119,98],[106,99,85],[108,110,104],[102,99]]
name=['King','Order','God','Dd']
columns=['语文','数学',"英语"]
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
print("--------------------")
print(df.loc[['Order'],['语文','英语']])#抽取Order的语文和英语成绩
print("--------------------")
print(df.loc[['Order','Dd'],['语文','英语']])#抽取Order、Dd的语文和英语成绩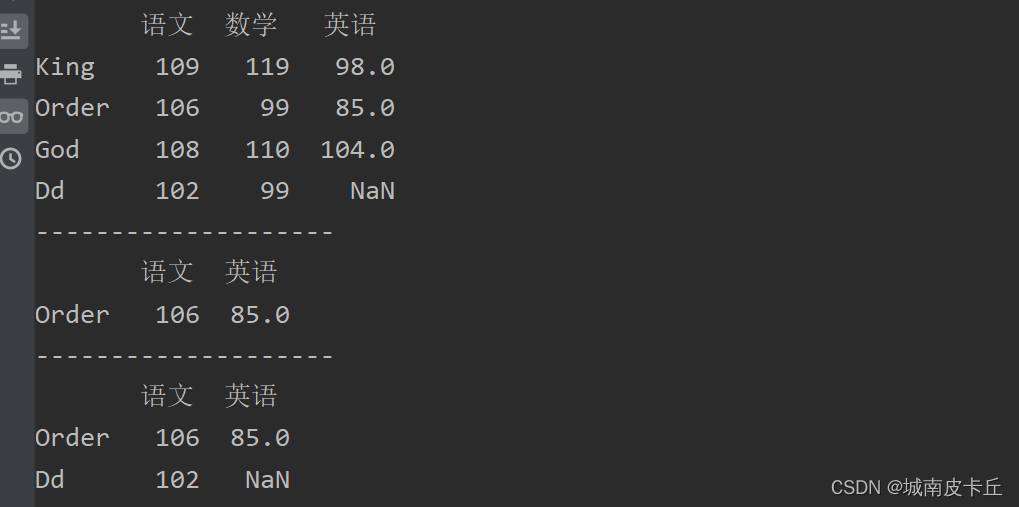
print(df.iloc[[1],[2]])#抽取第二行第三列
print("##################")
print(df.iloc[1,2])#抽取第二行第三列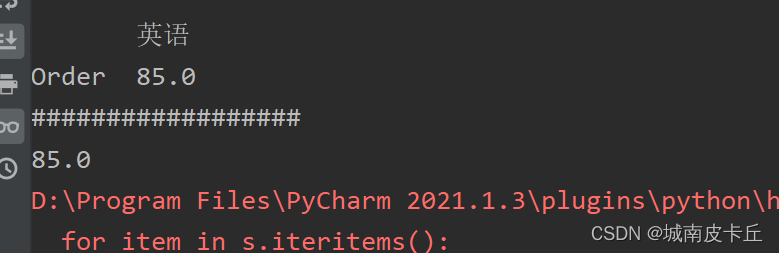
data=[[109,119,98],[106,99,85],[108,110,104],[102,99]]
name=['King','Order','God','Dd']
columns=['语文','数学',"英语"]
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
print("--------------------------")
print(df.iloc[1:,[2]])#抽取第二行到最后一行的第三列
print("##################")
print(df.iloc[1:,[0,2]])#抽取第二行到最后一行的第一、三列
print("-------------")
print(df.iloc[:,2])#所有行第3列语文 数学 英语
King 109 119 98.0
Order 106 99 85.0
God 108 110 104.0
Dd 102 99 NaN
--------------------------
英语
Order 85.0
God 104.0
Dd NaN
##################
语文 英语
Order 106 85.0
God 108 104.0
Dd 102 NaN
-------------
King 98.0
Order 85.0
God 104.0
Dd NaN
Name: 英语, dtype: float64
1.5 按指定条件抽取数据
DataFrame对象实现数据查询有以下3种方式。
- 取其中的一个元素.iat[x,x]
- 基于位置的查询,如.iloc[]、iloc[2,1]
- 基于行、列名称的查询,如.loc[x]
例如,抽取语文成绩大于105,数学成绩大于80的数据,程序代码如下:
data=[[109,119,98],[106,99,85],[108,110,104],[102,99]]
name=['King','Order','God','Dd']
columns=['语文','数学',"英语"]
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
print("========================")
print(df.loc[(df['语文']>105)&(df['数学']>80)])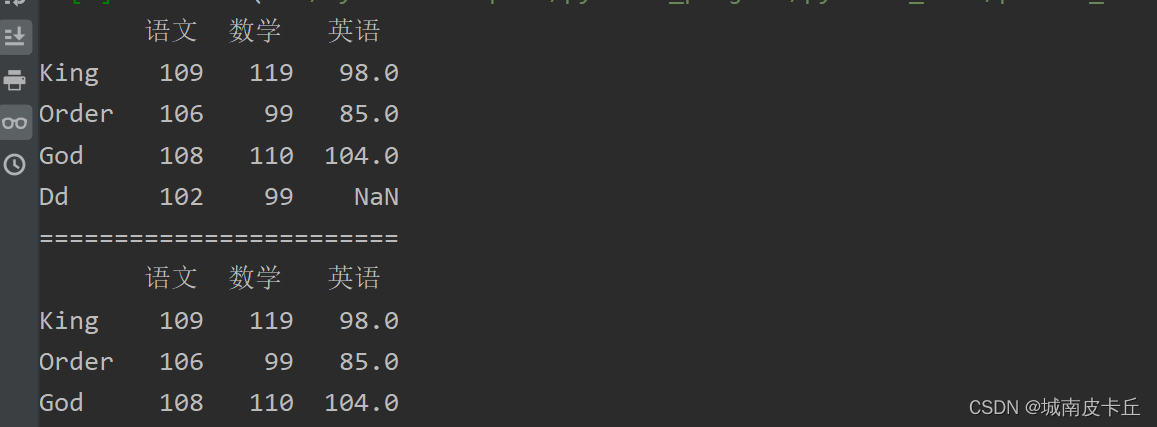
2、数据的增加、删除和修改
2.1 数据增加
DataFrame对象增加数据主要包括列数据增加和行数据增加。首先看一下原始数据
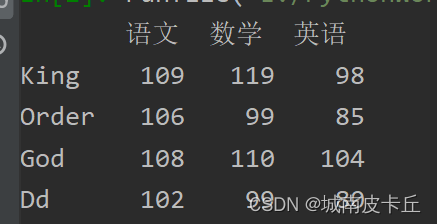
(1)按列增加数据
按列增加数据,可以通过以下3种方式实现:
1、直接为DataFrame对象赋值
例如,增加一列“物理”成绩,程序代码如下:
data=[[109,119,98],[106,99,85],[108,110,104],[102,99,80]]
name=['King','Order','God','Dd']
columns=['语文','数学',"英语"]
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
df['物理']=[90,89,87,99]
print(df)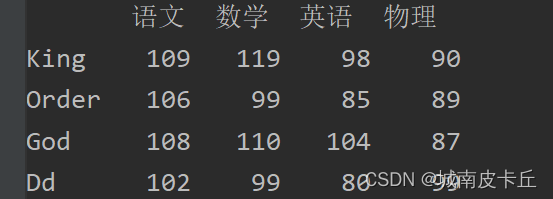
2、使用loc属性在DataFrame对象的最后增加一列
使用loc属性在DataFrame对象的最后增加一列。例如,增加“物理”一列,主要代码如下:
data=[[109,119,98],[106,99,85],[108,110,104],[102,99,80]]
name=['King','Order','God','Dd']
columns=['语文','数学',"英语"]
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
print("-------------")
# df['物理']=[90,89,87,99]
df.loc[:,'物理']=[90,89,87,99]
print(df)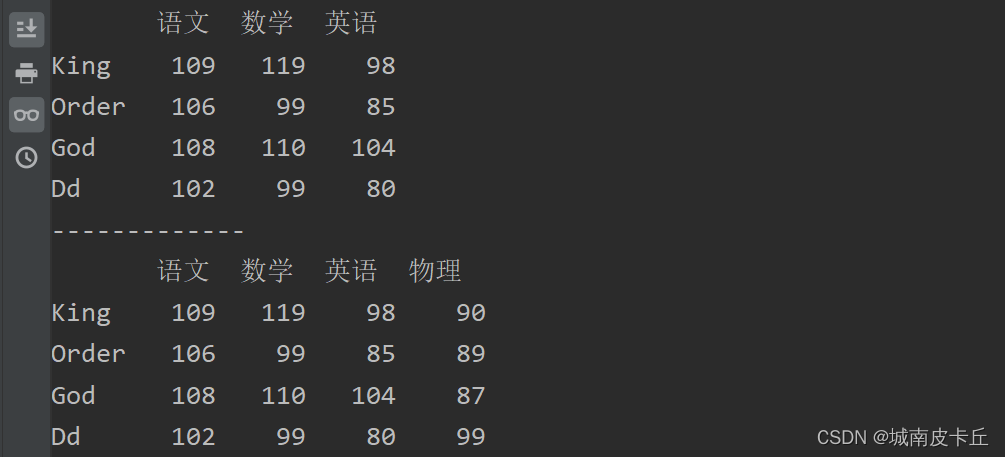
3、在指定位置插入一列
在指定位置插入一列,主要使用insert()方法。例如,在第1列后面插入“物理”,其值为wl的数值,主要代码如下:
wl=[90,89,87,99]
df.insert(1,'物理',wl)
print(df)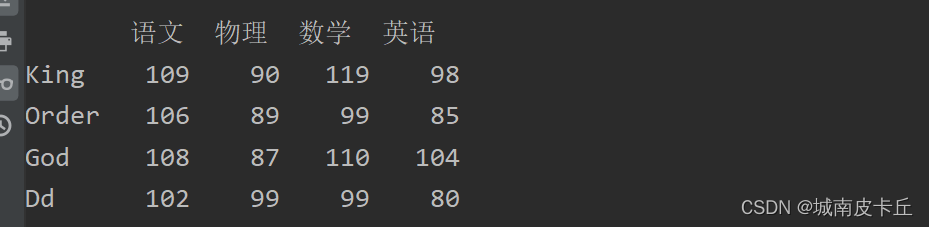
(2)按行增加数据
按行增加数据,可以通过以下两种方式实现。
1.增加一行数据
增加一行数据主要使用loc属性实现。例如,在成绩表中增加一行数据,即“wyy”同学的成绩,主要代码如下:
df.loc['wyy']=[100,109,98]
print(df)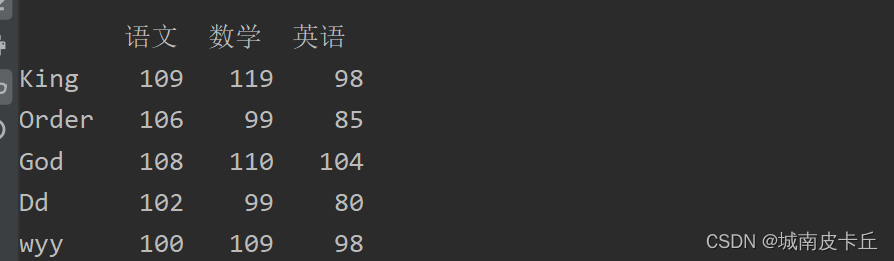
2.增加多行数据
增加多行数据主要使用字典结合append()方法实现。例如,在原有数据中增加“wyy”“wxx”“alan”同学的考试成绩,主要代码如下:
df_insert=pd.DataFrame(
{
'语文':[100,109,101],
'数学':[103,113,93],
'英语':[92,97,99]
},
index=['wyy','wxx','alan']
)
df=df.append(df_insert)
print(df)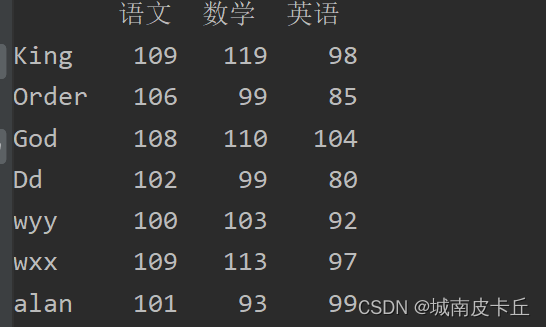
2.2 修改数据
修改数据包括行、列标题和数据的修改,首先看一下原始数据。
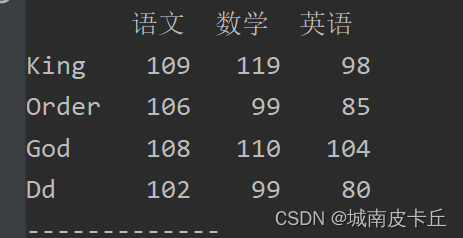
(1)修改列标题
修改列标题主要使用DataFrame对象的cloumns属性,直接赋值即可。
例如,将“数学”修改为“数学(上)”,主要代码如下:
df.columns=['语文','数学(上)','英语']
print(df)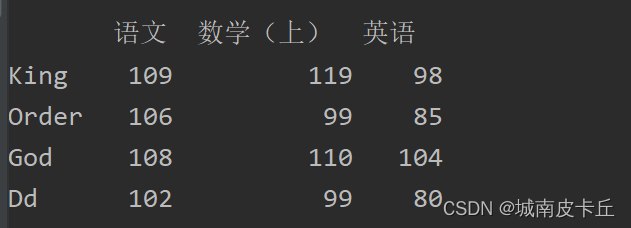
上述代码中,即使只修改“数学”为“数学(上)”,但是也要将所有列的标题全部写上;否则将报错。
有例如,修改多个学科的列名。将“语文”修改为“语文(上)”、“数学”修改为“数学(上)”、“英语”修改为“英语(上)”,主要代码如下:
df.rename(columns={'语文':'语文(上)','数学':'数学(上)','英语':'英语(上)'},inplace=True)
print(df)
上述代码中,参数inplace为True,表示直接修改df;否则,不修改df,只返回修改后的数据。
(2)修改行标题
修改行标题主要使用DataFrame对象的index属性,直接赋值即可。
例如,将行标题统一修改为数字编号。
df.index=list('1234')
print(df)
使用DataFrame对象的rename()方法也可以修改行标题。例如,将行标题统一修改为数字编号,主要代码如下:
df.rename({'King':1,'Order':2,'God':3,'Dd':4},axis=0,inplace=True)
print(df)
(3)修改数据
修改数据主要使用DataFrame对象的loc属性和iloc属性。
1.修改整行数据。例如,例如,修改“King”同学的各科成绩,主要代码如下:
df.loc['King']=[100,100,100]
print(df)
print("-------------------")
df.loc['King']=df.loc['King']#各科成绩均加10分
print(df)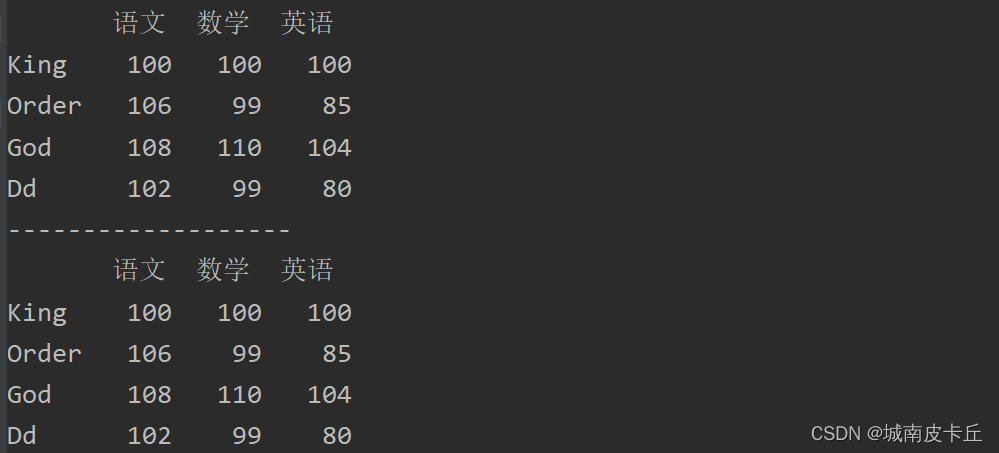
2.修改整列数据
例如,例如,修改所有同学的“语文”成绩,主要代码如下:
df.loc[:,'语文']=[109,103,108,98]
print(df)
3.修改某一数据
例如,修改“King”同学的“语文”成绩,主要代码如下:
df.loc['King','语文']=90
print(df)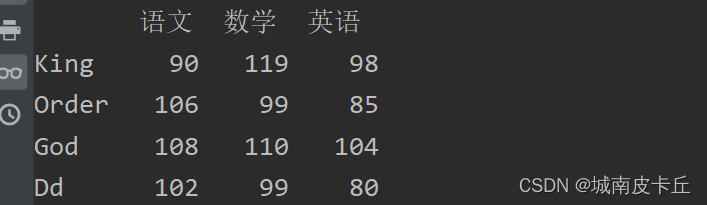
4.使用iloc属性修改数据
通过iloc属性指定行、列位置实现修改数据,主要代码如下:
df.iloc[0,0]=115#修改第一行第一列数据
df.iloc[:,0]=[117,107,103,99]#修改第一列数据
df.iloc[0,:]=[100,100,100]#修改第一行数据
2.3 删除数据
删除数据主要使用DataFrame对象的drop()方法。语法如下
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
- labels:表示行标签或列标签。
- axis:axis = 0,表示按行删除;axis = 1,表示按列删除。默认值为0,即按行删除。
- index:删除行,默认值为None。
- columns:删除列,默认值为None。
- level:针对有两级索引的数据。level = 0,表示按第1级索引删除整行;level = 1表示按第2级索引删除整行,默认值为None。
- inplace:可选参数,对原数组做出修改并返回一个新数组。默认值为False,如果值为True,那么原数组直接就被替换。
- errors:参数值为ignore或raise,默认值为raise,如果值为ignore(忽略),则取消错误。
(1) 除指定的学生成绩数据,主要代码如下:
#删除列名为'数学'的列
df.drop(['数学'],axis=1,inplace=True)
df.drop(columns='数学',inplace=True)
df.drop(labels='数学',axis=1,inplace=True)
df.drop(['God','Dd'],inplace=True)#删除多行
df.drop(index='King',inplace=True)#删除index为'King'的行
df.drop(labels='Order',axis=0,inplace=True)#删除标签为'Order'的行(2)删除特定条件的行
删除满足特定条件的行,首先找到满足该条件的行索引,然后再使用drop()方法将其删除。
例如。删除“数学”成绩中等于110的行、“语文”成绩小于110的行,主要代码如下:
df.drop(index=df[df['数学'].isin([110])].index[0],inplace=True)
#删除“数学”成绩中包含110的行
df.drop(index=df[df['语文']<110].index[0],inplace=True)
#删除“语文”成绩中小于110的行3、数据清洗
3.1 缺失值处理
缺失值是指由于某种原因导致数据为空,这种情况一般有不处理、删除、填充/替换、插值(以均值/中位数/众数等填补)这4种处理方式。
1.查看缺失值
处理缺失值首先需要找到缺失值,主要使用DataFrame对象的info()方法。
df=pd.read_excel(r"C:\Users\zex\Desktop\MR\Code\03\37\TB2018.xls")
print(df)
print("===================")
print(df.info())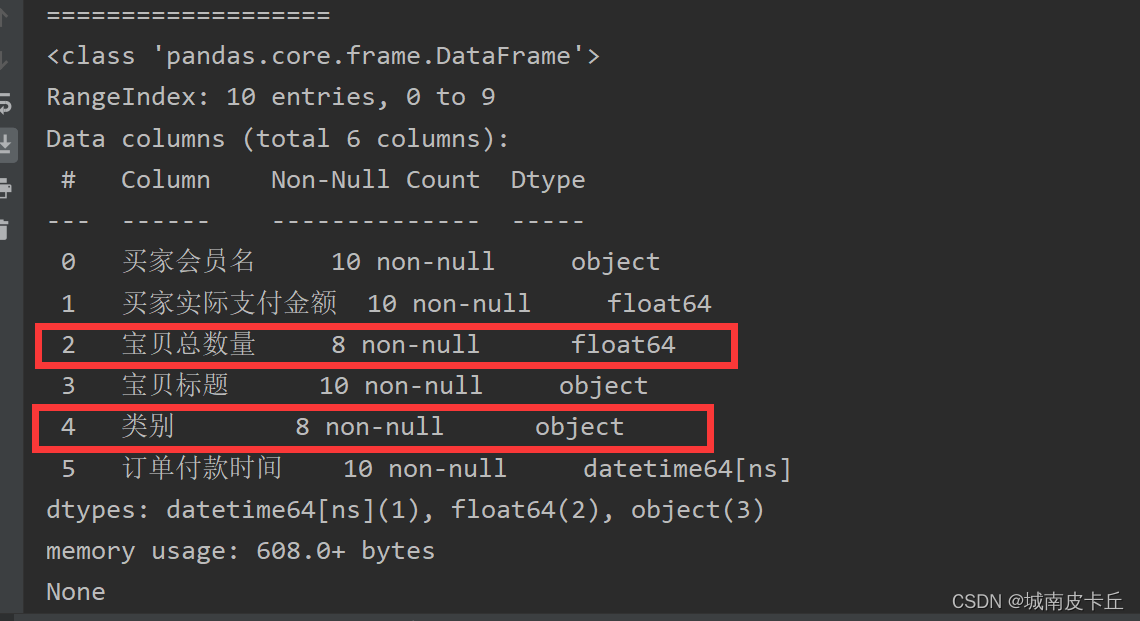
在Python中,缺失值一般用NaN表示,如上图所示。该excel表中有10行数据,而“宝贝总数量”和“类别”的非空数量是8,那么说明这两项存在空值。
判断数据是否存在缺失值还可以使用isnull()方法和notnull()方法,主要代码如下:
print(df.isnull())
print(df.notnull())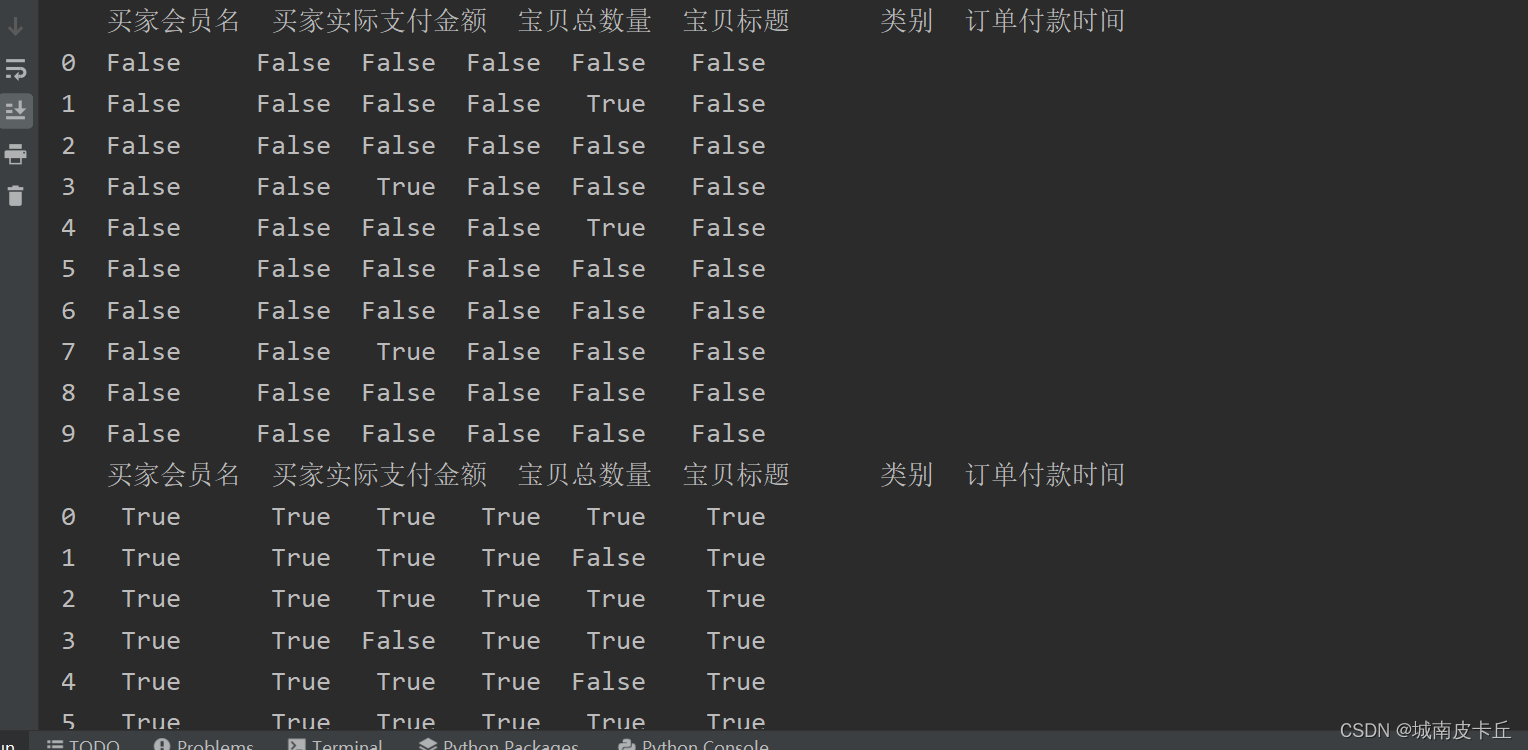
使用isnull()方法缺失值返回True,非缺失值返回False;而notnull()方法与isnull()方法正好相反,缺失值返回False,非缺失值返回True。如果使用df[df.isnull() == False],则会将所有非缺失值的数据找出来,只针对Series对象。
2.缺失值删除处理
通过前面的判断得知数据缺失情况,下面将缺失值删除,主要使用dropna()方法,该方法用于删除含有缺失值的行,主要代码如下:
df1=df.dropna()有些时候数据可能存在整行为空的情况,此时可以在dropna()方法中指定参数how='all',删除所有空行。
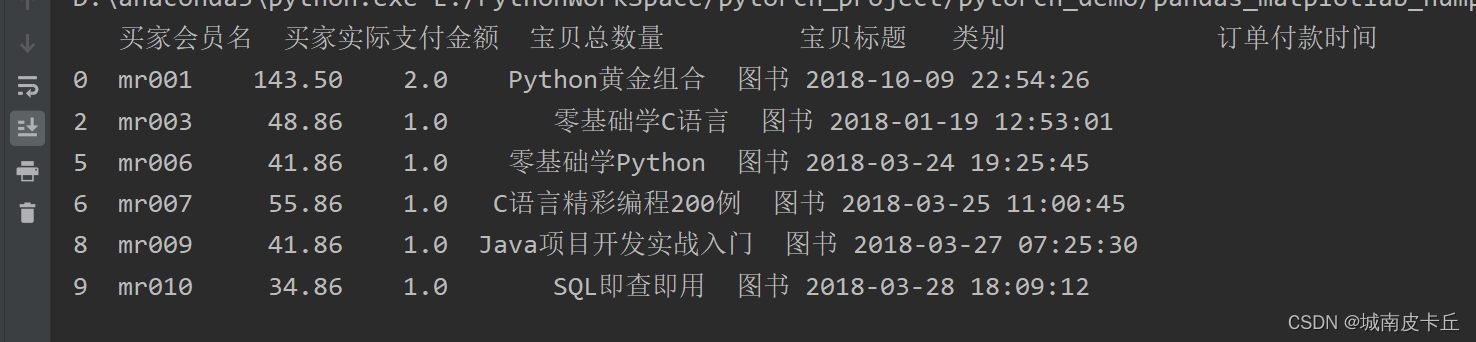
从运行结果得知:dropna()方法将所有包含缺失值的数据全部删除了。那么,此时如果我们认为有些数据虽然存在缺失值,但是不影响数据分析,那么可以使用以下方法处理。例如,上述数据中只保留“宝贝总数量”不存在缺失值的数据,而类别是否缺失不关注,则可以使用notnull()方法判断,主要代码如下:
df2=df[df['宝贝总数量'].notnull()]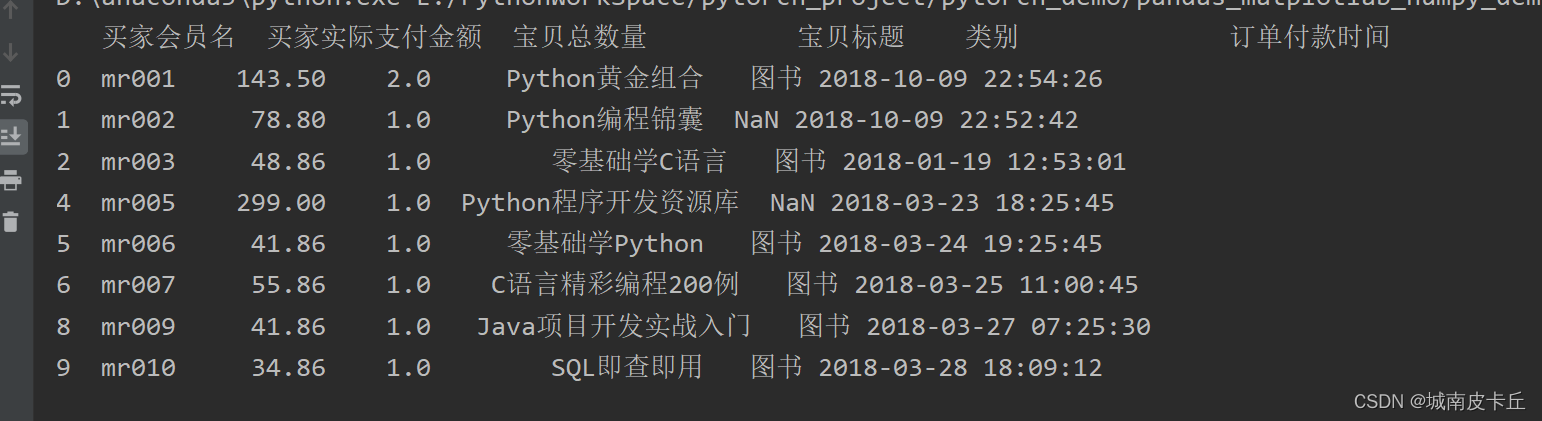
3.缺失值填充处理
对于缺失数据,如果比例高于30%可以选择放弃这个指标,做删除处理;低于30%尽量不要删除,而是选择将这部分数据填充,一般以0、均值、众数(大多数)填充。DataFrame对象中的fillna()函数可以实现填充缺失数据,pad/ffill表示用前一个非缺失值去填充该缺失值;backfill/bfill表示用下一个非缺失值填充该缺失值;None用于指定一个值去替换缺失值。
对于用于计算的数值型数据如果为空,可以选择用0填充。例如,将“宝贝总数量”为空的数据填充为0,主要代码如下:
df["宝贝总数量"]=df["宝贝总数量"].fillna(0)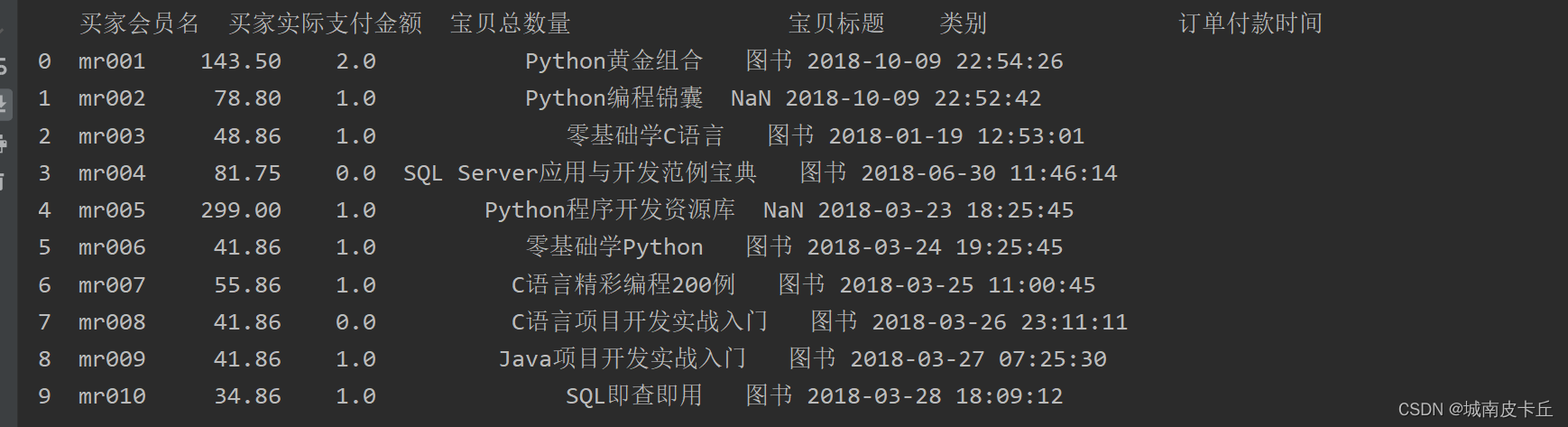
3.2 重复值处理
对于数据中存在的重复数据,包括重复的行或者几行中某几列的值重复一般做删除处理,主要使用DataFrame对象的drop_duplicates()方法。
下面以“1月.xlsx”淘宝销售数据为例,对其中的重复数据进行处理。
(1)判断每一行数据是否重复(完全相同),主要代码如下:
df=pd.read_excel(r"C:\Users\zex\Desktop\MR\Code\03\40\1月.xlsx")
print(df.duplicated())如果返回值为False表示不重复,返回值为True表示重复
(2)去除全部的重复数据,主要代码如下:
df1=df.drop_duplicates()(3)去除指定列的重复数据,主要代码如下
df1.drop_duplicates(['买家会员名'])(4) 保留重复行中的最后一行,主要代码如下:
df1.drop_duplicates(['买家会员名'],keep='last')以上代码中参数keep的值有3个。当keep='first'表示保留第一次出现的重复行,是默认值;当keep为另外两个取值,即last和False时,分别表示保留最后一次出现的重复行和去除所有重复行。
(5)直接删除,保留一个副本,主要代码如下:
df1.drop_duplicates(['买家会员名','买家支付宝账号'],inplace=Fasle)inplace=True表示直接在原来的DataFrame上删除重复项,而默认值False表示删除重复项后生成一个副本
3.3 异常值处理
在数据分析中异常值是指超出或低于正常范围的值,如年龄大于200、身高大于3米、数量为负数等类似数据。那么这些数据如何检测呢?主要有以下几种方法。
(1)根据给定的数据范围进行判断,不在范围内的数据视为异常值。
(2)均方差。在统计学中,如果一个数据分布近似正态分布(数据分布的一种形式,正态分布的概率密度函数曲线呈钟形,两头低、中间高、左右对称),那么大约68%的数据值会在均值的一个标准差范围内,大约95%会在两个标准差范围内,大约99.7%会在3个标准差范围内。
(3)箱形图。箱形图是显示一组数据分散情况资料的统计图。它可以将数据通过四分位数的形式进行图形化描述。箱形图通过上限和下限作为数据分布的边界。任何高于上限或低于下限的数据都可以认为是异常值。
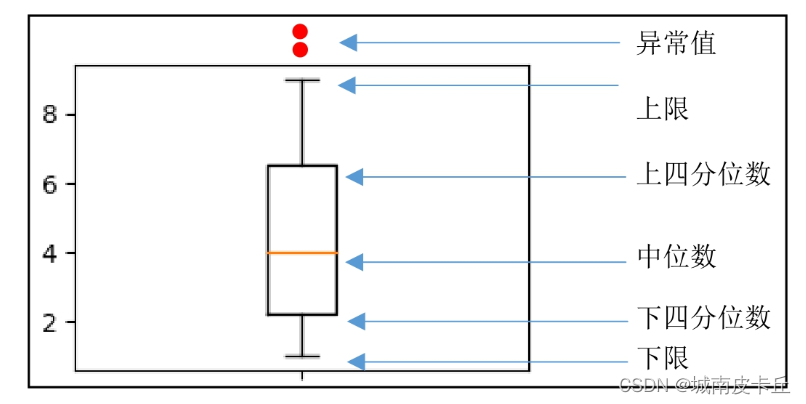
了解了异常值的检测,接下来介绍如何处理异常值,主要包括以下几种处理方式。(1)最常用的方式是删除。(2)将异常值当缺失值处理,以某个值填充。(3)将异常值当特殊情况进行分析,研究异常值出现的原因。
4、索引设置
索引能够快速查询数据,下面介绍索引的作用以及索引的应用。
4.1 索引的作用
索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。Pandas索引的作用如下。
- 更方便查询数据。
- 自动的数据对齐功能,示意图如下图所示
- 使用索引可以提升查询性能。
- 如果索引是唯一的,Pandas会使用哈希表优化,查找数据的时间复杂度为O(1)。
- 如果索引不是唯一的,但是有序,Pandas会使用二分查找算法,查找数据的时间复杂度为O(logN)。
- 如果索引是完全随机的,那么每次查询都要扫描数据表,查找数据的时间复杂度为O(N)。
- 强大的数据结构。
- 基于分类数的索引,提升性能。
- 多维索引,用于groupby多维聚合结果等。
- 时间类型索引,强大的日期和时间的方法支持。
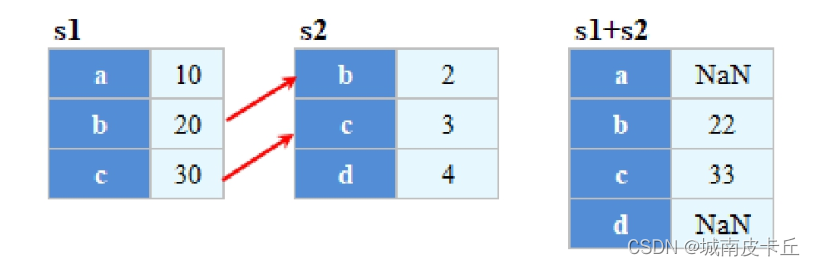
上图数据对齐效果实现代码如下:
s1 = pd.Series([10,20,30],index= list("abc"))
s2 = pd.Series([2,3,4],index=list("bcd"))
print(s1 + s2)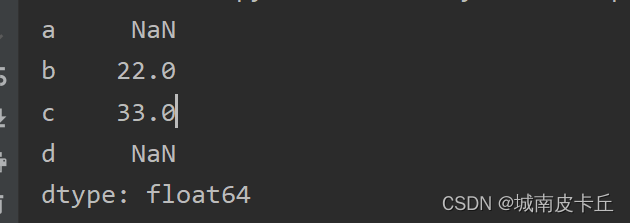
4.2 重新设置索引
Pandas有一个很重要的方法是reindex(),它的作用是创建一个适应新索引的新对象。语法如下:
DataFrame.reindex(labels = None,index = None,
columns = None,axis = None,method = None,copy = True,
level =None,fill_value = nan,limit = None,tolerance = None)常用参数说明:
- labels:标签,可以是数组,默认值为None(无)。
- index:行索引,默认值为None。
- columns:列索引,默认值为None。
- axis:轴,axis=0表示行,axis=1表示列。默认值为None。
- method:默认值为None,重新设置索引时,选择插值(一种填充缺失数据的方法)方法,其值可以是None、bfill/backfill(向后填充)、ffill/pad(向前填充)等。
- fill_value:缺失值要填充的数据。如缺失值不用NaN填充,而用0填充,则设置fill_value=0即可。
1.对Series对象重新设置索引
s1=pd.Series([12,13,57],index=[1,2,3])
print(s1)
print("=====================")
print(s1.reindex([1,2,3,4,5]))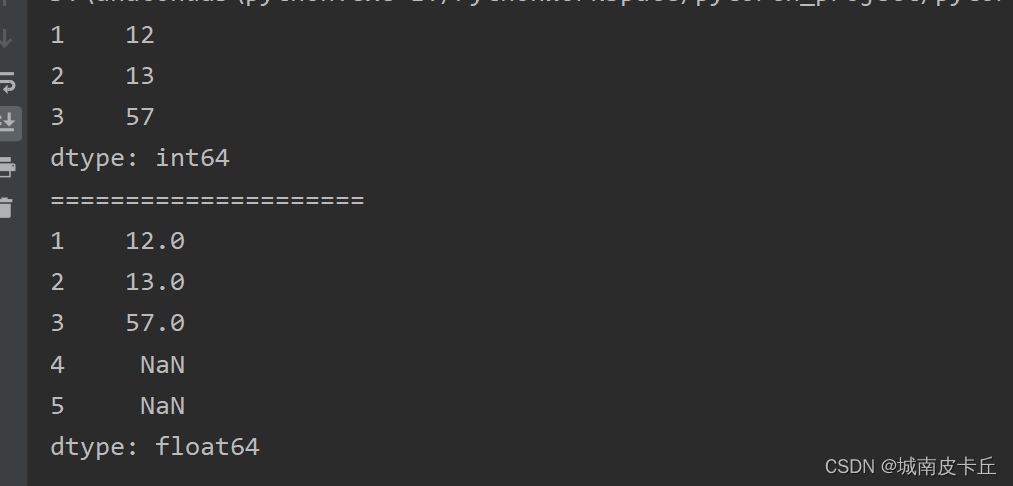
从运行结果得知:reindex()方法根据新索引进行了重新排序,并且对缺失值自动填充NaN。如果不想用NaN填充,则可以为fill_value参数指定值,如0,主要代码如下:
s1.reindex([1,2,3,4,5],fill_value=0)而对于一些有一定顺序的数据,我们可能需要插值(插值是一种填充缺失数据的方法)来填充缺失的数据,可以使用method参数。
向前填充(和前面数据一样)、向后填充(和后面数据一样),主要代码如下:
01 print(s1.reindex([1,2,3,4,5],method='ffill')) #向前填充
02 print(s1.reindex([1,2,3,4,5],method='bfill')) #向后填充s1=pd.Series([12,13,57],index=[1,2,3])
print(s1)
print("=====================")
print(s1.reindex([1,2,3,4,5],method='ffill'))
print("++++++++++++++")
print(s1.reindex([0,1,2,3,4],method="bfill"))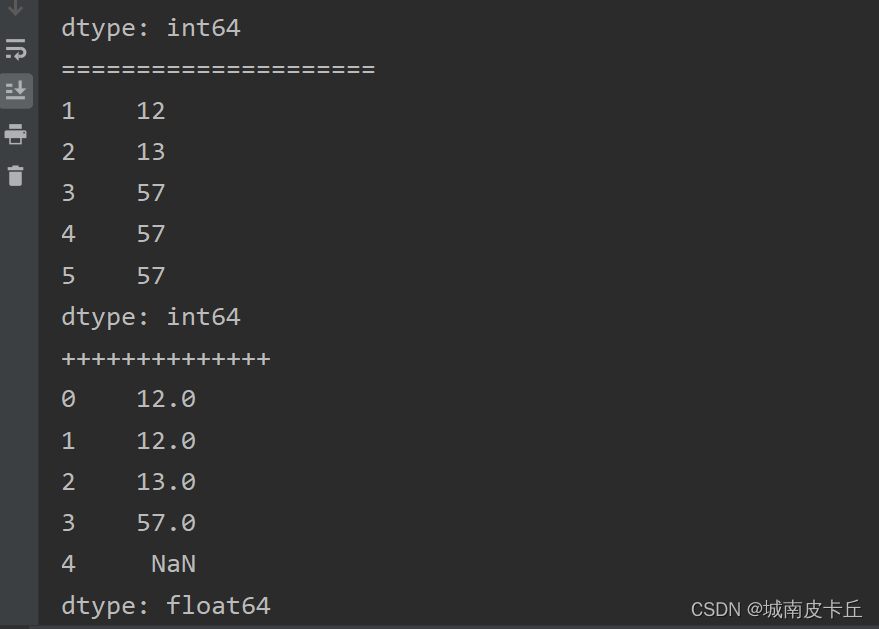
2.对DataFrame对象重新设置索引
5、数据排序、数据排名
















 1219
1219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











