










一:前期代码准备
从GitCode(服务器在国内,访问比较快)中将开源代码copy下来
地址:mirrors / junyanz / pytorch-cyclegan-and-pix2pix · GitCode
也可从github源项目地址中获取:GitHub - junyanz/pytorch-CycleGAN-and-pix2pix: Image-to-Image Translation in PyTorch
二:数据集准备
2.1.使用官网提供的数据集
2.1.1.在Ubuntu中通过shell命令下载
以下载maps数据集为例,在终端输入以下命令:
bash ./datasets/download_cyclegan_dataset.sh maps2.1.2.直接从源地址中下载
打开开源代码中datasets文件夹中的download_cyclegan_dataset.sh文件,复制URL中的前半段网址打开http://efrosgans.eecs.berkeley.edu/cyclegan/datasets/
打开后就可以下载你想下的任何数据集了
2.2.使用自己制作的数据集
选出训练集(A、B)和测试集(A、B),然后按照下图文件夹进行命名,最后将制作的数据集放入datasets文件夹中即可
三:初始化环境
以conda用户为例,在项目目录中使用如下命令进行环境配置(以后的操作都是基于这个虚拟环境)
conda env create -f environment.yml这里我修改了environment.yml文件,将创建出的虚拟环境重命名为cycleGAN
注意:一定要根据自己cuda的版本号选择合适的pytorch版本,不然后续更改会很麻烦!!!
创建成功后,使用如下命令即可进入conda创建出的虚拟环境:
conda activate cycleGAN此外,通过pip等方式也可进行初始化,具体详见原网站说明
PS:如果环境配置有问题想删了重新安装,使用如下命令:
1.首先退出当前环境
conda deactivate
2.删除自己刚创建的虚拟环境
conda remove -n xxx --all
四:训练数据
4.1.前期准备
首先,打开options文件夹,在base_options.py文件中可以进行基础配置的更改。
例如gpu_ids,默认为0,即使用第一个GPU进行训练;‘-1’是使用CPU进行训练。也可以设置batch_size(默认为1)等等
在train_options.py文件中可以设置epochs的大小以及保存模型的频率等等
4.2.安装visdom(可视化)
visdom 是Facebook 为PyTorch 打造的一款可视化工具,可以实时的对数据进行可视化显示,比如模型loss值的变化、生成的图像等等
下面在conda环境中对其进行安装
conda install visdom
安装完成后,通过如下命令即可开启visdom服务
python -m visdom.server启动成功后,终端会显示以下网址:http://localhost:8097,打开网址即可看到训练数据的实时展示

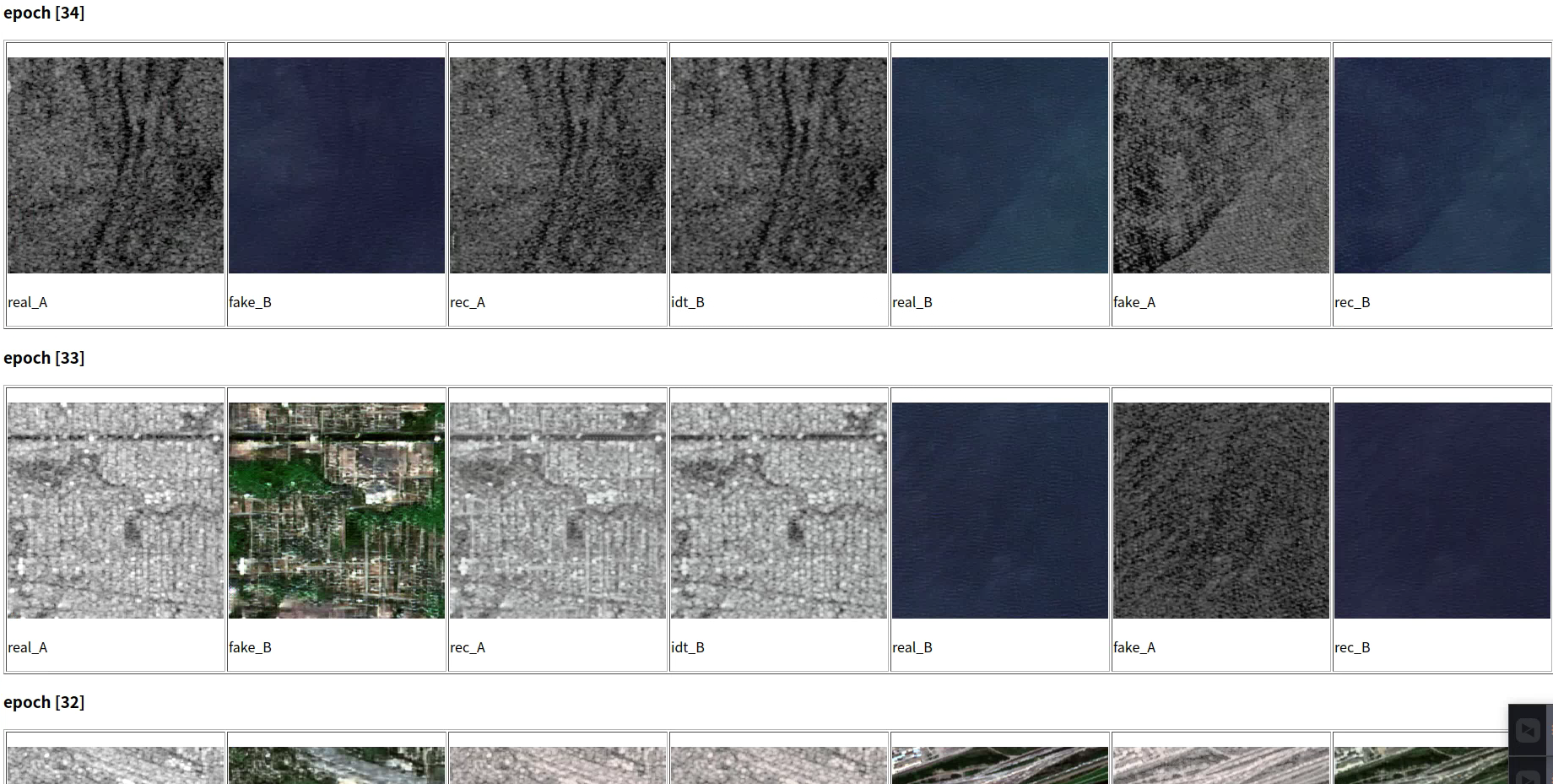
同时,如果想看到更加详细的生成图像结果,就在主文件夹下打开以下路径./checkpoints/maps_cyclegan/web/index.html,效果展示如下图所示
注意:如果visdom端口被占用时,除了在配置文件中更改端口外,还可以通过以下命令:
查看当前正在进行进程的端口号以及PID:
netstat -tunlp
kill跟visdom相关的那个进程(默认端口号8097):
kill -9 xxxx(PID)
4.3.开始训练
打开终端,进入cycleGAN虚拟环境,然后输入如下命令
python train.py --dataroot ./datasets/sar2optical --name sar2optical_cyclegan --model cycle_gan如果训练pix2pix模型,则输入以下命令:
python train.py --dataroot ./datasets/sar2optical --name sar2optical_pix2pix --model pix2pix --direction AtoBAtoB表示由A数据集训练生成B数据集
其中,sar2optical换成自己设置的数据集名称
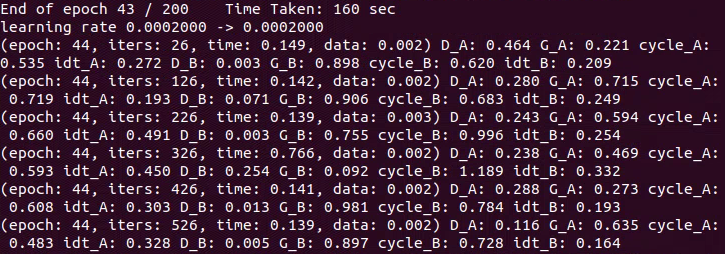
注意:刚开始可能会报错PyTorch与CUDA版本不匹配,这时需要去官网https://pytorch.org/get-started/previous-versions/下载合适的pytorch版本
此外,要恢复之前的训练,可以使用--continue_train标志。程序将根据epoch加载模型。默认情况下,该程序将把epoch计数初始化为1,同时设置--epoch_count <int>可以来指定不同的起始epoch
五:测试数据
结束训练之后,使用如下命令对数据集进行测试
python test.py --dataroot ./datasets/sar2optical --name sar2optical_cyclegan --model cycle_gan测试结果保存在主目录下的一个html文件中./results/sar2optical_cyclegan/test_latest/index.html
部分测试结果:


此外,我还测试了下monet2photo:
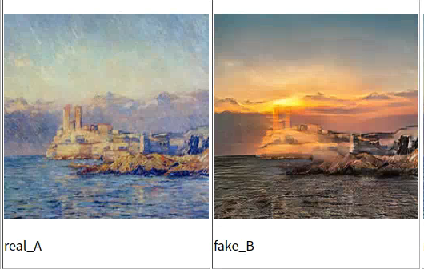

以及horse2zebra:


整体效果还是不错的~

















 547
547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









