







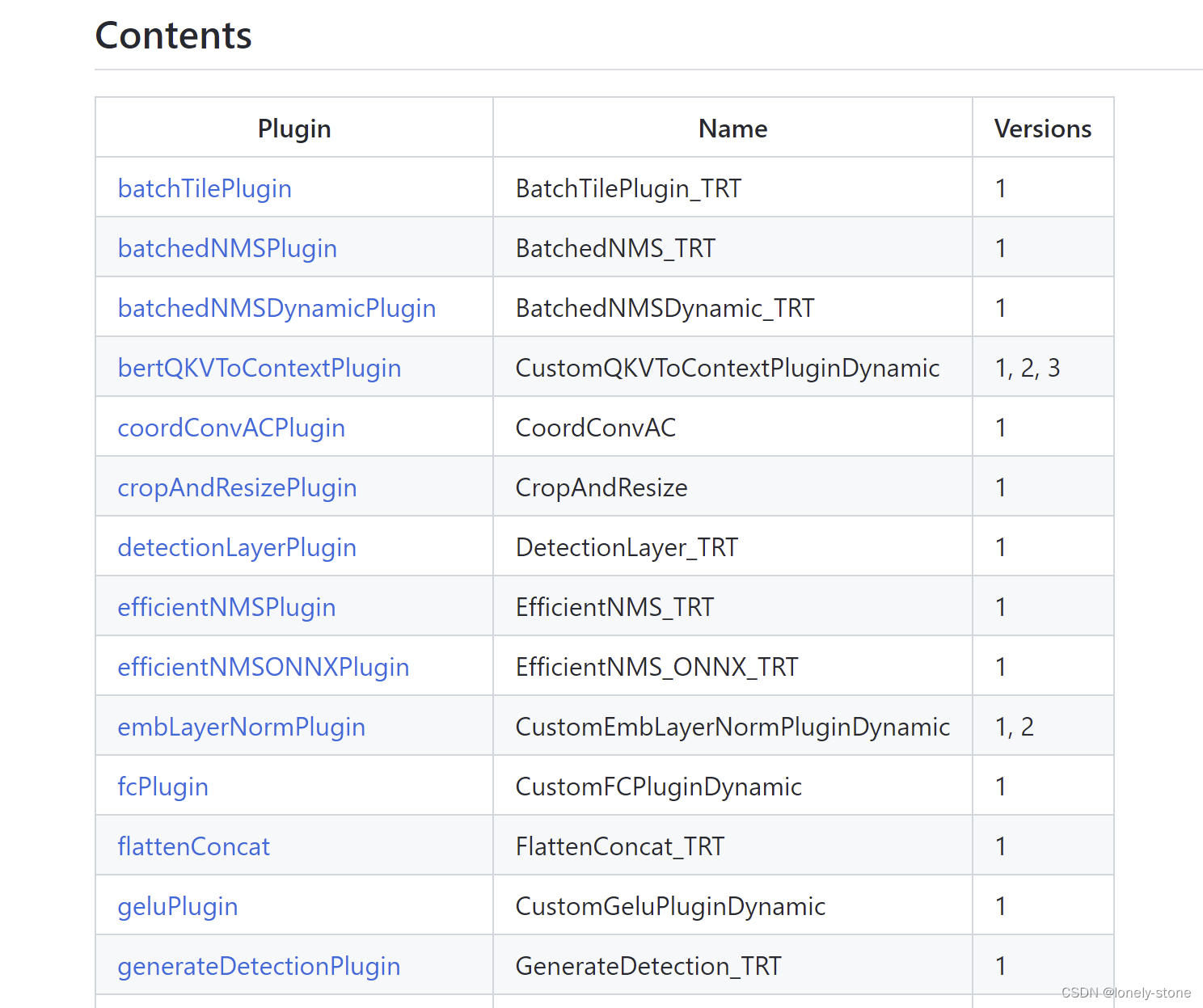
1. TensorRT Plugin介绍
Plugin 存在的意义:
- TRT支持的算子有限,实现不支持的算子;
- 进行深度优化-合并算子,把简单的多个kernel合并成一个kernel。
官网给的TRT支持的算子(比较少):

同时官方github也给出了很多plugin demo,大都跟计算机视觉和BERT模型相关。
TensorRT version 8.2
TensorRT Plugin的工作流程:

2. plugin的编写
plugin分为两种:
- Dynamic Shape:输入维度是动态的;
- Static Shape:输入维度是定死的。
编写plugin,需要继承TRT的base class;
- Static Shape,用IPluginV2IOExt;
- Dynamic Shape,则使用IPluginV2DynamicExt。
Static Shape Plugin API
// 用于network definition阶段,PluginCreator创建该插件时调用的构造函数,需要传递权重信息以及参数。
// 也可用于clone阶段,或者再写一个clone构造函数
MyCustomPlugin(int in_channel, nvinfer1::Weights const& weight, nvinfer1::Weights const& bias);
// 用于在deserialize阶段,用于将序列化好的权重和参数传入该plugin并创建
MyCustomPlugin(void const* serialData, size_t serialLength);
// 注意需要把默认构造函数删掉:
// MyCustomPlugin() = delete;
// 析构函数则需要执行terminate,terminate函数就是释放这个op之前开辟的一些显存空间:
// MyCustomPlugin::~MyCustomPlugin() {
// terminate();
// }
//-------上面是构造和析构函数,接下来是输出函数-------
// 获得layer的输出个数
int getNbOutputs() const;
// 根据输入个数和输入维度,获得第index个输出的维度
nvinfer1::Dims getOutputDimensions(int index, const nvinfer1::Dims* inputs, int nbInputDims);
// 根据输入个数和输入类型,获得第index个输出的类型
nvinfer1::DataType getOutputDataType(int index, const nvinfer1::DataType* inputTypes, int nbInputs) const;
//-------序列化和反序列化相关函数-------------------
// 返回序列化时需要写多少字节到buffer中
size_t getSerializationSize() const;
// 序列化函数,将plugin的参数权值写入到buffer中
void serialize(void* buffer) const;
// 获得plugin的type和version,用于反序列化使用
const char* getPluginType() const;
const char* getPluginVersion() const;
// --------------初始化、配置、销毁函数----------
// 初始化函数,在这个插件准备开始run之前执行。一般申请权值显存空间并copy权值
int initialize();
// terminate函数就是释放initialize开辟的一些显存空间
void terminate();
// 释放整个plugin占用的资源
void destroy();
// 配置这个插件plugin op,判断输入和输出类型数量是否正确
void configurePlugin(const nvinfer1::PluginTensorDesc* in, int nbInput, const nvinfer1::PluginTensorDesc* out, int nbOutput);
// 判断pos索引的输入/输出是否支持inOut[pos].format和inOut[pos].type指定的格式/数据类型
bool supportsFormatCombination(int pos, const nvinfer1::PluginTensorDesc* inOut, int nbInputs, int nbOutputs) const;
// -----------运行相关函数------------------
// 获得plugin所需要的显存大小。最好不要在plugin enqueue中使用cudaMalloc申请显存(因为malloc是不会去看
// 剩余显存大小的,所以可能会显存溢出,二是能进行显存复用)。
size_t getWorkspaceSize(int maxBatchSize) const;
// inference函数
int enqueue(int batchSize, const void* const* inputs, void** outputs, void* workspace, cudaStream_t stream);
// ----------------IPluginCreator 相关函数----------
// 获得pluginname和version,用于辨识creator
const char* getPluginName() const;
const char* getPluginVersion() const;
// 通过PluginFieldCollection去创建plugin将op需要的权重和参数一个一个取出来,然后调用上文提到的第一个构造函数:
const nvinfer1::PluginFieldCollection* getFieldNames();
nvinfer1::IPluginV2* createPlugin(const char* name, const nvinfer1::PluginFieldCollection*
fc);
// 反序列化,调用反序列化那个构造函数,生成plugin
nvinfer1::IPluginV2* deserializePlugin(const char* name, const void* serialData, size_t
serialLength);
Dynamic Shape Plugin API
跟 static shape 相比有差异的函数
// static implicit(隐式) batch VS dynamic explicit(显式) batch
// 1. 根据输入个数和动态输入维度,获得第index个输出的动态维度
// static
nvinfer1::Dims getOutputDimensions(int index, const nvinfer1::Dims* inputs, int nbInputDims);
// dynamic
nvinfer1::DimsExprs getOutputDimensions(int outputIndex, const nvinfer1::DimsExprs* inputs,
int nbInputs, nvinfer1::IExprBuilder& exprBuilder);
//2. enqueue和getWorkspaceSize多了输入输出的信息、维度类型等
// static
int enqueue(int batchSize, const void* const* inputs, void** outputs, void* workspace, cudaStream_t stream);
// dynamic
int enqueue(const nvinfer1::PluginTensorDesc* inputDesc, const nvinfer1::PluginTensorDesc* outputDesc,const void* const* inputs, void* const* outputs, void* workspace, cudaStream_t stream);
3. PluginCreator 注册
在加载NvInferRuntimeCommon.h头文件时,会得到一个getPluginRegistry,这里类中包含了所有已经
注册了的IPluginCreator,在使用的时候通过getPluginCreator函数得到相应的IPluginCreator。
两种注册方式,本质上一样
// 1. 调用API进行注册
extern "C" TENSORRTAPI nvinfer1::IPluginRegistry* getPluginRegistry();
getPluginRegistry()->registerCreator(*pluginCreator, libNamespace);
// 2. 直接通过REGISTER_TENSORRT_PLUGIN来注册:
class PluginRegistrar {
public:
PluginRegistrar() { getPluginRegistry()->registerCreator(instance, ""); }
private:
T instance{};
};
如何使用注册好的PluginCreator
class IPluginRegistry {
public:
virtual bool registerCreator(IPluginCreator& creator, const char* pluginNamespace) noexcept = 0;
//!
//! \brief Return all the registered plugin creators and the number of
//! registered plugin creators. Returns nullptr if none found.
//!
virtual IPluginCreator* const* getPluginCreatorList(int* numCreators) const noexcept = 0;
virtual IPluginCreator* getPluginCreator(const char* pluginType, const char* pluginVersion, const char* pluginNamespace = "") noexcept = 0;
4. TensorRT 如何 debug
TRT是闭源软件,API相对比较复杂。
- 无论是使用API还是parser构建网络,模型转换完后,结果误差很大,怎么办?
- 增加了自定义plugin 实现算子合并,结果对不上,怎么办?
- 使用FP16 or INT8优化策略后,算法精确度掉了很多,怎么办?
推荐几种debug方法
- 使用parser转换网络,使用dump API接口,查看网络结构是否对的上;
- 使用了plugin,要写单元测试;
- 通用办法,打印输出
(1)官方建议:将可疑层的输出设置为network output(比较累);
(2)网上方法:增加一个debug plugin。(https://github.com/LitLeo/TensorRT_Tutorial
下的master/视频版资料/打造自己的plugin库示例-debug_plugin)















 3455
3455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









