







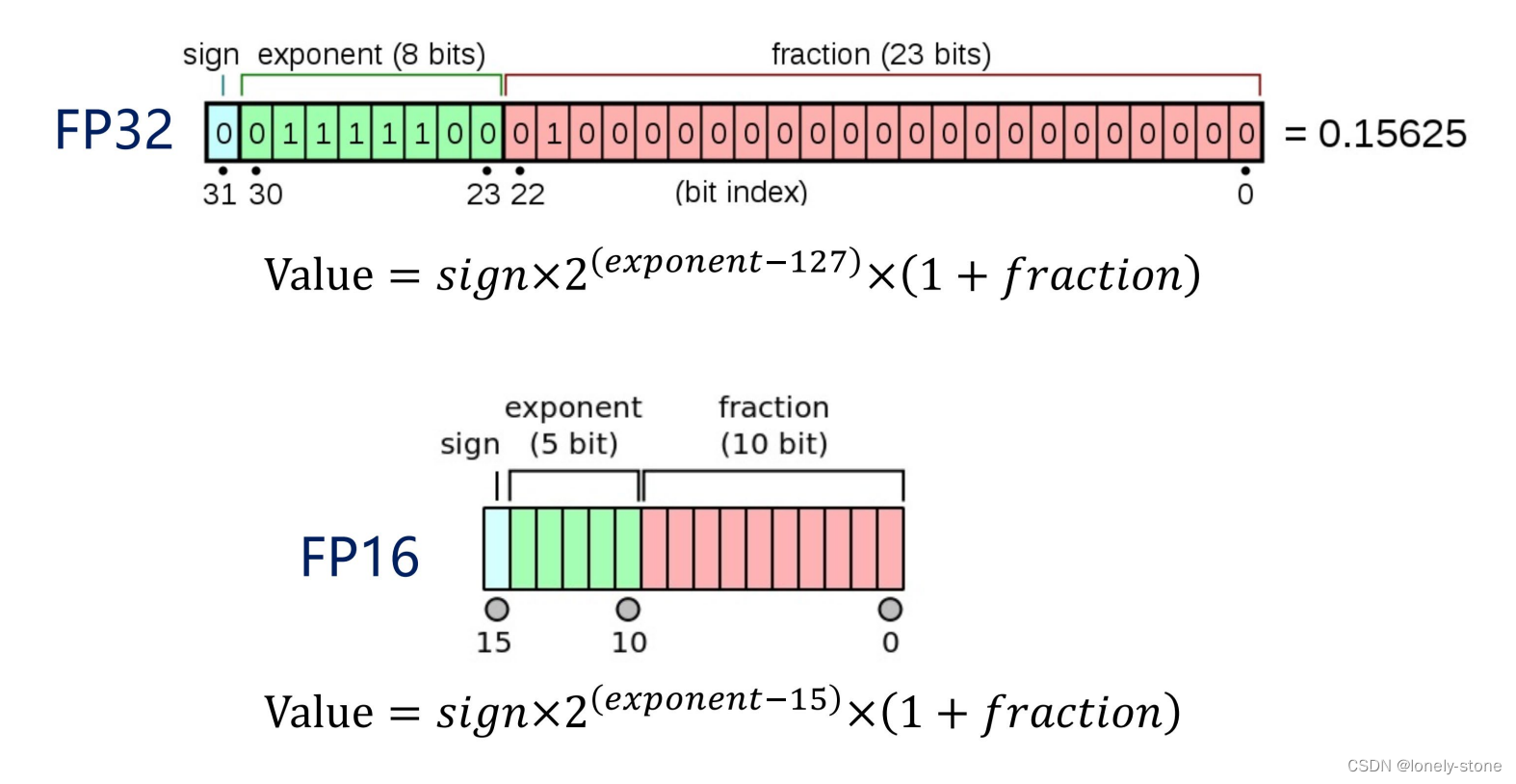
1. TensorRT FP16优化加速
FP32数据切割成FP16,会损失一定精度
加速方式:
config->setFlag(BuilderFlag::kFP16);
builder->platformHasFastFp16() builder->platformHasFastInt8()
2. INT8量化算法
(1)什么是INT8量化?
将基于浮点的模型转换成低精度的int8(char or uchar)数值进行运算,以加快推理速度。
主要是针对的矩阵相乘和卷积操作
(2)为什么INT8量化会快?
(a)对于计算能力大于等于SM_61的显卡,如Tesla P4/P40 GPU,NVIDIA提供了新的INT8点乘运算
的指令支持-DP4A。该计算过程可以获得理论上最大4倍的性能提升。
(b)Volta架构中引入了Tensor Core也能加速INT8运算
FP16 和 INT8能加速的本质:
通过指令 或者 硬件技术,在单位时钟周期内,
FP16 和 INT8 类型的运算次数 大于 FP32 类型的运算次数。
(3)为什么INT8量化不会大幅损失精度?
(a)神经网络的特性:具有一定的鲁棒性。
原因:训练数据一般都是有噪声的,神经网络的训练过程就是从噪声中识别出有效的信息。
思路:可以将低精度计算造成的损失理解为另一种噪声
(b)神经网络权值,大部分是正态分布,值域小且对称
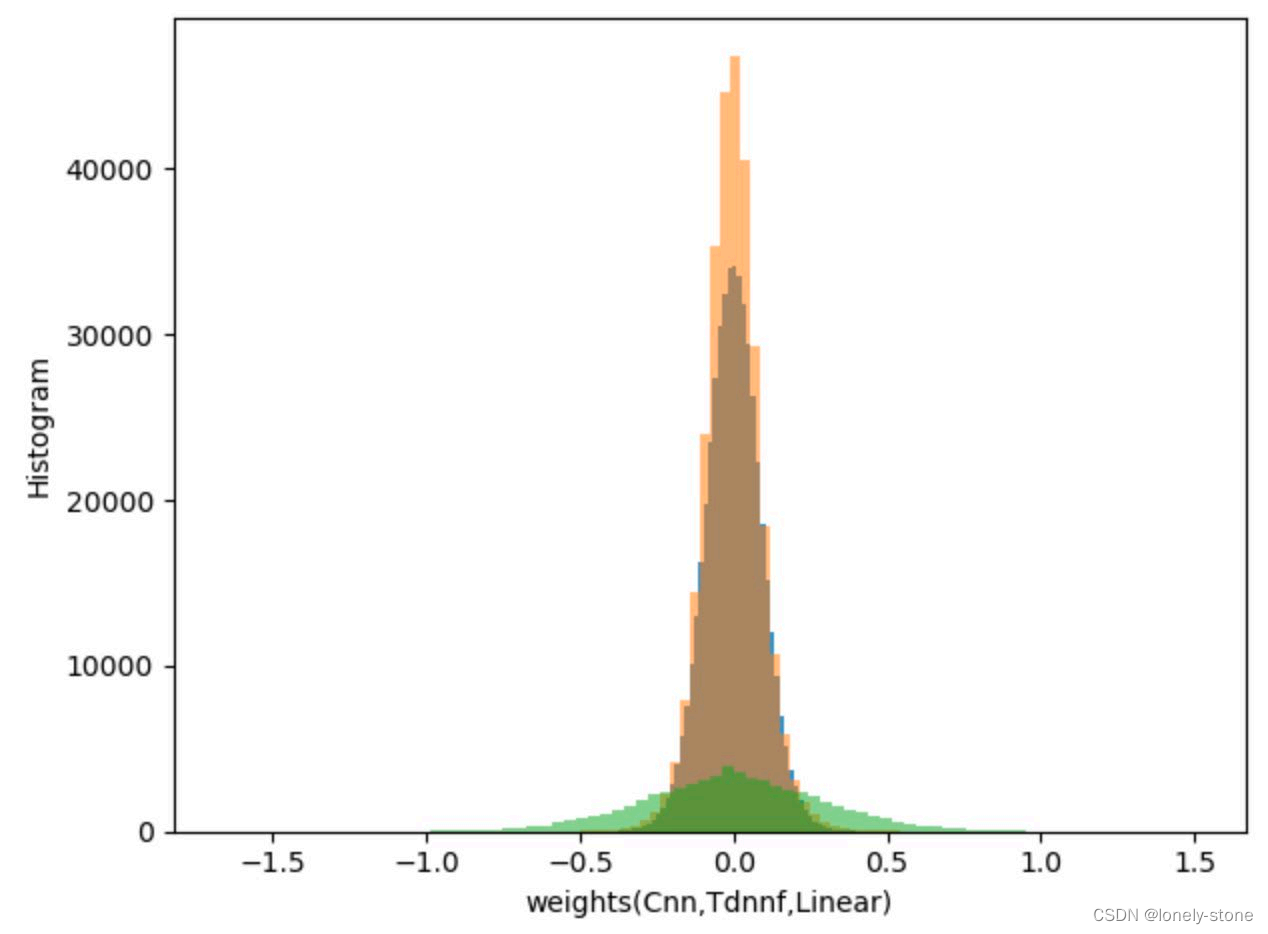
(4)INT8量化算法
动态对称量化算法 使用于:
(1)PyTorch dynamic quantization
(2)ONNX quantization
主要使用在server端模型大的。
动态非对称量化算法 使用于
(1)Google Gemmlowp
主要使用在ARM的嵌入式端
静态对称量化算法 使用于
(1)PyTorch static quantization
(2)TensorRT
(3)NCNN
3. 三种INT8量化算法介绍
(1)动态对称量化算法
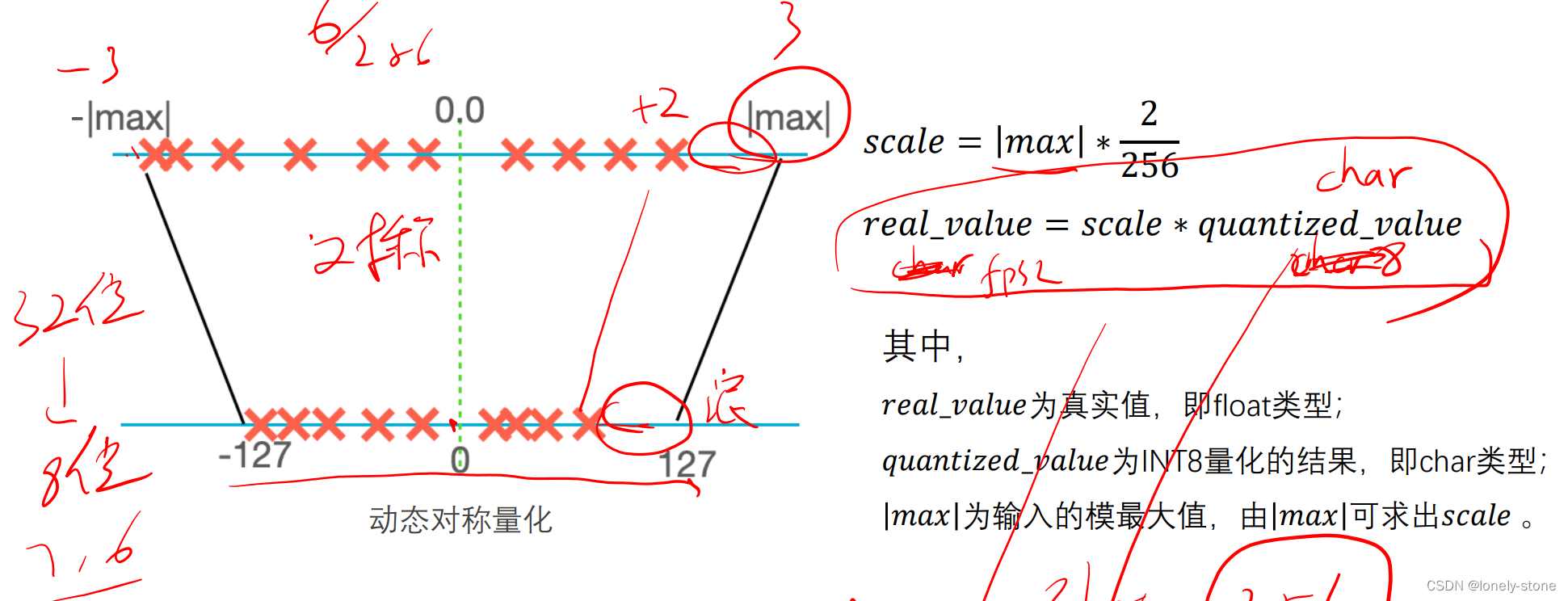
优点:算法简单,量化步骤耗时时间短;
缺点:会造成位宽浪费,影响精度。
(2)动态非对称量化算法
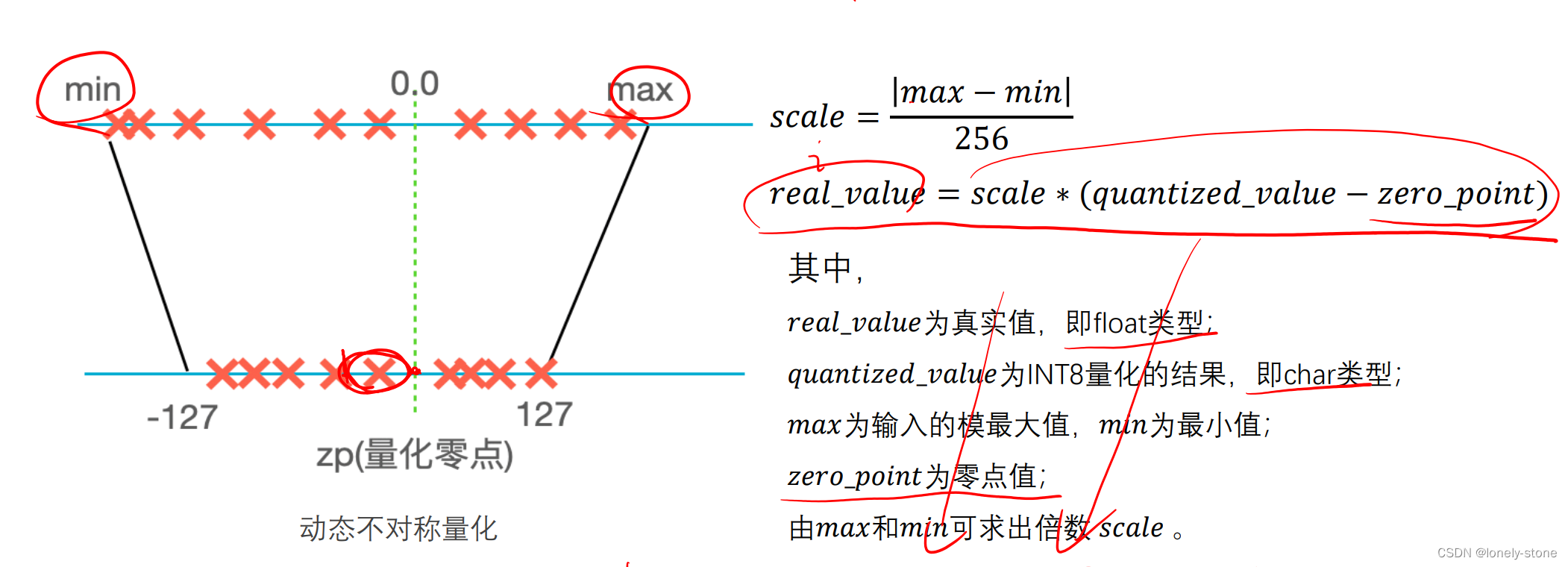
优点:不会造成bit位宽浪费,精度有保证;
缺点:算法较复杂,量化步骤耗时时间长。
具体的量化步骤(图中可以看出过程相当复杂):

(3)静态对称量化算法
动态量化,推理时实时统计数值|max|
静态量化,推理时使用预先统计的缩放阈值,截断部分阈值外的数据
优点:算法最简单,量化耗时时间最短,精度也有所保证;
缺点:构建量化网络比较麻烦
INT8就一定快吗?
Float 运算时间 Tfloat
低精度运算时间Tint8
输入量化运算时间 Tquant
输出反量化时间 Tdequant
INT8 性能收益 = Tfloat – Tint8 – Tquant – Tdequant
经验:
权值越大,输入越小,加速比越大。
输入越大,收益越小,甚至负收益
4. TRT使用
(1)对于深度神经网络的推理,TRT可以充分发挥GPU计算潜力,以及节省GPU存储单元空间。
(2)对于初学者,建议先从Sample入手,尝试替换掉已有模型,再深入利用网络定义API尝试搭建
网络。
(3)如果需要使用自定义组件,建议至少先了解CUDA基本架构以及常用属性。
(4)推荐使用FP16/INT8计算模式
• FP16只需定义很少变量,明显能提高速度,精度影响不大;
• Int8有更多的潜力,但是可能会导致精度下降。
(5)如果不是非常了解TRT,也可以尝试使用集成了TRT的框架,但是如果不支持的网络层太多,
会导致速度下降明显。
(6)在不同架构的GPU或者不同的软件版本的设备上,引擎不能通用,要重新生成一个。
















 2020
2020











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









