






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转自|视觉算法
1. Basic

上面左图是2D卷积神经网络,其输入是4行4列的矩阵,通过卷积核逐步移动实现对整个输入的卷积操作;而右图输入是图网络,其结构和连接是不规则的,无法像卷积神经网络那样实现卷积操作,由此提出图卷积网络。
以Zachary’s Karate Club社群为例,其结构如下图所示:
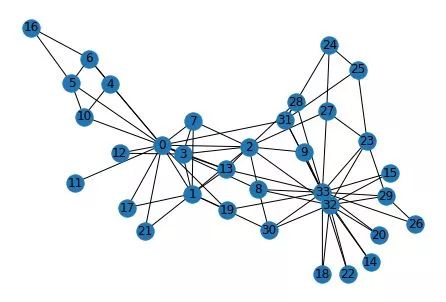
即总共是0~33共34个node,代表34个人,两个node如果有线段连接代表两者关联,否则无关联;这34个人被分为两类,分别是“Officer”和“Mr. Hi”;为便于查看整个网络中每个人与其他人的关联关系,重构关联图如下:
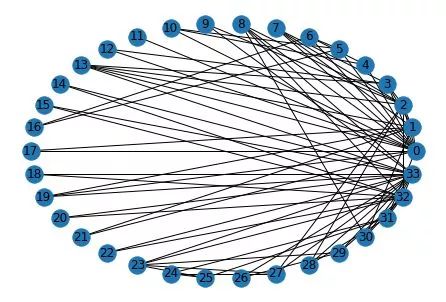
基于上图结构,定义矩阵A(其shape=[34,34])如下, 每一行代表一个Node;

A[0] =[0., 1., 1., 1., 1., 1., 1., 1., 1., 0., 1., 1., 1., 1., 0., 0., 0., 1., 0., 1., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],代表第0个node与第1、2、3、4、5、6、7、8、10、11、12、13、17、19、21、31个node关联;
A[11] = [1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0.],代表第11个node只与第0个node关联;
A[12] = [1., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],代表第12个node只与第0、3个node关联;
定义矩阵X(其shape=[34, k],如k=3),每一行代表一个node的3个特征;其初始值随机生成;
定义矩阵W(其shape=[k, 1]),随机参数矩阵;
类别(Label):node[0, 1, 2, 3, 4, 5, 6, 7, 8, 10, 11, 12, 13, 16, 17, 19, 21]是“Mr. Hi”;node[9, 14, 15, 18, 20, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33]是“Officer”;
图卷积网络的propagation如下:
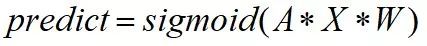
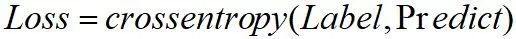
图卷积网络可用于特征表征,即最小化Loss,更新矩阵X和W,其中矩阵X的每一行即为对应node的特征,这和word2vec模型很像。
模型地址:https://zhuanlan.zhihu.com/p/88757091
2. More
矩阵A的每一行表示的关联点并不包含其自身,为更好的表达网络结构,定义矩阵AI
AI = A + eye(34);
矩阵AI中值为1.0多的行比少的行在propagation中意味着更大的值,训练时不稳定,容易造成梯度爆炸,由此引入对角矩阵D;
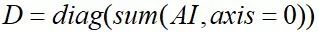
则图卷积网络的propagation修改为:
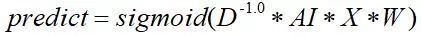
该式后又优化为:
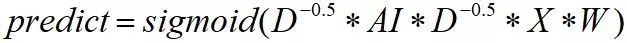
Notes:D是对角矩阵,此处定义其0元素的负k(k=1.0, 0.5)次方仍是0;
优化前后两者的区别在于:
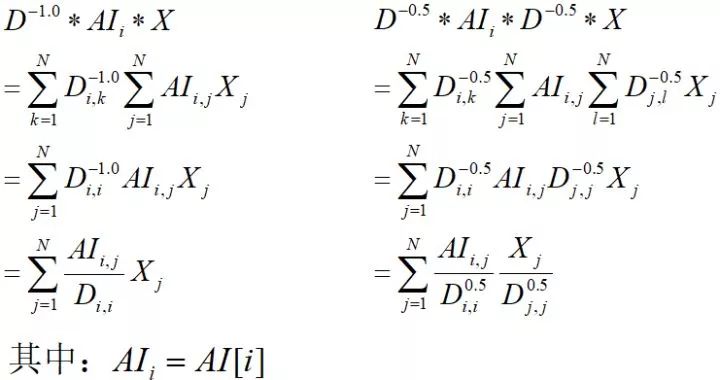
即优化后,运算时不仅仅考虑D矩阵中node[i]对应的点还考虑了node[j]对应的点;
Loss函数不变,仍为下式:
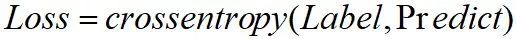
最小化Loss,更新X和W矩阵,其中X即为特征表征;
3. Other
3.1 X矩阵:特征表征
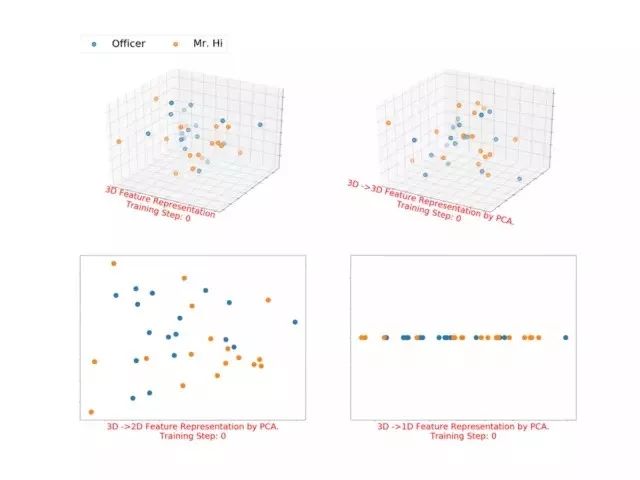
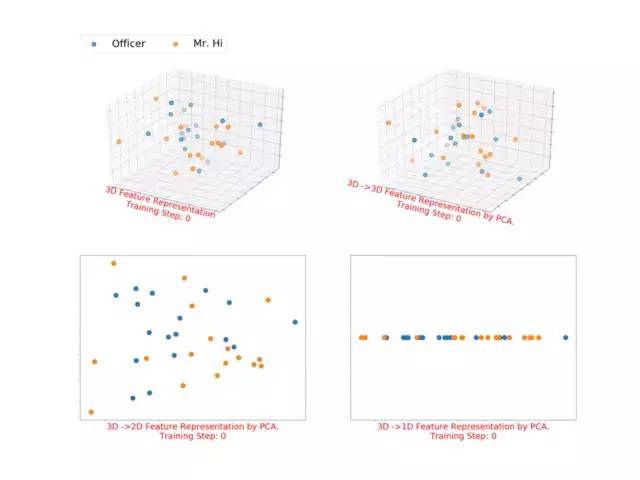
3.1.1 Karate Club的三维表征(即X矩阵为三维矩阵,并将其通过pca进行维度转换及降维进行展示)
3.1.2 football的多维(1~5)表征
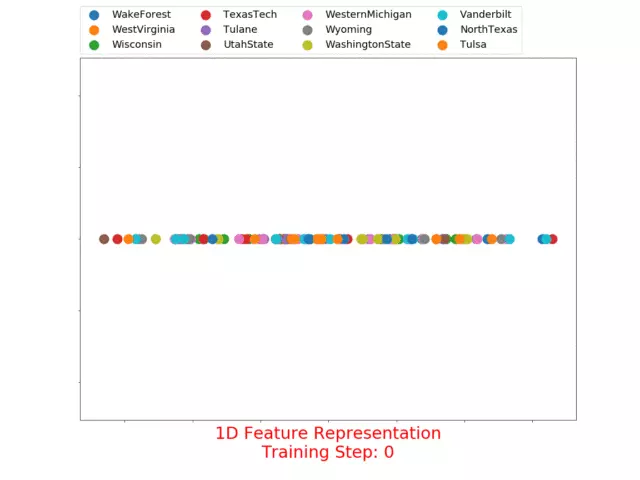
1D feature representation
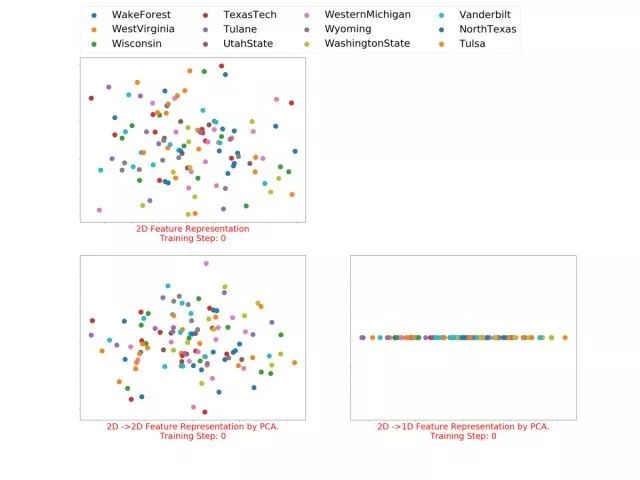
2D feature representation

3D feature representation
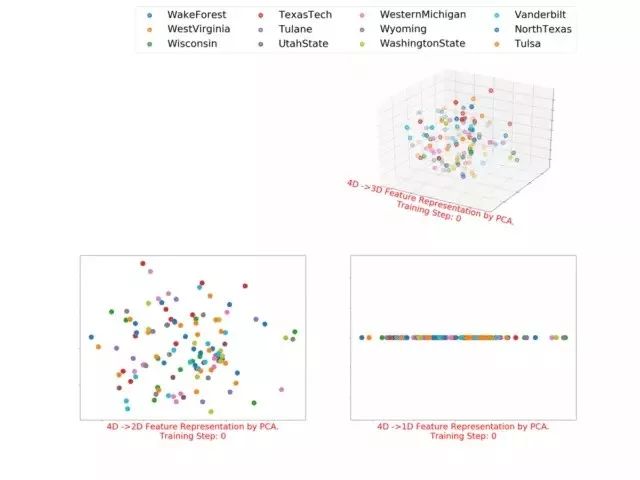
4D feature representation
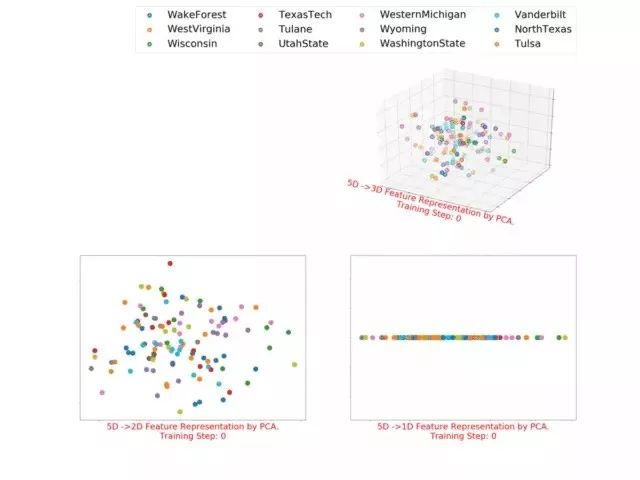
5D feature representation
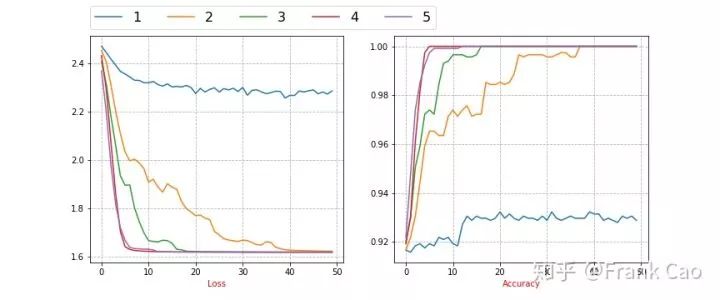
train figure for loss and accuracy
3.2 Semi-Supervised(半监督)
上述讨论中是所有node都是已知的,即其在网络中的关联关系和类别(Label)都是已知的,则矩阵A的shape=[34,34];如果有N个node在网络中的关联关系是已知的,但是类别未知,其亦可参与训练,此时矩阵A的shape=[34, 34+N],其它不变,然后进行训练,训练完成后,这N个node的类别是可以被这个训练完的模型预测的。
3.3 多layer多类别的情况
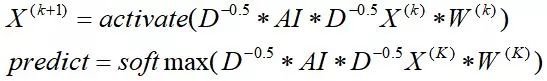
附代码:
https://link.zhihu.com/?target=https%3A//github.com/frank0532/graph_convolutional_networks
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









