






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
算法公平性,从根本上来讲,是一个社会道德问题。

2016年,谷歌照片将两名非裔美国人的照片归类为“大猩猩”。两年后,谷歌除了从分类数据库中将 “大猩猩”一词删除外,没有做任何更多的事情。数据显示,亚马逊曾在2016年,不成比例地向欧美消费者提供了一天的免费送货服务。在佛罗里达州,根据累犯的风险推荐拘留和假释决定的算法在非裔美国人中显示出较高的错误率 ,因此非裔美国人更可能被错误地推荐拘留,而这些人实际上可能不会再继续犯罪。当从一种带有“性别中性”代词的语言,翻译成带有“非性别中性”代词的语言时,谷歌的word2vec神经网络在翻译时注入了一些性别类型,当与“医生”(或“老板”、“金融家”等)一起使用时,代词变成“他”,而当与“护士”(或“家庭主妇”或“保姆”等)一起使用时,代词就变成了“她”。

这些问题是由一系列原因引起的。有些是潜在的社会根源;如果你在一个有偏见的人创建的数据模型上训练机器学习算法,你会得到一个有偏见的算法。有些只是统计性偏差;假如你要训练一种机器学习算法来找到最适合整体人口的方法,但是如果少数群体在某种程度上是不同的,那么他们的分类或推荐就必然会有较差的适合性。有些是两者的结合:有偏见的人会导致有偏见的算法,这些算法提出的建议加强了不合理的分类(例如,对贫困社区更严厉的监管会导致这些社区有更多的犯罪报告。而更多的犯罪报告又会触发警务分析,建议在这些社区部署更多的警察,你看!这样你就得到了一个讨厌的反馈循环)。问题的根源在于根本不知道如何使算法做到公平。针对这方面,有关算法公平性的对话已经成为社会道德的一面放大镜。而关于如何定义和衡量算法公平的争论反映了今天正在进行的更广泛的道德对话。
最近,我有幸采访了斯坦福大学Sharad Goel 。我们谈到了他在算法公平性方面的一些应用工作。我们还特别地针对算法公平性概念化争论的三个方面的好处和缺点,进行了讨论。技术人员可以从Sharad Goel的<a href="https://5harad.com/papers/fair-ml.pdf" h"="">这篇文章 中找到对这一争论的更全面的阐述,但我将在本文中尝试将其总结一下。
算法公平性的三个概念
特定群组标签应该禁止使用。这种认知模式认为,在进行预测时,不应该允许算法考虑某些受保护的类别。从这个角度来看, 比如说,用于预测贷款资格或累犯的算法不应该允许基于种族或性别的预测。这种实现算法公平性的方法是直截了当和容易理解的。但它主要有两个问题:
1.区分受保护类别的可接受和不可接受的替代物。即使从算法中消除了这些类别,由这些受保护类别解释的统计方差也倾向于滑入其他可用变量中。例如,虽然种族可能被排除在贷款申请之外,但邮政编码往往与种族高度相关,它可以在模型中承担更高的预测权重并掩盖了歧视。无论出于何种目的,邮政编码都将成为新的种族变量。什么是保护类别的非法替代品?什么是是可接受的、不同的变量?这是很有挑战性和值得商榷的问题。这条模糊的线给我们带来了另一个让某些标签成为“禁区”的问题;
2. 社会(有时是个人)的成本很高。受保护的类别通常会对算法设计用来预测的行为产生重大的影响。例如,众所周知,男性司机的保险费较高,因为男性司机确实占到了保险支出总额的大部分。从这些算法中消除性别会导致男性司机的汽车保险费下降,但会增加女性司机的保险费率。是否应该要求妇女支付超过其风险份额的费用,并将性别因素从风险算法中排除出去?这是一个值得商榷的问题。简言之,虽然这可能创造完全的平等,但这似乎没有达到按比例公平的标准。所以有人可能会说,这种做法实际上是不公平的。
在刑事司法环境中,这种风险可能更大。从预测累犯的算法中删除性别或种族等受保护的类别会降低算法的效率,这意味着更多的实际风险较低的人会被拘留,更多的实际风险较高的人会被释放。其后果将是:(在总体上)更多的犯罪会发生,特别是在已经经历更高犯罪率的社区中。要认清这一点,请记住,大多数暴力犯罪发生在相互认识的人之间。因此,在算法效率降低时(尽管可以解释,但是受保护的类别仍然是不允许使用的),已经饱受暴力犯罪困扰的社区可能会经历额外的重新(暴力)犯罪。
大多数人(包括法律)都认为,在没有具体理由的情况下,根据受保护的类别做出决定,在道德上是应该受到谴责的。困难的是,当使用这些保护类别时,似乎可以有效地减少有害后果。这种取舍导致一些人采取了另一种方法来从算法上定义公平性。有没有办法可以最大限度地提高预测准确度(允许包含有理由的保护类别),同时仍然保持算法的公平性呢?
算法表现对特定群组应该同样有效。与忽略诸如种族和性别之类的受保护类别(例如色盲法-不区分肤色,或性别盲法-不区分性别)相反,这种公平性的方法认为,针对受保护的类别,算法表现的指标应该是相等的。例如,一个将罪犯分为高重犯风险和低重犯风险的算法应该使白人和黑人罪犯的预测误差相等。这种方法比色盲方法更不直观,但至少理论上使得算法在其预测时更有效,并且避免了一些棘手的判断要求的一些替代物带来的歧视,而那些替代物(例如邮政编码作为种族的粗糙替代物)是不允许用在算法中的。

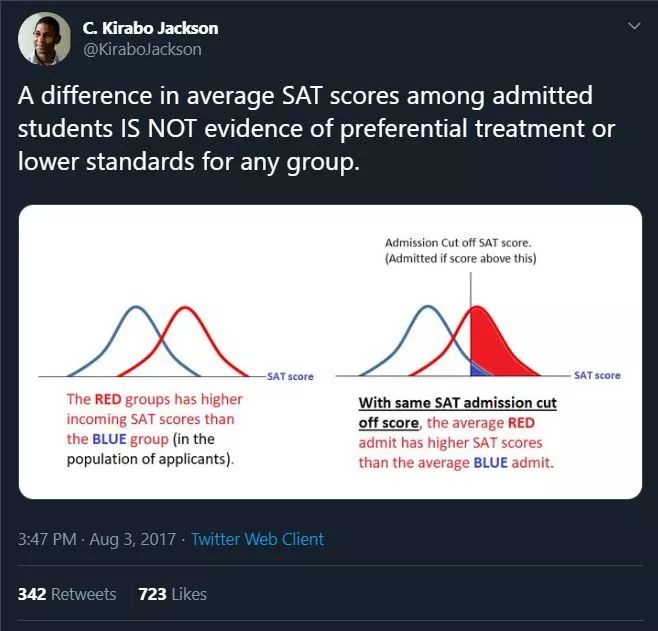
不过,这种方法并不完美。要了解原因,很重要的一点是要了解不同的群组将代表不同的人群,他们的平均得分、偏差、偏度、峰度等都不同(见上图,想象一下使用相同的截止阈值(cutoff threshold)尝试让一个算法对每个群组曲线有同样的表现)。一般来说,当我们谈到公平性时,我们希望所有的人,不管他们属于哪个群组,都能遵守同样的标准。但是,如果对不同的人群使用相同的截止阈值,算法的预测能力和错误率很可能在不同的人群中有所不同 - 这只是统计工作方式的自然结果。如果政府监管迫使企业开发出来的算法,针对受保护的群组也能保持相同的表现,那么企业和机构就会被激励去采取故意歧视的做法,利用那些统计技巧和员工保密条款的灰暗地带大做文章。
通常这些公司和机构有两个选择:1.通过玩弄代码降低算法的质量和效率,从而使算法针对不同群组都会有相同的表现(这个选择会产生前面讨论的潜在危害,例如导致高风险评分的累犯被释放),或者2.公司可以对不同的人群采用不同的算法阈值,这样不同的人群(不同性别、种族、性取向的人群,等等)的截止阈值是不同的。但很明显,这似乎违背了公平的观念,通常在道德层面是不受欢迎的,并且也被认为是非法的(但有一个明显的例外是针对类似平权行动的算法)。对算法表现的强制均衡造成的对所有群体的负面影响不仅仅是理论上的,它们已经被记录在案。例如,在累犯风险评分数据库,以及预测警察在白人和黑人公民中发现违禁品可能性的数据库中。
算法评分对不同群组的成员应该代表相同的东西。实现算法公平性的第三种方法是确保算法评分对所有受保护的类别都意味着相等的东西(例如,在其保险申请中获得风险评分X的女性,应该与在其保险申请中也获得风险评分X的男性有相接近的保险支出)。从表面上看,这种做法似乎达到了我们想要的目的,似乎是公平的。问题是,在存在故意歧视行为的情况下,它无法保证公平,因此,根据公平的这一定义对算法进行监管仍将为模糊的歧视性待遇留下空间。至少存在两种可能发生的方式:
1. 替代物(如不同种族的邮政编码)仍然可以用于不公平地设定人群评分使其高于或低于算法的截止阈值。例如,贷款违约风险较高的个人可以与贷款违约风险较低的个人配对,这样受保护类别的风险评分可以随意推高或低于临界阈值。这本质上可以归结为触碰了算法红线。

2. 如上所述,不同的群组将有不同的统计风险曲线。如果量化评分在群组内离散化(例如,用“高”、“中”或“低”标签代替个人的准确评分),真实风险曲线上的这些差异可以掩盖不同的群体界限,同时保持一个虚假的外表,被贴上“高”风险标签的个人再次犯罪、违约,不同的受保护类别((种族、性别等)以相似的比率发生车祸。例如,在上图中,基于群组内部的百分比给一个人分配一个“高”、“中”或“低”风险标签将有效地产生不同的群组截止阈值,同时潜在地保持每个受保护群组在那些标记为“高”风险时的算法表现相同。
虽然对B2C公司来说,使用这些技术似乎有点罕见,但是B2C公司往往会因为在这些方面的歧视而蒙受利润损失,所以对B2B公司而言,仍然存在使用这些技术的动机。例如,广告匹配公司就有动机,将特定的群体推到高于或低于临界值的水平,以便证明基于受保护类别定位广告目标的合理性。不难想象,政治家们或游说者会被这些方法的力量所吸引,从而利用它们来左右舆论,同时留下很少的把柄,或者错综复杂的迷雾。(我只是说,如果美国参议员无法理解Facebook的商业模式,我对他们理解这一问题的信心是……嗯,不乐观。)
算法公平性面临的挑战
每种定义算法公平性的方法都有其优缺点。我认为最令人不安的不是每种方法所面临的弱点,而是这些方法从根本上说是互不兼容的。当使用受保护类别作为检测算法公平性的基线时,我们不能忽略受保护类别。我们不能要求相似的算法错误率,同时要求相似的风险评分在群组间必然会产生相似的结果。定义算法公平性的竞赛还在进行中。但我的道德心理学背景也让我停下来思虑再三。民主党人、共和党人和自由主义者对什么是算法公平性无法达成一致,而我也认为把算法公平性当作一个数学和计算机科学问题来对待有点过于乐观了。问题不在于解决一些复杂的统计学魔方难题,而在于它试图在一个只能捕捉阴影的洞穴墙上体现柏拉图式完美的公平形式。很难预测我们会采用哪种解决方案,以及当这些解决方案与监管和经济激励措施相互作用时,会产生什么样的成本。算法公平性,从根本上来讲,是一个社会道德问题。
如果你喜欢这篇文章,就点个赞吧!
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

















 2826
2826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









