






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达一、基本介绍
首先简单介绍下,多标签分类与多分类、多任务学习的关系:
多分类学习(Multi-class):分类器去划分的类别是多个的,但对于每一个样本只能有一个类别,类别间是互斥的。例如:分类器判断这只动物是猫、狗、猪,每个样本只能有一种类别,就是一个三分类任务。常用的做法是OVR、softmax多分类
多标签学习(Multi-label ):对于每一个样本可能有多个类别(标签)的任务,不像多分类任务的类别是互斥。例如判断每一部电影的标签可以是多个的,比如有些电影标签是【科幻、动作】,有些电影是【动作、爱情、谍战】。需要注意的是,每一样本可能是1个类别,也可能是多个。而且,类别间通常是有所联系的,一部电影有科幻元素 同时也大概率有动作篇元素的。

多任务学习(Multi-task):基于共享表示(shared representation),多任务学习是通过合并几个任务中的样例(可以视为对参数施加的软约束)来提高泛化的一种方式。额外的训练样本以同样的方式将模型的参数推向泛化更好的方向,当模型的一部分在任务之间共享时,模型的这一部分更多地被约束为良好的值(假设共享是合理的),往往能更好地泛化。某种角度上,多标签分类可以看作是一种多任务学习的简单形式。
二、多标签分类实现
实现多标签分类算法有DNN、KNN、ML-DT、Rank-SVM、CML,像决策树DT、最近邻KNN这一类模型,从原理上面天然可调整适应多标签任务的(多标签适应法),如按同一划分/近邻的客群中各标签的占比什么的做下排序就可以做到了多标签分类。这部电影10个近邻里面有5部是动作片,3部是科幻片,可以简单给这部电影至少打个【科幻、动作】。
这里着重介绍下,比较通用的多标签实现思路,大致有以下4种:
方法一:多分类思路
简单粗暴,直接把不同标签组合当作一个类别,作为一个多分类任务来学习。如上述 【科幻、动作】、【动作、爱情、谍战】、【科幻、爱情】就可以看作一个三分类任务。这种方法前提是标签组合是比较有限的,不然标签会非常稀疏没啥用。
方法二:OVR二分类思路
也挺简单的。将多标签问题转成多个二分类模型预测的任务。如电影总的子标签有K个,划分出K份数据,分别训练K个二分类模型,【是否科幻类、是否动作类....第K类】,对于每个样本预测K次打出最终的标签组合。
这种方法简单灵活,但是缺点是也很明显,各子标签间的学习都是独立的(可能是否科幻类对判定是否动作类的是有影响),忽略了子标签间的联系,丢失了很多信息。
对应的方法有sklearn的OneVsRestClassifier方法,
from xgboost import XGBClassifier
from sklearn.multiclass import OneVsRestClassifier
import numpy as np
clf_multilabel = OneVsRestClassifier(XGBClassifier())
train_data = np.random.rand(500, 100) # 500 entities, each contains 100 features
train_label = np.random.randint(2, size=(500,20)) # 20 targets
val_data = np.random.rand(100, 100)
clf_multilabel.fit(train_data,train_label)
val_pred = clf_multilabel.predict(val_data)方法三:二分类改良
在方法二的基础上进行改良,即考虑标签之间的关系。每一个分类器的预测结果将作为一个数据特征传给下一个分类器,参与进行下一个类别的预测。该方法的缺点是分类器之间的顺序会对模型性能产生巨大影响。
方法四:多个输出的神经网络
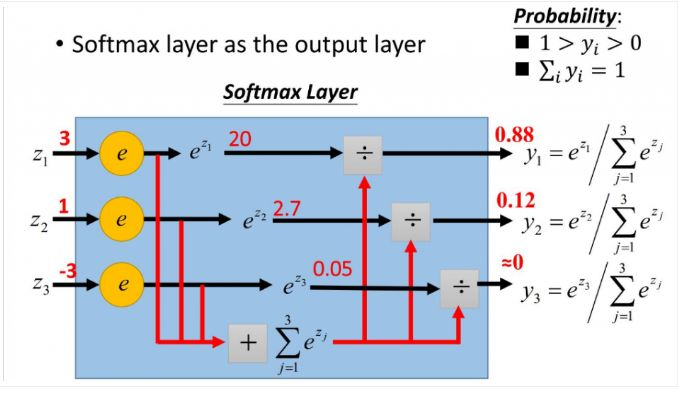
这以与多分类方法类似,但不同的是这里神经网络的多个输出,输出层由多个的sigmoid+交叉熵组成,并不是像softmax各输出是互斥的。
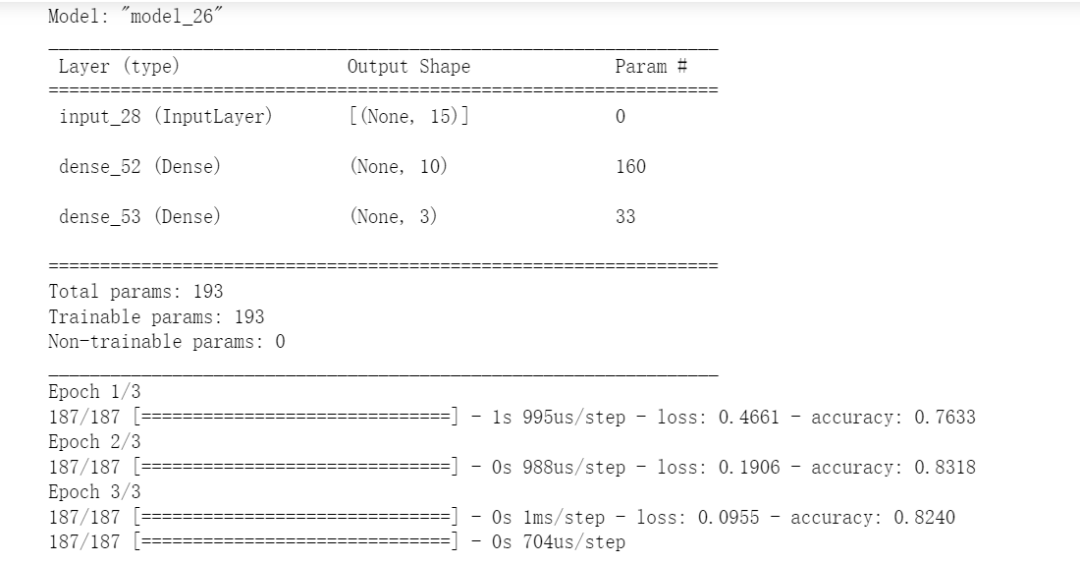
如下构建一个输出为3个标签的概率的多标签模型,模型是共用一套神经网络参数,各输出的是独立(bernoulli分布)的3个标签概率
## 多标签 分类
from keras.models import Model
from keras.layers import Input,Dense
inputs = Input(shape=(15,))
hidden = Dense(units=10,activation='relu')(inputs)
output = Dense(units=3,activation='sigmoid')(hidden)
model=Model(inputs=inputs, outputs=output)
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.summary()
# 训练模型,x特征,y为多个标签
model.fit(x, y.loc[:,['LABEL','LABEL1','LABEL3']], epochs=3)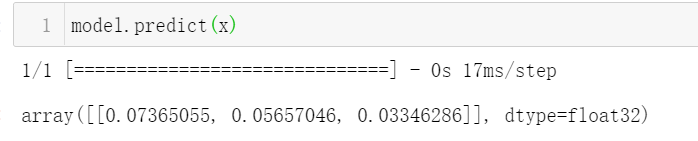
通过共享的模型参数来完成多标签分类任务,在考虑了标签间的联系的同时,共享网络参数可以起着模型正则化的作用,可能对提高模型的泛化能力有所帮助的(在个人验证中,测试集的auc涨了1%左右)。这一点和多任务学习是比较有联系的,等后面有空再好好研究下多任务。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~













 542
542











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









