






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达目标:本博客旨在了解YOLO体系结构,并在自定义数据集上对其进行训练,然后微调模型以获得更好的结果,并进行推理以了解最佳工作方式。
YOLO代表什么?
YOLO(You Only Look Once)是一种先进的目标检测算法,由于其革命性的单次检测技术而声名鹊起,该技术提高了其速度和准确性,超越了同类产品。
YOLOv1最初是在2015年提出的,将目标检测视为回归问题,使用边界框计算类别概率。它经过多次改进,目前由Ultralytics维护,后者发布了最新版本Yolov8。
简要了解YOLO算法的工作原理
顾名思义,YOLO算法在图像上进行单次预测,这比传统方法更好,传统方法使用滑动窗口在整个图像上进行卷积,或者使用多个位置的区域提案来定位对象。
YOLO通过将图像划分为S x S网格(如下所示)来实现这一点,其中每个网格单元负责生成边界框和置信度得分输出。

对于图像中的每个网格单元,我们计算以下内容:
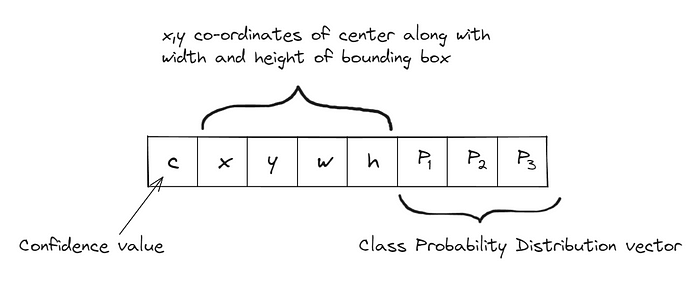
目标变量的格式,每个网格单元的第一个单元是置信度值,这只是一个标签,决定网格单元内是否存在任何对象(0或1)。如果答案是肯定的,那么我们继续预测xywh格式的边界框的值,其中x和y是边界框中心的坐标,w和h是边界框的宽度和高度。最后,我们有我们的类概率分布向量,其中包含每个对象标签的预测分数,范围在0到1之间。
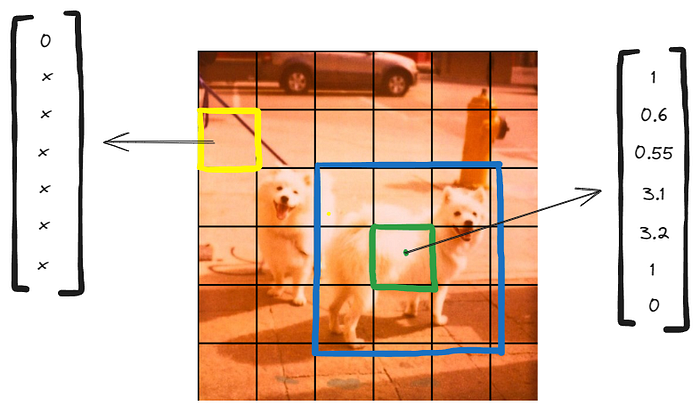
使用上述图像的网格单元的示例输出
如果我们看一下上面的图像,我们可以清楚地看到蓝色的边界框定义了狗对象的真实边界。当我们查看绿色网格单元的输出向量时,我们试图预测蓝色边界框的中心,这是我们的真实标签。
首先,我们确定该网格单元中是否存在对象,由于答案是肯定的,我们可以继续分配xywh值,您可能已经注意到宽度和高度值超出了0和1的范围。这是因为整个边界框的真实标签跨越了绿色网格单元并且在高度和宽度上需要多于3个网格单元。最后,关于我们的类概率分数,绿色网格单元只包含doog对象,因此我们可以轻松地为狗对象分配分数1,而对于车对象则为0。
另外,如果我们看一下黄色网格单元,我们知道它不包含任何对象,因此我们可以简单地为其输出向量分配置信度值0。这里的“x”表示不关心的项,这意味着我们可以安全地忽略输出向量中的所有其他值。

训练Yolov8模型使用自定义数据集
现在,让我们继续使用来自Roboflow的Player and Ball Detection数据集,并使用Yolov8进行训练:
数据集链接:https://universe.roboflow.com/nikhil-chapre-xgndf/detect-players-dgxz0
首先,我们需要安装Ultralytics,它维护了所有Yolo模型:
pip install ultralytics接下来,我们需要设置一个YAML文件以配置一些训练参数:
path: absolute path to dataset (/path/to/dataset)
train: relative path from dataset (/train)
test: relative path from dataset (/test)
val: relative path from dataset (/val)
# Define Classes and their Labels
names:
0: Ball
1: Player
2: Referee接下来,我们需要选择一个Yolov8模型权重来开始我们的训练:
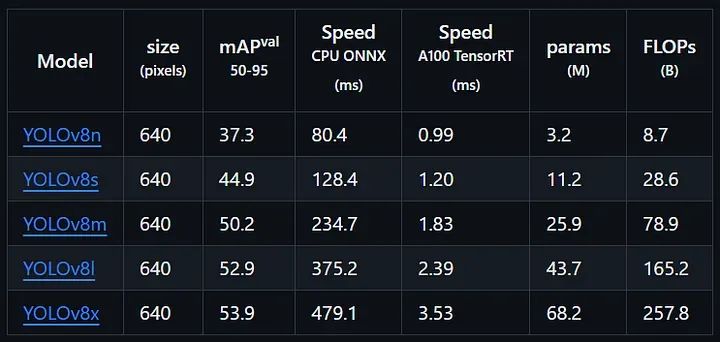
在我们的用例中,我们将使用Yolov8n(Nano),它是最轻量级和最快速的模型,虽然根据mAP分数来说它并不是最准确的模型,但经过足够的训练,它可以在视频跟踪时产生更好的fps并得到良好的结果。
from ultralytics import YOLO
import torch
import os
# Load the YOLOv8 model
model = YOLO('yolov8n.pt')
# TRAINING
if __name__ == '__main__':
results = model.train(data="config.yaml", epochs=50, patience=5)如上所示,我们可以简单地从之前设置的config.yaml文件中加载数据。我们将开始进行100个时期的训练,并设置一个持续10个时期的耐心参数,这意味着如果在连续的10个时期内没有改进,则模型将提前停止训练。
为获得更好的结果而提高网络维度
在训练过程中我面临的最大挑战是“球”类别的低mAP分数,花了一些时间我才意识到出了什么问题。Yolov8通常期望输入图像为正方形格式,在非正方形图像的情况下,默认将所有图像调整为宽度为640px的图像,保持纵横比以维持高度。除非另有规定,如下所示。

原始图像,尺寸为1920x1080

Yolov8调整大小的图像,尺寸为384x640以保持纵横比
使用GIMP比较“球”类的大小
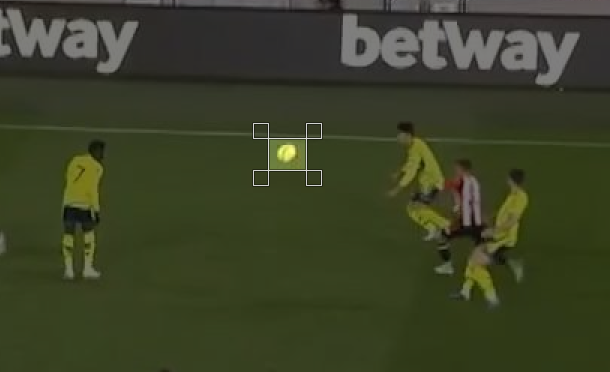

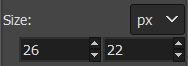
原始图像中“球”类的像素大小
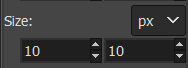
压缩图像中“球”类的像素大小
在两张图像中,对象图像的质量和大小的减小都很明显,因此导致模型的检测效果差。在训练时增加图像大小可以获得更好的mAP分数,不仅对于“球”类别,对于所有其他类别也是如此。
但是,这意味着我们应该始终使用最高分辨率的图像进行训练和推理以获得最佳结果,对吗?这个答案取决于情况,因为增加模型的网络维度将导致模型使用更多的训练资源并使其变慢。因此,我们需要找到一个平衡速度和模型准确性的最佳点。

此外,请记住,根据YOLO文档,网络维度只能是32的倍数。因此,经过一些思考,我决定使用1088作为图像大小,考虑到最小对象的最小图像大小应大于15x15像素。
模型性能
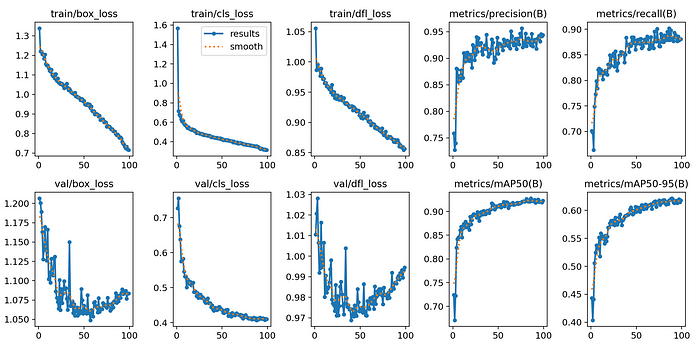
一旦我们完成训练,我们可以使用上面显示的指标查看训练/验证结果,Yolov8为每个详细指标准备了一个充满图表和可视化的目录,以及模型权重,上面只是一个简要摘要。
现在,我们可以使用这个训练结果目录,将权重上传回Roboflow以部署为模型,这可以用于辅助图像标注,或者可以简单地在线部署供公众使用。

在Roboflow上查看指标
使用我们的模型权重进行推理
现在,我们可以加载我们刚刚训练的最佳权重,然后使用Ultralytics提供的BoTSORT跟踪器对视频剪辑进行跟踪,而不是使用默认权重。
import cv2
from ultralytics import YOLO
# Load the YOLOv8 model
# model = YOLO('yolov8n.pt') ### Pre-trained weights
model = YOLO('runs/detect/train2/weights/best.pt') ### weights from trained model
# Open the video file
video_path = r"path/to/video"
cap = cv2.VideoCapture(video_path)
# Loop through the video frames
while cap.isOpened():
# Read a frame from the video
success, frame = cap.read()
if success:
# Run YOLOv8 tracking on the frame, persisting tracks between frames
results = model.track(frame, persist=True, show=True, tracker="botsort.yaml")
# Visualize the results on the frame
annotated_frame = results[0].plot()
# Display the annotated frame
cv2.imshow("YOLOv8 Tracking", annotated_frame)
# Break the loop if 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
# Break the loop if the end of the video is reached
break
# Release the video capture object and close the display window
cap.release()
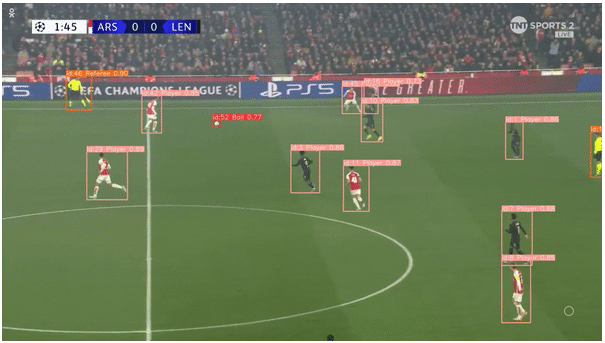
cv2.destroyAllWindows()向我们的检测模型添加跟踪有助于在视频剪辑的连续帧之间跟踪物体,它通过为每个检测到的对象分配一个唯一的ID来实现这一目标。因此,它还可以帮助绘制对象(如足球)随时间变化的轨迹,并基于其在帧之间的运动绘制路径。
最终结果
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~















 3058
3058











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











