






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达Transformer 网络结构作为一种性能卓越的神经网络学习器,已经在各类机器学习问题中取得了巨大的成功。伴随着近年来多模态应用和多模态大数据的蓬勃发展,基于Transformer 网络的多模态学习已经成为了人工智能领域的前沿热点之一。
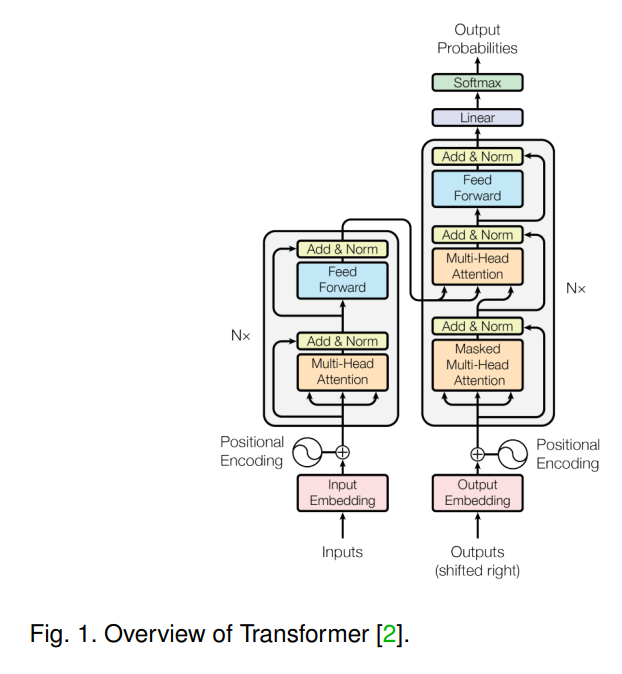
今天为大家介绍一篇基于Transformer的多模态学习的综述论文“Multimodal Learning with Transformers: A Survey”,该论文已经被IEEE TPAMI录用。

论文链接:
https://arxiv.org/abs/2206.06488
https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=10123038
这篇综述论文总结了三百余篇具有代表性的论文,梳理了面向多模态任务的Transformer 相关技术的发展。全文的主要内容包括:
(1)对多模态学习、Transformer 生态体系、多模态大数据时代的背景介绍;
(2)以几何拓扑的思想角度对Transformer、视觉Transformer、多模态Transformer 进行了系统性回顾和总结;
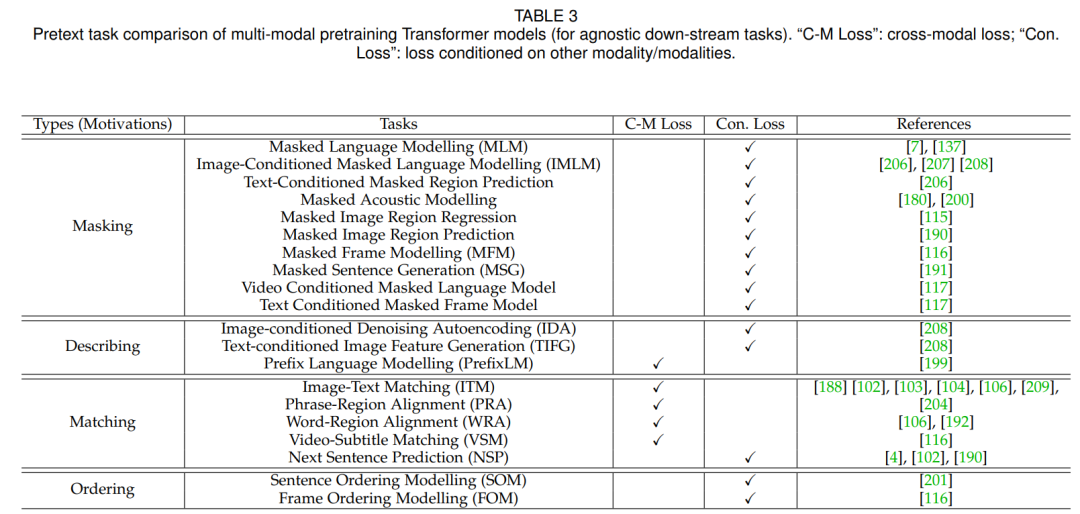
(3)从多模态预训练和面向特定多模态任务的两个维度对多模态Transformer 的应用和研究进行了总结;
(4)对多模态Transformer 模型及应用中的一些共通的技术挑战和设计思想进行了对比与总结;
(5)并且讨论了该研究社区内的一些开放问题和潜在的研究方向。
全文的主要观点和特色包括:
(1)该综述的主要观点之一是,强调了Transformer 的理论优势之一是它能够以模态不可知(modality-agnostic)的方式进行工作,因而可以与各种模态及其组合进行兼容。为了支撑这个观点,该文阐述了如何从几何拓扑的角度来理解Transformer 在多模态上下文中的信号处理过程。建议将自注意力机制视为一种图式建模,通常在无先验知识的情况下,它将输入序列(单模态和多模态)建模为全连通图,自注意力机制将来自任意模态的任意标记令牌的嵌入向量建模为图上的一个节点。
(2)全文以尽可能公式化的方式在多模态上下文中讨论Transformer 的关键组件。
(3)强调了,在基于Transformer 的多模态模型中,跨模态的相互交互(例如,融合,对齐)实质上是由自注意力机制及其变体所感知并处理的。所以,从自注意力设计与演变的角度,归纳总结了基于Transformer的多模态学习实践中的公式化表达,将常见的基于Transformer的多模态交互过程归纳为了6种自注意力操作。
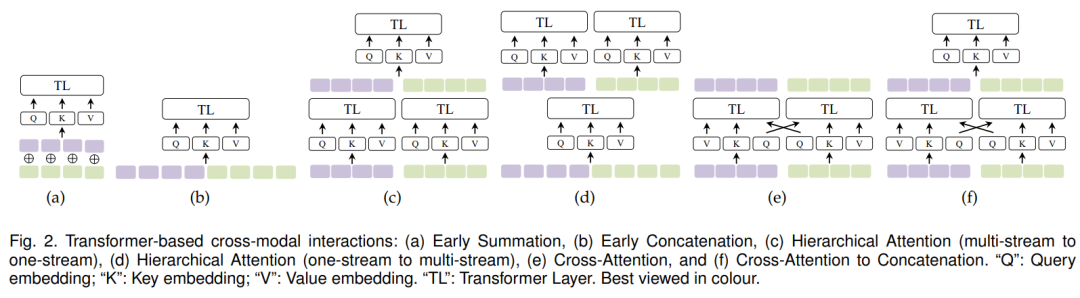
(4)除综述总结的内容外,该文中还穿插了很多专门的评述和讨论的段落,例如从数学的观点角度讨论了Transformer结构中的post-normalization 和 pre-normalization,再例如对Transformer结构中position embedding的理解与讨论。
更多综述论文,请关注:
https://github.com/52CV/CV-Surveys
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~














 1038
1038











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









