






卷积的尽头不是Transformer,极简架构潜力无限
—— VanillaNet: the Power of Minimalism
6层的VanillaNet可以超过ResNet-34,13层的VanillaNet在ImageNet达到83%的top1精度,超过几百层网络的性能,并展现了非凡的硬件效率优势。顺道一提,VanillaNet的中文名字为朴素网络。
论文见:https://arxiv.org/abs/2305.12972。
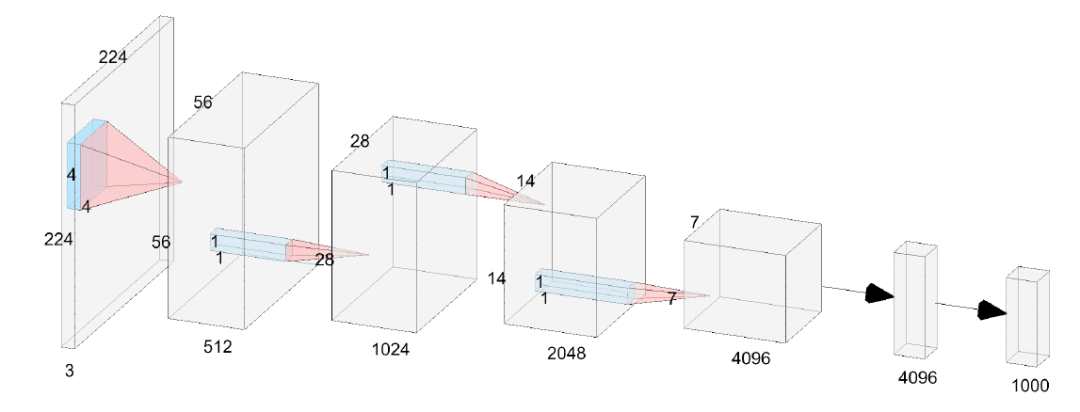
* 6层的VanillaNet结构图,没有Shortcut
致敬LeNet、AlexNet和VGGNet
在过去几年时间,一直都在找关于神经网络架构创新的灵感。在视觉Backbone这个方向上,端侧我们有了GhostNet这种轻量的模型架构和系列算法。
但是面对现在大算力,还没有什么特别好的思路,虽然在Vision Transformer的路上跟着大家也一起做了一点工作,但一直想利用最简单的卷积网络,尝试做出更强的效率和性能,在实际应用中也可以有更大的价值。
从2015年底到现在,基于shortcut的ResNet系列,仍然是神经网络架构设计的主流思路,在一定程度上解决了梯度消失问题之后,大家发现越深越复杂的网络效果越好,所以有了很多很多优秀的工作,直到2020年的ViT。
虽然Transformer高阶的计算方式和参数量带来了更好的性能,但它的复杂度和硬件亲和程度也一直让做产品的朋友们叫苦不迭。
为此,我跟汉亭、建元还有陶老师一起,设计了一种极简的神经网络模型VanillaNet,期望用最简单的,类似LeNet和AlexNet这样的结构,达到甚至超越现在Vision Transformer的精度,成为新一代的视觉骨干网络。
这个工作的核心就是,如何让一个浅层网络在没有复杂链接和attention的情况下,尽可能地提升精度,实际上我们面临的非线性大幅下降的技术难题。
现代深度神经网络强大的拟合能力,甚至在不考虑复杂度的情况下具有逼近任意函数的潜力,很大一部分是复杂的非线性层不断堆叠带来的。

优化策略1
深度训练,浅层推理
为了提升VanillaNet这个架构的非线性,我们提出首先提出了深度训练(Deep training)策略,在训练过程中把一个卷积层拆成两个卷积层,并在中间插入如下的非线性操作:
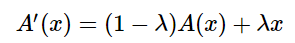
其中,A是传统的非线性激活函数,最简单的还是ReLU,λ会随着模型的优化逐渐变为1,两个卷积层就可以合并成为一层,不改变VanillaNet的结构。

优化策略2
换激活函数
既然我们想提升VanillaNet的非线性,一个更直接的方案是有没有非线性更强的激活函数,并且这个激活函数好并行速度快?
为了实现这个既要又要的宪法,我们提出一种基于级数启发的激活函数,把多个ReLU加权加偏置堆叠起来:
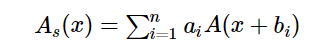
然后再进行微调,提升这个激活函数对信息的感知能力。

极简网络的魔力
直接点,来我们直接看ImageNet上的结果。
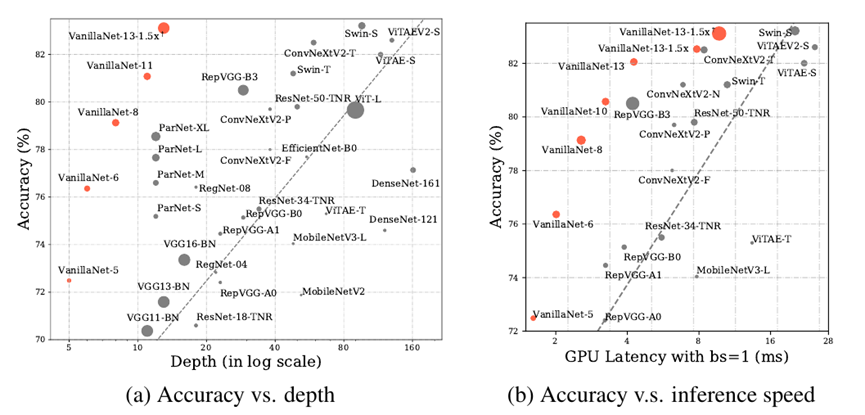
* VanillaNet与SOTA架构在深度、精度、速度上的对比
这一版的VanillaNet中,我们都采用224*224的分辨率,跟现在在很多工业界场景都在用的ResNet系列和ViT系列都进行了详细对比。
在现代的GPU加持下,VanillaNet的精度和速度,不负众望,达到了我们想看到的结果。虽然参数多,虽然计算量多,但是,势大力沉,精度又高速度又快!
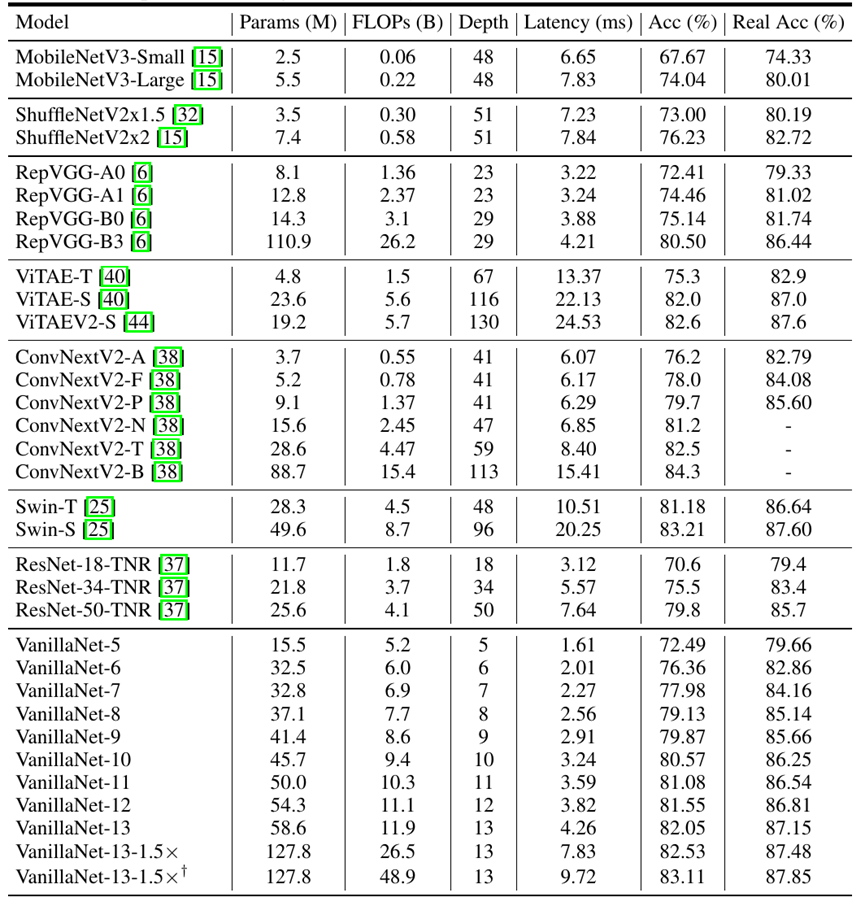
VanillaNet这样一个非常朴素的架构,6层可以超过ResNet-34,13层的VanillaNet在ImageNet达到83%的top1精度,超过几百层网络的性能,并展现了非凡的硬件效率优势,在于Swin-S相当的精度时(83%+),速度快了1倍以上!
另,在检测和分割上,Backbone的优势同样可以继承到下游任务中,CV里无论是讨论大模型,还是讨论啥,核心都还是骨干网络。

消融实验的核心汇总一下
●深度训练策略和级数激活函数对VanillaNet的性能提升非常明显,15%以上的绝对精度提升,同样对AlexNet有效,这可能是浅层网路文艺复兴的契机。但是,重点是,对ResNet没有任何明显的效果,非常非常有趣,直观上来说可能这些东西ResNet并不需要吧;
●现有主流模型中的shortcut和一些变种,对VanillaNet没有效果,甚至精度还会有一定的恶化。模型结构没那么深的情况下,其实在ResNet原文中也有提到,18层加不加shortcut性能差距不大;

VanillaNet名字的后记
关于这个网络的名字,我们其实讨论了很多次,最开始的名字叫做DeLeNet(细心的小伙伴可能会在github上看到),什么意思呢,是depthless network。
但是这也是个极端,是不是我们不能超过一个层数的限制?所以在跟陶老师讨论的过程中,他建议我们就叫VanillaNet,也建议我们把AlexNet重新优化一下,挖掘这些简单、朴素、极简的架构的潜力,发挥它们在大模型时代的作用。
VanillaNet是我们的一个开端,让我们重新思考了很多,到底什么对深度神经网络性能提升是最重要的,是深度,是感受野,是attention,还是参数量?
目前这个版本的VanillaNet我们优化了接近一年,已经在很多实际业务中都用了起来。但它也还有很多提升空间,比如没有加任何的预训练和蒸馏,也没有进一步系统性尝试与其它网络架构的融合,还没有更进一步进行结构的优化。
AI的浪潮一波三折,距离AlexNet提出已经有11年过去了,而今迈步从头越,期待未来的新架构和新应用。

点击阅读原文,了解更多详情















 40万+
40万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









