






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转自:多模态机器学习与大模型
论文链接:
https://arxiv.org/abs/2311.17597
代码链接:
https://github.com/yeerwen/MedCoSS
简介
自监督学习是一种有效的医学图像分析预训练方法。然而,目前的研究大多局限于特定模态的数据预训练,消耗了大量的时间和资源,而没有实现不同模态的通用性。一个简单的解决方案是将所有模态数据组合起来进行联合自监督预训练,但具有一定的实际挑战。首先,作者在文中揭示了随着模态数量的增加,表示学习中存在冲突。其次,提前收集的多模态数据无法覆盖所有现实场景。作者从持续学习的角度重新考虑通用的自监督学习,提出一种针对多模态医疗数据的持续自监督学习方法,记为MedCoSS。与联合自监督学习不同,MedCoSS 将不同的模态数据分配到不同的训练阶段,形成多阶段的预训练过程。为了平衡模态冲突并防止灾难性遗忘,提出了一种基于预演(rehearsal)的持续学习方法,引入 k 均值采样策略来保留以前模态的数据,并在学习新模态时进行预演。不是对缓冲区数据执行借口任务,而是对这些数据应用特征蒸馏策略和模内混合策略以保留知识。文中对大规模多模态未标记数据集进行连续的自我监督预训练,包括临床报告、X 射线、CT 扫描、MRI 扫描和病理图像。实验结果证明了 MedCoSS 在九个下游数据集上具有卓越的泛化能力,并且在集成新模态数据方面具有显着的可扩展性。
论文贡献
(1)识别并缓解模态数据冲突问题并创新 MedCoSS 范式。通过从联合训练转向顺序训练并引入持续学习,从而减少了冲突,并经济有效地扩展了新知识,同时又不忘记旧知识。
(2) 对不成对的多模态 SSL(自我监督学习) 进行了深入探索,扩展了模态和数据维度。整合了五种流行的模式,包括报告、X 射线、CT、MRI 和病理成像,跨越三个维度(1D、2D 和 3D),使用提出的 MedCoSS 预训练通用模型。
(3)MedCoSS模型在广泛的下游任务上实现了最先进的泛化性能,表明了开发多模态预训练医疗通用模型的潜在方向。
MedCoSS模型
MedCoSS 范例被设计为两步 SSL,其中包括无监督的预训练阶段和完全监督的微调阶段。在预训练期间,采用掩蔽图像/语言建模作为借口任务,从一组集成的多模态数据中提取广义表示,特别是临床报告、X 射线、CT 扫描、MRI 扫描和病理图像。为了规避联合多模态预训练造成的模态数据碰撞的障碍,作者在文中引入了顺序预训练方案,其中每个阶段都针对特定模态的数据进行训练。在这个连续的过程中知识遗忘的潜在风险可以通过持续学习技术来应对。在微调过程中,预先训练的编码器与每个下游任务的随机初始化的特定任务头配对。MedCoSS 范式的全面可视化如图 2 所示。
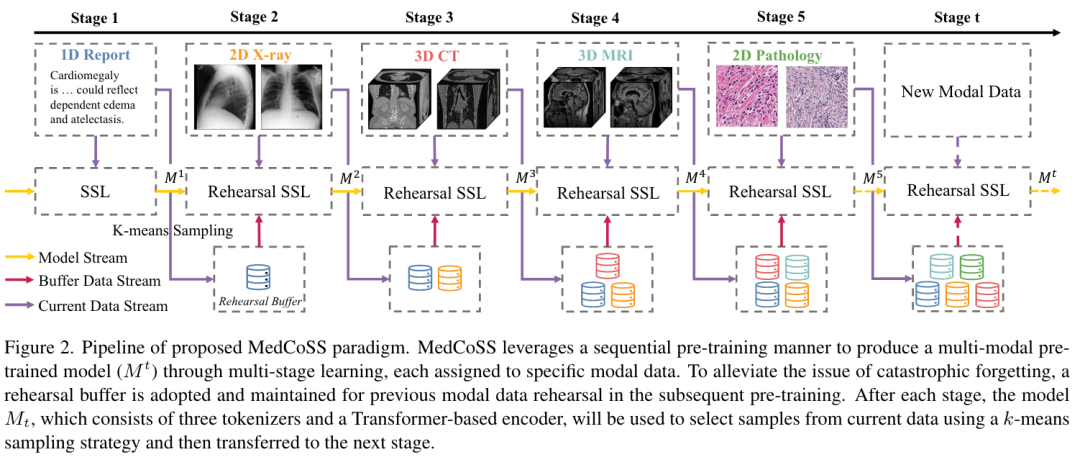
多模式 SSL 的通用架构
根据通用多模式 SSL 的目标设计了一个通用架构。来自各种方式的医疗数据可以是 1D(例如临床报告)、2D(例如 X 射线和病理图像)或 3D(例如 CT 和 MRI 扫描)。作者采用三个特定于维度的分词器分别将1D,2D 和 3D 医疗数据转换为 token 序列,并使用普通的 ViT/B 作为编码器,以序列到序列的方式进行表示学习,而不管医学数据的维度如何。具体来说,为文本部署字节对编码 (BPE) 标记器,为 2D/3D 视觉数据部署 2D/3D 图像补丁标记器。对于文本,按照 BERT,随机屏蔽 15% 的单词。该模型根据可见词预测每个屏蔽词,使用交叉熵损失作为约束。对于视觉数据,遵循 MAE,token 序列以 75% 的比例随机屏蔽,并且只有那些未屏蔽的 token 序列被馈送到编码器。随后,编码的可见标记序列与可学习的掩码标记一起作为基于 Transformer 的解码器的输入,旨在重建先前掩码的标记。采用均方误差(MSE)损失来确保掩模区域中原始图像和重建图像之间的高度一致性。
基于预演的持续预训练
多模态数据联合预训练的典型方法经常遇到模态数据冲突和整合新知识成本高的问题。为了解决这两个问题,作者主张转向顺序预训练范式,有效地将每个阶段分配给特定的成像模式。形式上,考虑 T 个未标记的数据子集 ,每个子集都是从唯一的模态获取的。模式和阶段之间的对应关系是随机的。与直接在 D 上预训练模型 M 的标准做法不同,MedCoSS 范例在第 t 阶段在每个子集 上顺序预训练 M,其中中间预训练模型由 表示。这种范式通过在预训练期间隔离不同的模态来战略性地规避模态数据冲突,同时面临灾难性遗忘的风险。通过整合基于预演的持续学习技术来保留以前的知识来应对这种风险。当阶段 t 展开时,预训练不仅侧重于使用 的 MIM 借口任务,而且还进行辅助特征蒸馏任务以防止灾难性遗忘。
学习当前的模态 利用 (包括编码器 和三个分词器 、、)以及随机初始化的解码器,在掩码建模借口任务中不断从当前模态数据中学习新知识。
学习以前的模态 建立一个预演缓冲区 保留前面每个阶段的训练数据的一部分。此外,复制 的冻结版本,其中编码器和三个分词器分别表示为、、、。对于来自 B 的每个样本 x,利用模内混合 (IMM) 策略进行增强。增强样本分别由可学习网络(即 、、)和冻结网络(即 、、、 )处理。然后通过最小化 MSE 损失来鼓励两个网络产生的嵌入相似(如图3所示)。
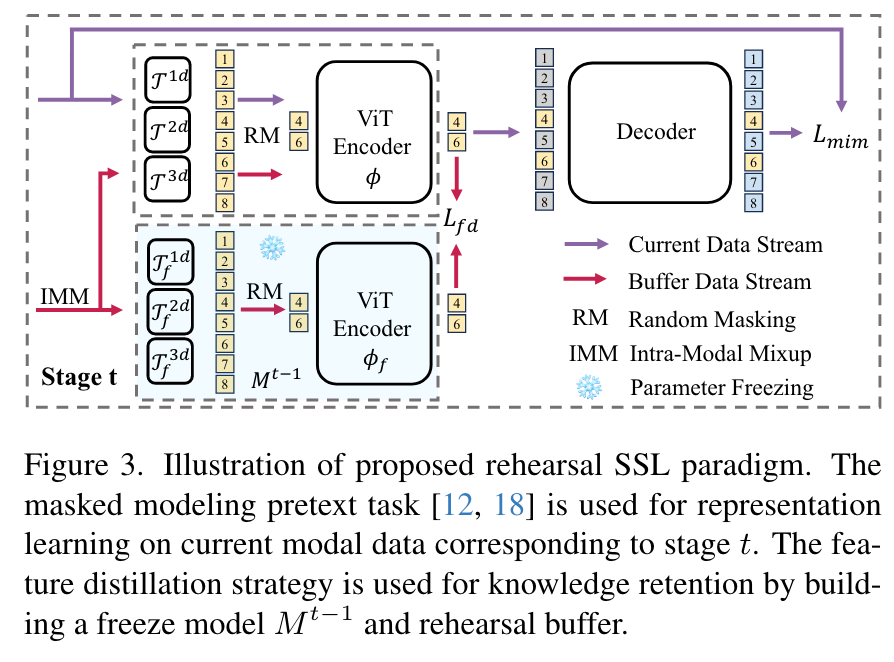
预演缓冲区构建
使用 kmeans 采样策略从每个子集 中选择代表性样本,为后续训练阶段构建预演缓冲区 B。与在捕获数据多样性方面缺乏可靠性的随机采样不同,k 均值采样由两个步骤组成:(1)根据预训练模型产生的嵌入(即, (第t阶段),(2)从每个簇中选择距离中心最近的K个样本。请注意,簇 C 的数量根据经验设置为子集大小的 1%。
IMM 增强策略
在 MedCoSS 中,IMM 增强策略增强了从排练缓冲区 B 中抽取的样本的多样性,以处理每种模态的有限缓冲区大小。
对于文本数据,采用二进制混合策略来合成新的批次,定义为:
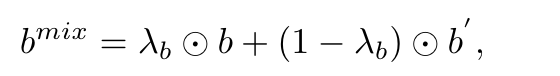
对于视觉数据,增强过程类似地通过复制和混洗图像批次 b 以获得 b' 开始。不同之处在于,这里采用了持续混合策略,表示为:
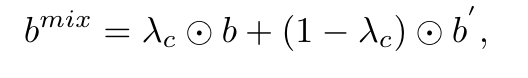
下游任务的微调
在预训练之后,采用预训练的编码器并针对各种下游任务对其进行定制,包括所有看到的模态的分类和分割。给定一个任务,根据输入数据的维度和任务类型设计相应的预测头。使用多层感知器(MLP)头来执行分类任务,并使用带有分割头的基于卷积的解码器来执行分割任务。
实验结果
对于所有 SSL 范例,作者采用掩模建模作为借口任务,并采用 ViT/B 作为具有相同训练周期的骨干。所有这些范例的性能如表 2 所示。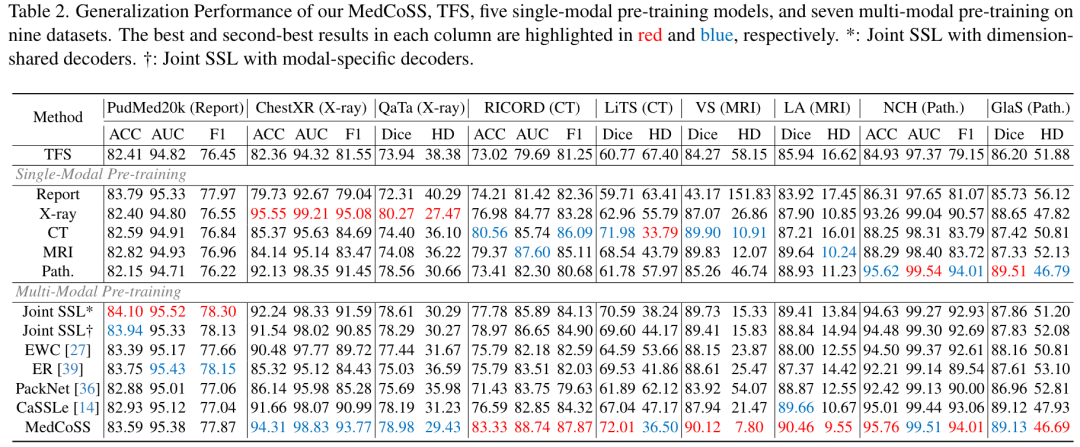
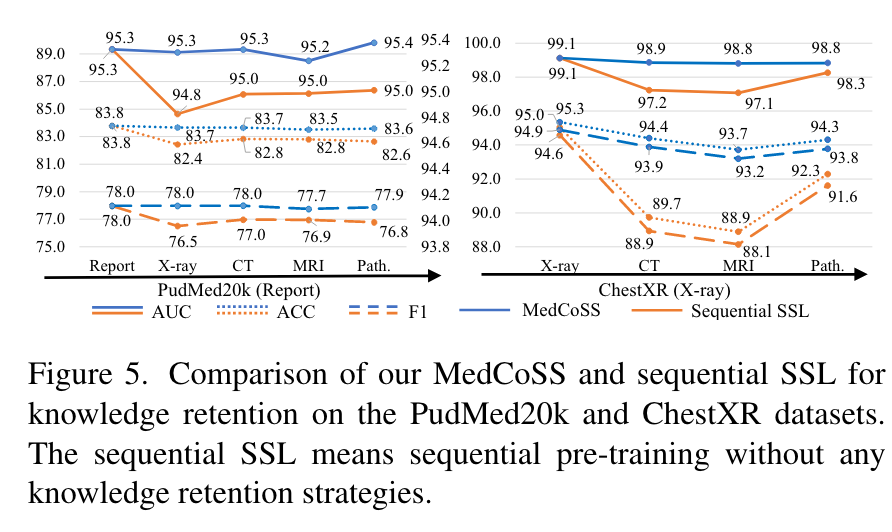
图 5 说明了在多阶段预训练过程中,未采用知识保留策略的 MedCoSS 和顺序 SSL 的性能变化。这一比较清楚地表明,MedCoSS 有效地保留了先前的知识,在连续阶段中表现出轻微的性能下降。相比之下,顺序 SSL 对灾难性遗忘具有显着的敏感性。例如,在 CT 预训练阶段之后,顺序 SSL 经历了明显下降,在 ACC 方面从 95.0% 下降到 89.7%。另一方面,MedCoSS 保持了更稳定的性能,准确率略有下降,从 95.3% 降至 94.4%。

关于论文的详细实施过程和具体解释请阅读论文原文哦~❤️❤️
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









