






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达论文信息
题目:BEVWorld: A Multimodal World Model For Autonomous Driving Via Unified Bev Latent Space
BEVWorld:通过统一的BEV潜在空间实现自动驾驶的多模态世界模型
作者:本文为ICLR 2025投稿,作者信息暂未公开。
论文创新点
多模态令牌化器(Multi-modal Tokenizer):我们设计了一个新颖的多模态令牌化器,它能够将视觉语义和3D几何信息集成到统一的BEV表示中。这一过程通过自监督的方式实现,确保了BEV表示的质量。
潜在BEV序列扩散模型(Latent BEV Sequence Diffusion Model):我们提出了一个基于潜在扩散的世界模型,它能够同步生成未来多视图图像和点云。这一模型在nuScenes和Carla数据集上展示了领先的未来预测性能。
自我监督学习范式:BEVWorld采用了自我监督学习范式,这使得它能够有效地处理大量的未标记多模态传感器数据,从而实现对驾驶环境的全面理解。
下游任务的验证:我们不仅在理论上提出了BEVWorld,还在实际的自动驾驶任务中验证了其有效性,包括3D检测和运动预测等下游任务。
摘要
世界模型因其在自动驾驶中预测潜在未来场景的能力而受到越来越多的关注。在本文中,我们提出了BEVWorld,这是一种新颖的方法,它将多模态传感器输入令牌化到统一且紧凑的鸟瞰图(BEV)潜在空间中,用于环境建模。该世界模型由两部分组成:多模态令牌化器和潜在BEV序列扩散模型。多模态令牌化器首先编码多模态信息,解码器能够通过自我监督的方式通过光线投射渲染重建潜在BEV令牌到激光雷达和图像观测。然后,潜在BEV序列扩散模型根据动作令牌作为条件预测未来场景。实验表明BEVWorld在自动驾驶任务中的有效性,展示了其在生成未来场景和惠及下游任务(如感知和运动预测)方面的能力。代码将很快可用。
关键词
自动驾驶、世界模型、多模态传感器、鸟瞰图(BEV)、潜在空间、自我监督学习
方法
在本节中,我们描述了BEVWorld的模型结构。整体架构如图1所示。给定一系列多视图图像和激光雷达观测值 ,其中 是当前观测值,"+/-"代表未来/过去的观测值, 是过去/未来观测值的数量,我们的目标是预测 ,条件是 。考虑到在原始观测空间中学习世界模型的高计算成本,提出了一个多模态令牌化器,通过帧将多视图图像和激光雷达信息压缩到统一的BEV空间中。编码器-解码器结构和自我监督重建损失保证了BEV表示中适当地存储了几何和语义信息。这种设计为世界模型和其他下游任务提供了一个足够简洁的表示。我们的世界模型被设计为一个基于扩散的网络,以避免自回归方式中的错误累积问题。它以自我运动和 ,即 的BEV表示作为条件,学习添加到 中的噪声 。
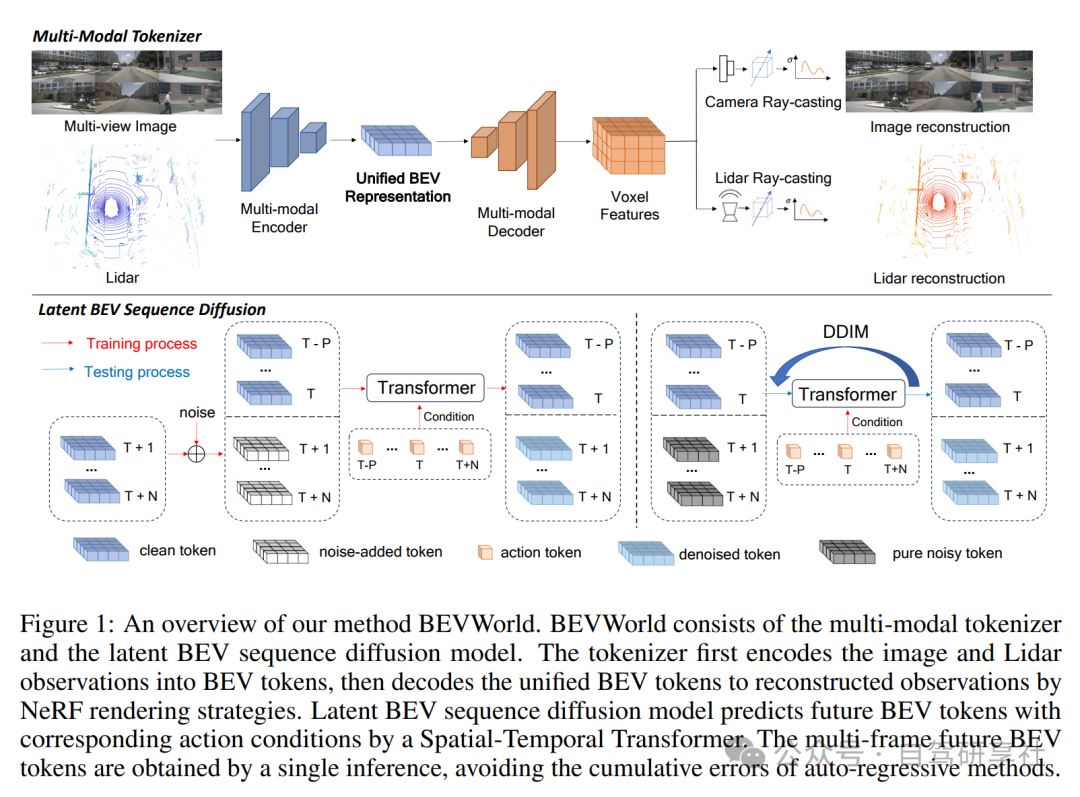
多模态令牌化器
我们设计的多模态令牌化器包含三个部分:BEV编码器网络、BEV解码器网络和多模态渲染网络。BEV编码器网络的结构如图2所示。为了使多模态网络尽可能均匀,我们采用Swin-Transformer网络作为图像主干来提取多图像特征。对于激光雷达特征提取,我们首先将点云在BEV空间分成柱状。然后我们使用Swin-Transformer网络作为激光雷达主干来提取激光雷达BEV特征。我们使用基于变形的变换器融合激光雷达BEV特征和多视图图像特征。具体来说,我们在柱状的高度维度上采样K(K=4)个点,并将这些点投影到图像上以采样相应的图像特征。采样的图像特征被视为值,激光雷达BEV特征被视为变形注意力计算中的查询。考虑到未来预测任务需要低维输入,我们进一步将融合的BEV特征压缩到低维( )BEV特征中。
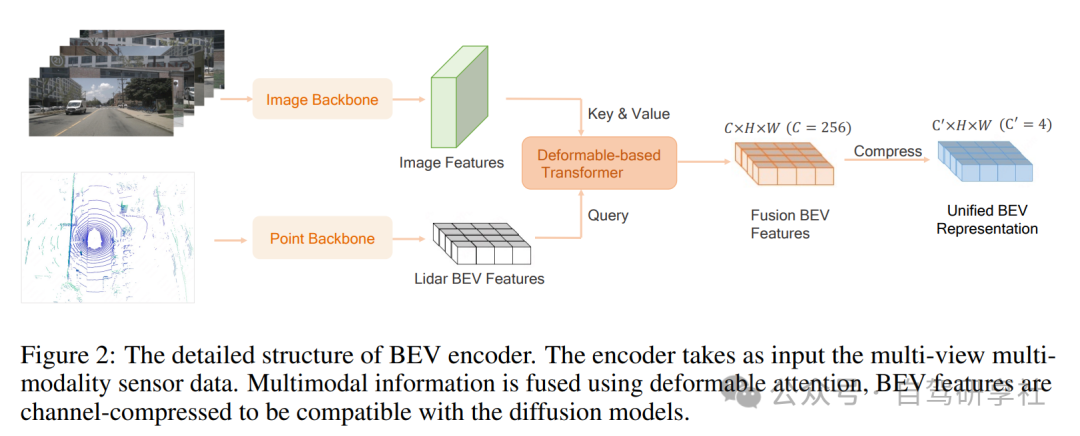
对于BEV解码器,直接使用解码器恢复图像和激光雷达存在歧义问题,因为融合的BEV特征缺少高度信息。为了解决这个问题,我们首先通过堆叠上采样层和Swin块将BEV令牌转换为3D体素特征。然后我们使用基于体素化的NeRF光线渲染技术恢复多视图图像和激光雷达点云。
多模态渲染网络可以优雅地分为两个不同的部分,图像重建网络和激光雷达重建网络。对于图像重建网络,我们首先获得从相机中心o到像素中心d方向的光线r(t) = o + td。然后我们沿光线均匀采样一组点 ,其中Nr(Nr = 150)是沿光线采样的总点数。给定一个采样点 ,根据其位置从体素特征中获得相应的特征vi。然后,沿光线的所有采样特征被聚合为像素级特征描述符。我们遍历所有像素,获得图像的2D特征图V ∈ RHf ×Wf ×Cf。2D特征通过CNN解码器转换为RGB图像Ig。为了提高生成图像的质量,我们添加了三种常见的损失:感知损失、GAN损失和L1损失。我们图像重建的完整目标是:
其中It是Ig的真值, 代表预训练的VGG模型的第j层, 的定义可以在Goodfellow等人(2020)中找到。
对于激光雷达重建网络,光线在球坐标系中定义,具有倾斜角 和方位角 。 和 是通过从激光雷达中心向当前激光雷达点的框架射击获得的。我们以与图像重建相同的方式采样点并获取相应的特征。由于激光雷达编码深度信息,因此计算了采样点的预期深度 以进行激光雷达模拟。深度模拟过程和损失函数如下所示:
其中 表示从激光雷达中心采样点的深度, 是由激光雷达观测计算得到的深度真值。
点云的笛卡尔坐标可以计算为:
总的来说,多模态令牌化器以端到端的方式进行训练,总损失如下所示:
潜在BEV序列扩散
大多数现有的世界模型采用自回归策略来获得更长的未来预测,但这种方法容易受到累积误差的影响。相反,我们提出了一个潜在序列扩散框架,它输入多个帧的噪声BEV令牌,并同时获得所有未来的BEV令牌。
潜在序列扩散的结构如图1所示。在训练过程中,首先从传感器数据中获得低维BEV令牌 。在此过程中只涉及多模态令牌化器中的BEV编码器,且多模态令牌化器的参数是冻结的。为了便于世界模型模块学习BEV令牌特征,我们沿通道维度标准化输入的BEV特征 。最新的历史BEV令牌和当前帧BEV令牌 作为条件令牌,而 被扩散为噪声BEV令牌 ,其中 是扩散过程的时间戳。
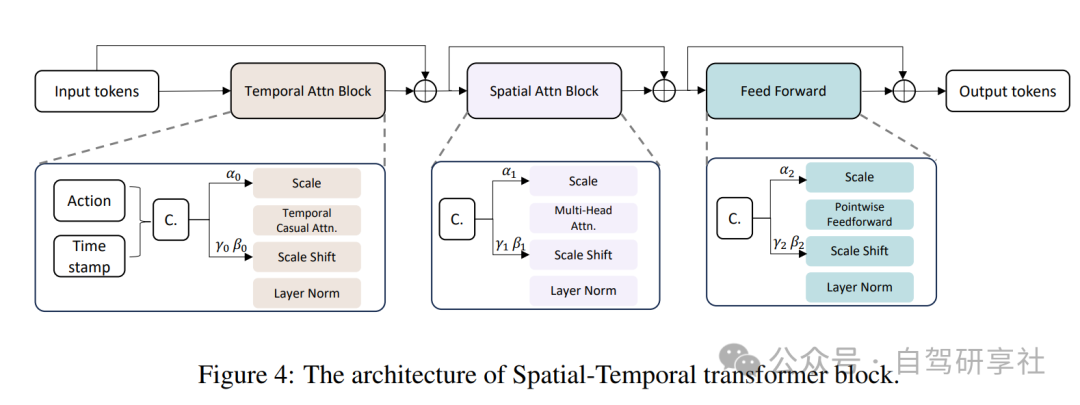
去噪过程是使用包含一系列变换器块的时空变换器进行的,其架构如图4所示。时空变换器的输入是条件BEV令牌和噪声BEV令牌的连接 。这些令牌与动作令牌 的车辆运动和转向一起,形成时空变换器的输入。更具体地说,输入令牌首先传递到时间注意力块以增强时间平滑性。为了避免时间混淆问题,我们在时间注意力中加入了因果掩码。然后,时间注意力块的输出被发送到空间注意力块以获得准确的细节。空间注意力块的设计遵循标准变换器块的标准。动作令牌和扩散时间戳 被连接作为扩散模型的条件 ,然后被发送到AdaLN以调节令牌特征。
其中 是一个变换器块的输入特征, 是c的尺度和偏移。
时空变换器的输出是噪声预测 ,损失如下所示:
在测试过程中,标准化的历史帧和当前帧BEV令牌 和纯噪声令牌 被连接为输入到世界模型。自我运动令牌 ,从时刻T-P到T+N,作为条件输入。我们采用DDIM计划来预测后续的BEV令牌。随后,对预测的BEV令牌进行去标准化操作,然后输入到BEV解码器和渲染网络,得到一套全面的预测多传感器数据。
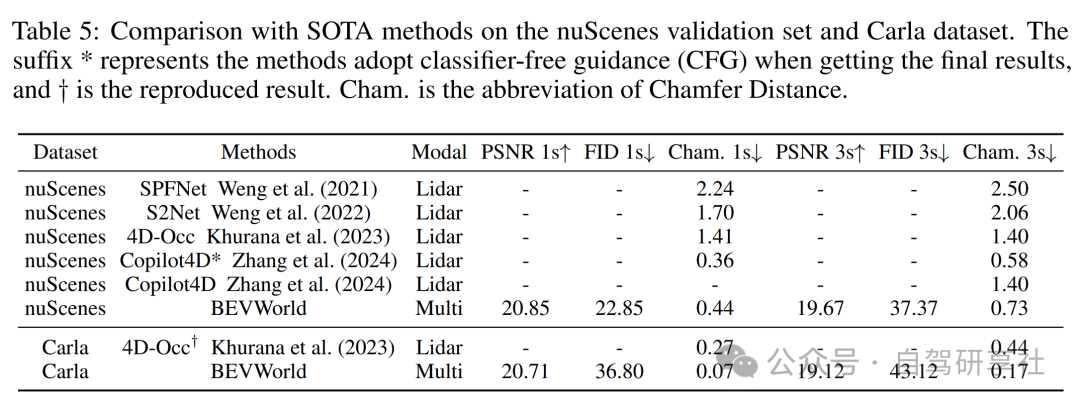
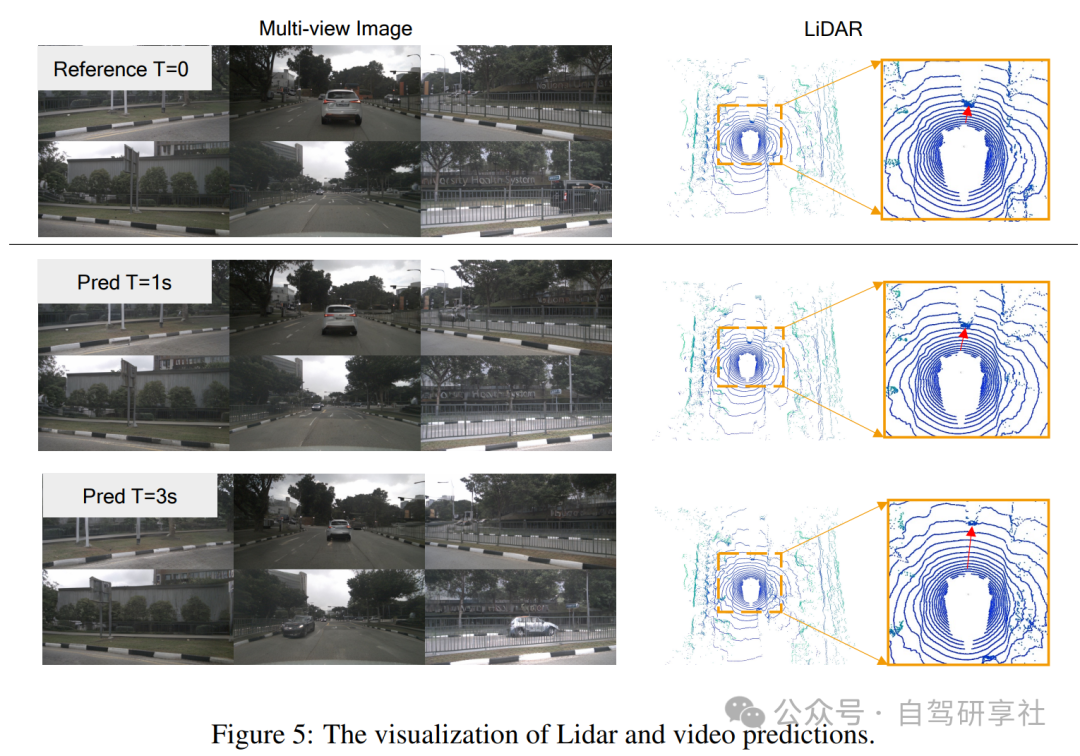
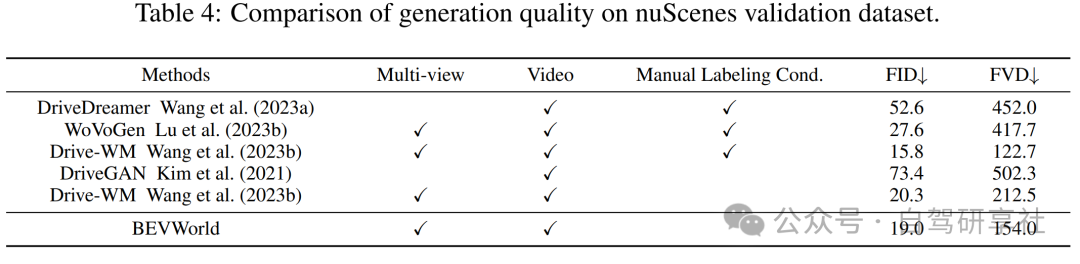
实验
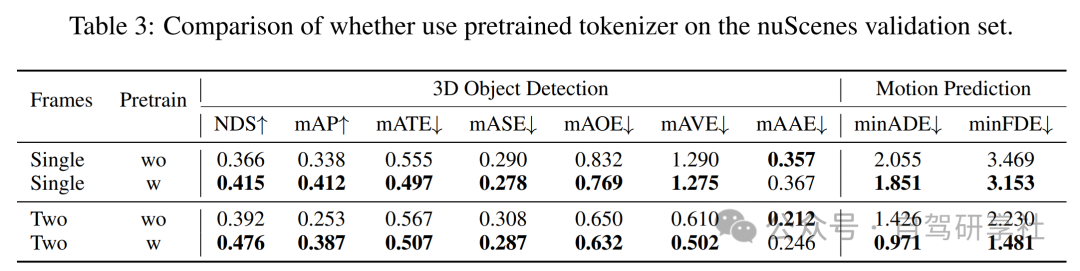

声明
本文内容为论文学习收获分享,受限于知识能力,本文对原文的理解可能存在偏差,最终内容以原论文为准。本文信息旨在传播和学术交流,其内容由作者负责,不代表本号观点。文中作品文字、图片等如涉及内容、版权和其他问题,请及时与我们联系,我们将在第一时间回复并处理。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









