




论文信息
题目:AbdomenAtlas: A large-scale, detailed-annotated, & multi-center dataset for efficient transfer learning and open algorithmic benchmarking
AbdomenAtlas:一个大规模、详细注释和多中心的数据集,用于高效迁移学习和开放算法基准测试
作者:Wenxuan Li, Chongyu Qu, Xiaoxi Chen, Pedro R.A.S. Bassi, Yijia Shi, Yuxiang Lai, Qian Yu
源码链接:https://www.zongweiz.com/dataset
论文创新点
-
大规模、多中心数据集:本文介绍了迄今为止最大的腹部CT数据集(AbdomenAtlas),包含来自112家医院的20,460个三维CT体积,涵盖了不同人群、地理区域和设施。该数据集提供了673,000个高质量的腹部区域解剖结构掩码,这些掩码由10名放射科医生在AI算法的帮助下进行注释。
-
半自动注释程序:本文提出了一种半自动注释程序,结合了放射科医生的专业知识和AI算法,显著提高了注释效率。放射科医生修订AI预测的注释,而AI则通过学习修订后的注释来改进其预测。这种人机协同将创建大规模、详细注释数据集的效率提高了168倍。
-
高效的迁移学习模型:本文介绍了一套大型预训练模型(SuPreM),能够在众多下游任务中实现高效的迁移学习。这些模型在AbdomenAtlas上进行预训练,并在多个医学影像任务中表现出色,特别是在少样本学习和细粒度肿瘤识别方面。
-
开放算法基准测试:本文与ISBI和MICCAI合作举办了BodyMaps挑战赛,使用AbdomenAtlas进行开放的算法基准测试,评估AI在医学图像分割中的可靠性、效率和泛化能力。该挑战赛特别关注分布外(OOD)评估和难以分割的结构,促进了公平、鲁棒和可靠的AI算法的开发。
摘要
我们介绍了迄今为止最大的腹部CT数据集(称为AbdomenAtlas),包含来自112家医院的20,460个三维CT体积,涵盖了不同人群、地理区域和设施。AbdomenAtlas提供了673,000个高质量的腹部区域解剖结构掩码,这些掩码由10名放射科医生在AI算法的帮助下进行注释。我们首先由专家放射科医生手动注释了5,246个CT体积中的22个解剖结构。随后,对剩余的CT体积进行了半自动注释程序,放射科医生修订了AI预测的注释,而AI则通过学习修订后的注释来改进其预测。如此大规模、详细注释和多中心的数据集有两个主要原因。首先,AbdomenAtlas为大规模AI开发提供了重要资源,特别是作为大型预训练模型,可以减轻专家放射科医生的注释工作负担,并将其转移到更广泛的临床应用中。其次,AbdomenAtlas为评估AI算法建立了一个大规模的基准——我们使用的数据越多,越能保证算法在复杂临床场景中的可靠性能。我们使用AbdomenAtlas的一个子集发起了名为BodyMaps的ISBI和MICCAI挑战赛,旨在刺激AI创新,并基准测试分割精度、推理效率和领域泛化能力。我们希望AbdomenAtlas能够为更大规模的临床试验奠定基础,并为医学影像社区的从业者提供卓越的机会。代码、模型和数据集可在https://www.zongweiz.com/dataset获取。
关键字
注释、数据集、迁移学习、基准测试
I. 引言
大型预训练模型已经彻底改变了自然语言处理(NLP)领域,例如GPTs(Brown等,2020)和LLaMA(Touvron等,2023)。然而,尽管计算机视觉(CV)领域正在进行热烈的探索,但实现类似变革性模型的路线图仍然在展开中。当前的CV策略多种多样:仅使用像素(例如LVM(Bai等,2023))、结合像素和文本(例如LLaVA(Liu等,2023a)),或结合详细的人工注释(例如SAM(Kirillov等,2023))。尽管这些策略显示出潜力,但它们尚未达到语言模型的成功水平,无法广泛适用于各种目标任务。这种多样性反映了处理图像数据与文本数据相比的固有复杂性和多样化需求(Zhang和Metaxas,2023)。
共识是,大型预训练模型必须在大量、多样化的数据集上进行训练(Moor等,2023;Blankemeier等,2024)。我们必须走的道路是准备大量、多样化的数据集——如果它们被注释过,那就更好了。对于语言模型来说,获取非常大且多样化的数据集相对容易(例如Common Crawl存储库中的2500亿个网页)。对于视觉模型来说,我们距离拥有类似规模和多样性的数据源还很远(例如LAION-5B数据集中的58.5亿张图像(Schuhmann等,2022))。特别是,医学视觉与计算机视觉有些相似,但在寻找大规模数据集方面相对较新,尤其是在最主流的3D医学图像方面(Blankemeier等,2024)。此外,医学图像的一个独特问题延伸到数据收集、成像协议和患者人口统计的差异(McKinney等,2020;Singh等,2022),这在大多数现有数据集中往往被忽视,如表1和第2.1节所述。这引发了关于预训练模型泛化能力的迫切关注。
本文并不打算讨论如何在医学影像中创建类似GPT的视觉模型,而是致力于提供可能催化此类讨论所需的数据和注释。我们收集并注释了20,460个CT体积,总计673,000个高质量的腹部区域解剖结构掩码。这些CT体积来自112家医院,分布在19个国家,使得这一努力在规模上前所未有。这是迄今为止最大规模的医学数据集,用于AI基准测试,并有望成为医学领域大型预训练模型开发的宝贵资产。我们将此数据集命名为AbdomenAtlas。需要来自不同中心的大规模数据集有两个主要原因:(I)已知AI算法的性能在训练数据越多时越好;我们使用的数据越多,越能保证算法在现实世界条件下(例如临床环境)的良好性能。(II)在不同中心的数据上训练和测试AI算法至关重要,因为AI研究人员发现,在一个中心的数据上训练的算法可能无法泛化到其他中心的数据(如DeGrave等(2021)和Geirhos等(2020)所示)。
在本文的其余部分,我们首先回顾了现有的公开医学数据集,并在第2节中强调了AbdomenAtlas的独特属性。然后,我们在第3节中详细描述了AbdomenAtlas的构建过程,详细介绍了对5,246个CT体积进行耗时的手动注释以及对剩余的15,214个CT体积进行高效的半自动注释程序。接着,我们介绍了AbdomenAtlas的两个实际应用。首先,第4节介绍了一套大型预训练模型(SuPreM),能够在众多下游任务中实现高效的迁移学习,特别分析了迁移学习的效率和能力。其次,第5节描述了与ISBI和MICCAI合作举办的国际竞赛(BodyMaps),提供了开放的算法基准测试,评估AI在医学图像分割中的可靠性、效率和泛化能力。最后,第6节总结了当前建立大规模、详细注释和多中心数据集的局限性和未来前景。
II. AbdomenAtlas及相关数据集
2.1 现有的公开数据集
2.1.1 经典数据集(<500 CT体积)
经典数据集可以分为两类。第一类:那些为特定病理条件设计的数据集,例如LiTS(肝脏肿瘤)、KiTS(肾脏肿瘤)和Pancreas-CT(胰腺肿瘤)。这些数据集通常提供更多的CT体积(数百个),但仅注释特定类型的解剖结构和肿瘤。第二类:那些为通用目的设计的数据集,例如BTCV(12个结构)和WORD(16个结构)。这些数据集注释了更多类型的结构,但由于注释成本,它们通常规模较小(数十个)。这些经典数据集在表1中进行了回顾,它们一直是训练和验证最先进AI算法的宝贵公共资源。作为一项重大进展,我们的AbdomenAtlas提供了比这些经典数据集多50倍的CT体积和5倍的解剖结构(类别)。
2.1.2 腹部多器官分割(AMOS)
AMOS数据集(Ji等,2022)包括500个CT体积和100个MRI扫描,来自患有各种腹部疾病的患者和不同的CT扫描仪。它提供了15个解剖结构的详细注释,对于跨模态学习非常有价值。然而,这些数据仅来自亚洲的两家医院,且未注释重要的结构,如肠道和结肠。相比之下,AbdomenAtlas的规模要大得多,涵盖了来自47倍多的医院、19倍多的国家的CT体积,并包括10个额外的腹部结构注释。
2.1.3 AbdomenCT-1K
AbdomenCT-1K数据集(Ma等,2021)提供了来自12家医院的1,112个CT体积,整合了五个现有数据集和新获取的CT体积。它包括多期相、多厂商和多疾病的病例。然而,它仅注释了四个结构(肝脏、肾脏、脾脏、胰腺)。相比之下,AbdomenAtlas包含62.5倍多的腹部结构注释,提供了更全面的3D人体表示。
2.1.4 医学分割十项全能(MSD)CT
MSD-CT数据集(Antonelli等,2021)包括1,420个CT体积,跨越六个分割任务,注释了九个解剖结构——使其成为开发可泛化的医学图像分割算法的宝贵资源。与部分注释的MSD-CT数据集不同,AbdomenAtlas是完全注释的。我们提供了大约34,000个新掩码,比原始MSD-CT数据集提供的掩码多35倍,如图1-属性III所示。
2.1.5 TotalSegmentator V2
TotalSegmentator数据集(Wasserthal等,2022)包括1,228个CT体积,专注于117个解剖结构的全身分割。它源自巴塞尔大学医院,涵盖了不同年龄、病理、扫描仪、身体部位和序列的多样化病例。然而,TotalSegmentator存在三个主要问题:(1)CT体积质量:由于从原始512×512分辨率调整到大约300×300以简化数据传输,TotalSegmentator中的CT体积质量较低。这种调整过程不可避免地导致细粒度信息的丢失。相比之下,AbdomenAtlas提供了原始分辨率的CT体积,总计1.8 TB,并且我们已尽力简化数据传输,例如使用Huggingface、Dropbox、Google Drive和百度网盘。(2)注释质量:TotalSegmentator对某些类别的注释质量较低,尤其是像肠道和结肠这样的管状结构,以及肋骨和脊椎等骨骼结构。虽然TotalSegmentator仅使用半自动标注,但我们在AbdomenAtlas中手动注释了5,246个CT体积,然后对剩余的CT体积使用半自动方法,这代表了更大的努力。此外,TotalSegmentator的注释由两名分别具有三年和六年经验的放射科医生修订。相比之下,我们的团队包括十名经验更丰富的放射科医生,经验从三年到十五年不等。(3)标签生成过程:TotalSegmentator中的标签主要由一个不断重新训练的nnU-Net生成,如图1b所示(Wasserthal等,2022)。仅依赖nnU-Net可能会引入潜在的标签偏差,偏向于nnU-Net架构。这一点在nnFormer、UNETR和Swin UNETR在TotalSegmentator中均被nnU-Net及其衍生模型超越的结果中得到了证实(Huang等,2023b)。为了减轻这种偏差,AbdomenAtlas在半自动注释过程中采用了三种不同的架构(Swin UNETR、U-Net和nnU-Net)。
2.1.6 FLARE’23
FLARE’23数据集(Ma等,2022)包含来自30多家医院的4,100个CT体积,注释了13个腹部结构和一种肿瘤类别。然而,只有2,200个体积被部分注释,1,900个没有注释。这种不完整的注释是由于该数据集是从多个现有数据集中组装的,每个数据集都专注于特定的腹部结构或肿瘤。与部分注释的FLARE’23不同,AbdomenAtlas完全注释了20,460个CT体积,包含25个解剖结构。此外,AbdomenAtlas提供了更高的注释质量,如图1-属性II中的胃部示例所示。此外,FLARE’23中大多数注释的结构是较大的结构,相对容易被人类和AI检测/分割。AbdomenAtlas提供了难以分割的解剖结构的注释,如肝血管、肠道和结肠。
2.2 AbdomenAtlas的四个属性
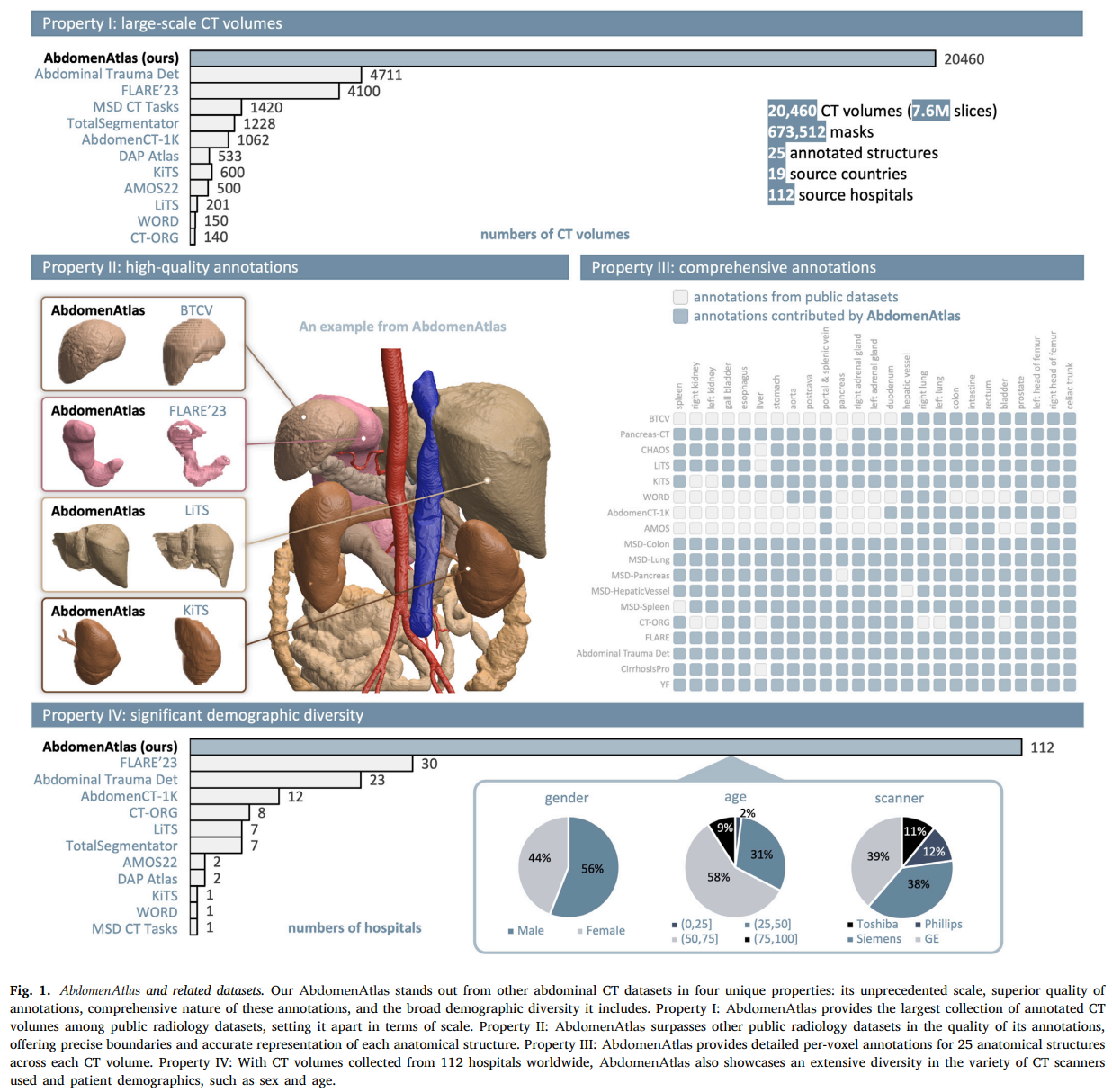
2.2.1 属性I:大规模CT体积
AbdomenAtlas提供了20,460个注释的CT体积,如图1-属性I所示,关联了超过760万注释的CT切片。除了提供AbdomenAtlas的详细信息外,表1还展示了其组件和用于训练(AbdomenAtlas 1.1)和测试(FullBodyAtlas-1K和AbdomenAtlas-9K)的细分。AbdomenAtlas不仅代表了用于AI训练的医学数据的显著增加,还作为AI基准测试的广泛资源。在AbdomenAtlas中,9,262个注释的CT体积将在AbdomenAtlas 1.1中公开,用于AI算法的开发,而1,761个注释的CT体积已经在FullBodyAtlas-1K中公开,用于算法基准测试,这要归功于TotalSegmentator(Wasserthal等,2022)和DAP Atlas(Jaus等,2023)。此外,我们已经组装并注释了来自15家医院的9,437个CT体积,称为AbdomenAtlas-9K,这些数据将保留用于严格的外部验证。AbdomenAtlas的规模——20,460个CT体积和673,000个掩码——使得开发和评估适用于广泛医学影像任务的AI算法成为可能。
2.2.2 属性II:高质量注释
创建673,000个高质量的25个解剖结构掩码需要广泛的医学知识——至少需要三年的解剖结构培训,以及显著的注释成本——每个结构大约需要放射科医生一小时的时间来注释(Park等,2020)。如第3.1节所述,我们基于人体解剖学(Dixon等,2017)建立了严格的注释标准,以指导放射科医生准确注释或修订每个结构,确保质量控制。该标准在保持我们注释质量方面的有效性如图1-属性II所示,其中AbdomenAtlas中的注释显示了精确的边界和准确的解剖结构分割,与BTCV、FLARE’23、LiTS和KiTS中的注释相比。
2.2.3 属性III:全面注释
如图1-属性III所示,我们为25个解剖结构提供了全面的逐体素注释,确保了一个完全标注的数据集,而不是从公共数据集的简单组合中得到的部分标注数据集。值得注意的是,与仅包含39,000个掩码的组合不同,我们的AbdomenAtlas 1.1为这些CT体积提供了231,000个注释的结构掩码,显著增加了5.9倍的可用掩码。这一增加不仅增强了数据集的实用性,还使得在医学影像分析中进行大规模、监督的(预)训练成为可能。
2.2.4 属性IV:显著的人口多样性
AbdomenAtlas是一个多中心数据集,包含来自112家全球医院的预、门、动脉、静脉和延迟期CT体积。如图1-属性IV所示,AbdomenAtlas展示了人口多样性,患者性别分布均衡,女性占56%,男性占44%,年龄范围广泛。值得注意的是,58%的患者年龄在25至50岁之间,31%在50至75岁之间,9%在25岁以下,2%在75岁以上。此外,AbdomenAtlas包括来自不同扫描仪的CT体积,如西门子、GE、飞利浦和东芝,并涵盖了16/64层MDCT和双源MDCT的CT体积。这些多样性在期相、医院、国家、人口统计、扫描仪和扫描类型方面丰富了AbdomenAtlas,确保使用AbdomenAtlas开发的AI算法能够有效处理不同成像协议或患者体位引起的结构外观变化,例如沿垂直轴旋转30至60度。研究表明,训练数据的多样性是AI分布鲁棒性的关键(Fang等,2022)。因此,AbdomenAtlas的多样性有助于开发能够适应现实世界临床环境中多样化设置的鲁棒、公平和可泛化的AI算法。
III. AbdomenAtlas的构建
注释质量和一致性是我们构建AbdomenAtlas的首要任务。因此,我们首先建立了一个全面的注释协议和标准(第3.1节),旨在其他团队在构建类似数据集时可重复使用。基于该标准,我们应用了两种互补的注释程序。首先,我们采用了手动注释程序——放射科医生逐体素地注释每个CT体积,确保高质量但需要大量时间投入(第3.2节)。其次,我们采用了结合放射科医生专业知识和AI算法的半自动注释程序(第3.3节)——放射科医生根据突出潜在错误的注意力图修订AI预测。这种人机协同将创建大规模、详细注释数据集的效率提高了168倍。在发布之前,四名资深放射科医生需要验证AbdomenAtlas中的所有注释。
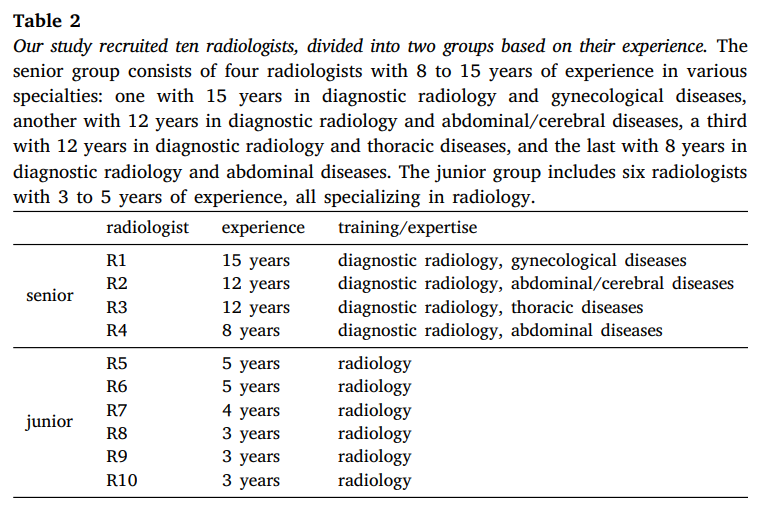
3.1 注释协议和标准
我们的研究招募了十名放射科医生,包括四名具有8至15年经验的资深放射科医生和六名具有3至5年经验的初级放射科医生。详细信息如表2所示。为了确保注释的准确性和一致性,所有放射科医生都熟悉了以下描述的注释标准。我们使用的工具包括Pair的许可版本和开源的3DSlicer进行注释和修订。我们为AbdomenAtlas中的25个结构提供了注释标准,包括16个腹部器官(食管、胃、十二指肠、肠道、结肠、直肠、肝脏、胆囊、脾脏、胰腺、左肾、右肾、左肾上腺、右肾上腺、膀胱、前列腺)、2个胸部器官(左肺、右肺)、5个血管结构(主动脉、腹腔干、下腔静脉、门静脉和脾静脉、肝血管)以及2个骨骼结构(左股骨和右股骨)。图2展示了一个详细注释的CT体积示例。
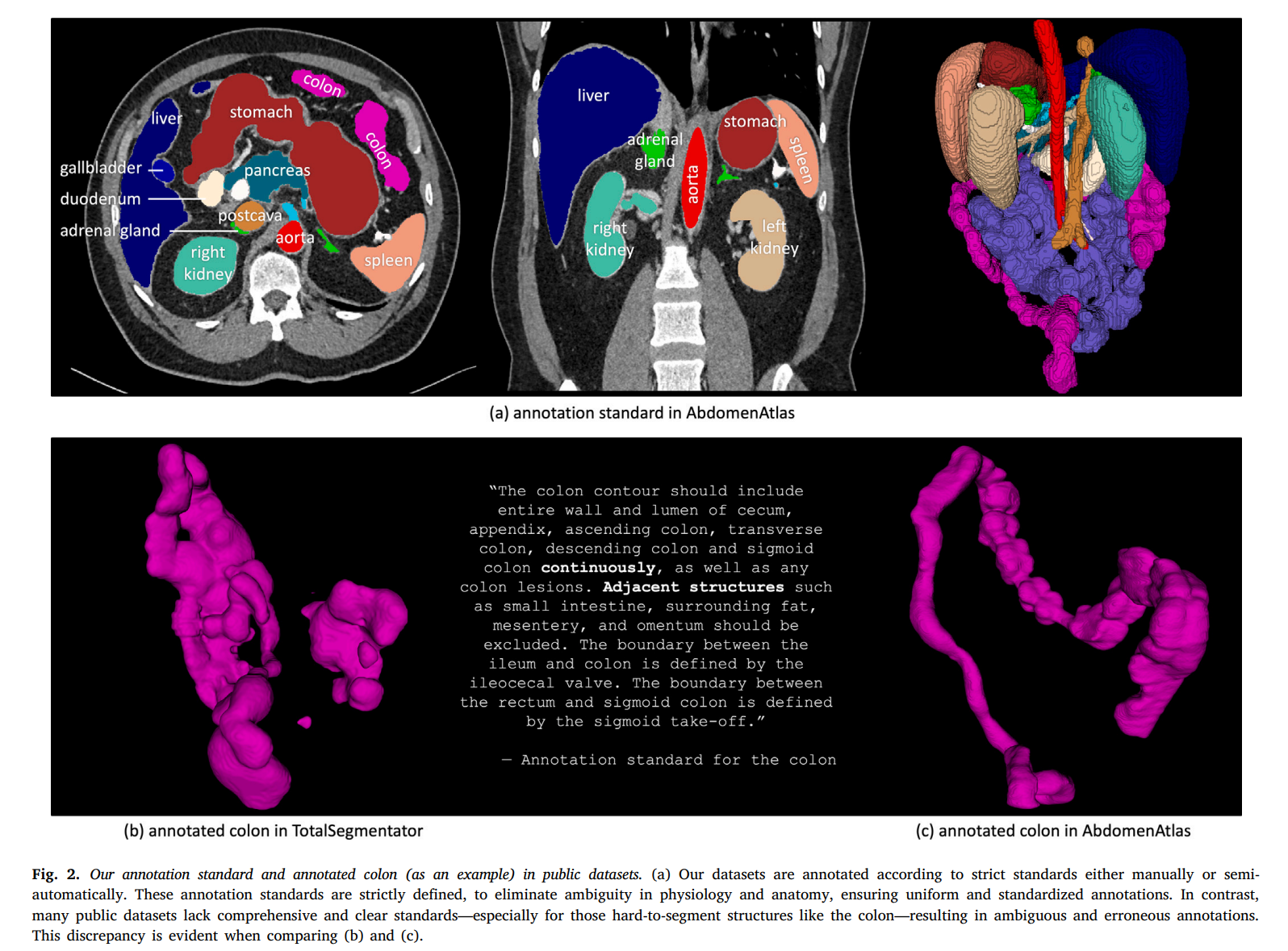
3.1.1 腹部器官(胃肠道)
胃的轮廓应包括整个胃壁和胃腔,包括胃底、胃体、胃窦和幽门,以及任何胃部病变,同时排除相邻结构、器官和周围脂肪。十二指肠的轮廓应包括从十二指肠球部到Treitz韧带的整个十二指肠壁和腔,以及任何十二指肠病变,同时排除周围结构,如胰头、胆总管和周围血管。肠道的轮廓应包括从Treitz韧带到回盲瓣的空肠和回肠壁和腔,以及任何肠道病变,同时排除周围脂肪、肠系膜和肠系膜血管。结肠的轮廓应包括盲肠、阑尾、升结肠、横结肠、降结肠和乙状结肠的整个壁和腔,以及任何结肠病变,同时排除相邻结构、周围脂肪、肠系膜和网膜。直肠的轮廓应包括整个直肠壁、腔和任何病变,同时排除相邻结构、周围脂肪和肌肉。
3.1.2 腹部器官(其他)
肝脏的轮廓应包括所有肝实质和任何病变,肝内血管和肝内胆管需要覆盖,同时排除周围脂肪、相邻结构和器官。胆囊的轮廓应包括整个胆囊壁和腔,包括胆囊底、体和颈,以及任何胆结石或息肉,同时排除胆囊管、周围肝实质和脂肪。胰腺的轮廓应包括所有胰腺实质,包括胰头、体和尾,以及任何胰腺病变和胰管,同时排除周围血管和脂肪。脾脏的轮廓应包括所有脾实质和任何病变,同时排除相邻结构和脾外血管。肾上腺(左/右)的轮廓应包括整个肾上腺和任何肾上腺病变,同时排除相邻结构和周围脂肪。肾脏(左/右)的轮廓应包括肾实质,排除肾盂、输尿管、肾外血管、周围脂肪和任何相邻结构。膀胱的轮廓应包括整个膀胱壁、腔和任何膀胱病变,同时排除相邻结构和周围脂肪。前列腺的轮廓应包括整个前列腺实质、前列腺尿道和任何前列腺病变,同时排除相邻结构、周围脂肪和前列腺静脉丛。
3.1.3 胸部器官
食管的轮廓应包括整个食管壁和腔,以及任何食管病变,同时排除相邻结构,如气管、主动脉和周围脂肪和肌肉。肺(左/右)的轮廓应包括整个肺实质、肺支气管血管束、脏层胸膜和任何肺部病变,同时排除胸腔积液、气胸、壁层胸膜、纵隔结构和胸壁。
3.1.4 血管结构
主动脉和腹腔干的轮廓应包括整个动脉腔。动脉壁和钙化、溃疡、血栓和夹层也应包括在内。下腔静脉和门静脉及脾静脉的轮廓应包括整个腔并覆盖壁,以及腔内血栓和肿瘤血栓。肝血管的轮廓应包括所有肝内血管壁和腔,以及腔内血栓和肿瘤血栓。
3.1.5 骨骼结构
股骨(左/右)的轮廓应包括皮质骨和松质骨,以及任何病变,同时排除周围肌肉和血管。
3.2 耗时的手动注释程序
手动注释程序涉及放射科医生根据第3.1节定义的注释标准逐体素地注释每个CT体积。虽然这种方法可以确保准确性和一致性,反映数据的特定需求和需求,但它耗时、劳动密集且容易受到人为错误或偏见的影响。注释单个结构的时间可能从几分钟到几小时不等,具体取决于要注释的感兴趣区域的大小和复杂性以及局部周围的解剖结构(Park等,2020)。此程序用于注释JHH数据集:一组放射科医生为每个CT体积注释了22个结构,并由三名经验丰富的放射科医生中的一名确认,以确保注释的质量(Xia等,2022)。JHH涉及5,246个CT体积,耗时数年完成,需要15名放射科医生的努力。
AbdomenAtlas中手动注释的精度确保每个解剖结构都被明确定义,准确捕捉身体的难以分割的细节。如图2所示,AbdomenAtlas在难以分割的结构(如结肠)的精确手动注释方面表现出色,展示了与TotalSegmentator等数据集的明显优势,后者可能在注释中错误地包含相邻结构或注释不连续。尽管存在这些问题,TotalSegmentator仍然是一个有价值的数据集,因为在公共数据集中为难以分割的结构提供精确注释是罕见的。这主要是因为手动注释这些结构是一项细致且耗时的任务。没有一个公共数据集在5,246个CT体积中为这些结构提供手动注释,这使得AbdomenAtlas在规模和注释方面都脱颖而出。
然而,将这种方法应用于我们AbdomenAtlas中剩余的15,214个CT体积的注释是非常耗时的。假设一个训练有素的放射科医生每天工作8小时,每周工作5天,通常需要60分钟来注释单个CT体积中的每个解剖结构(Park等,2020)。因此,要注释所有15,214个CT体积,一名放射科医生需要60 × 25 × 15,214(分钟)/60/8/5 = 9,508(周)= 182.9(年)。这促使我们开发了一种更高效的注释程序。
3.3 半自动注释程序
半自动注释程序结合了三种不同的AI算法——以最小化模型架构带来的偏差——在标记的CT体积的公共数据集上。这些AI算法为未标记的CT体积生成初始注释。我们开发了一种创新策略,可以找到AI预测中最重要的部分,并使用颜色协调的注意力图向放射科医生展示在手动审查AI工作时需要关注的区域(Qu等,2023;Li等,2024)。如图3所示,重复此过程——AI预测和人工审查——使我们能够将注释过程加速168倍。
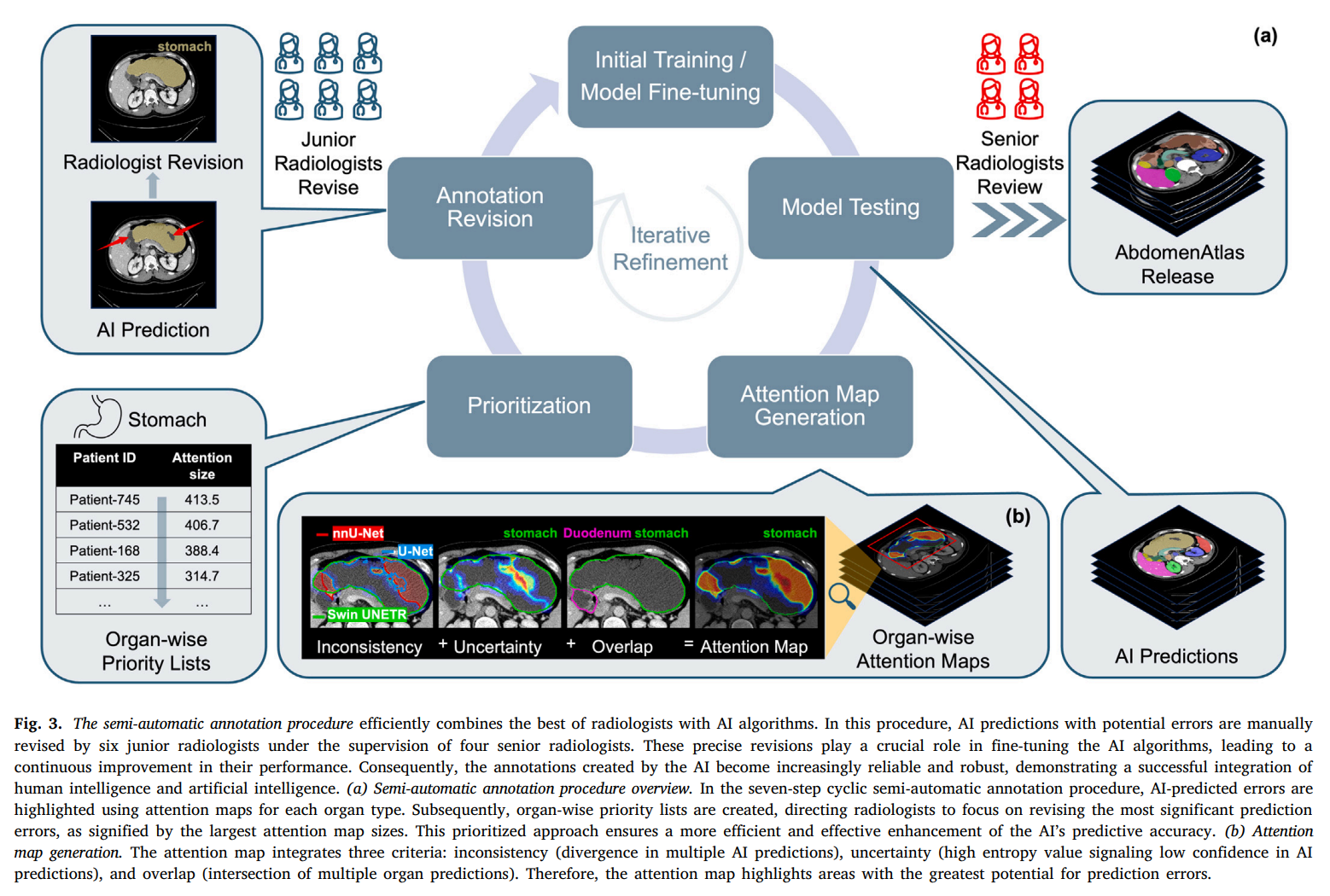
3.3.1 注意力图揭示AI错误
我们开发了注意力图来突出AI预测中的潜在错误,指导放射科医生在审查和修订过程中。这些图为AI更可能犯错的区域分配更高的值,指示需要优先审查的区域。注意力图使用以下三个标准计算。
-
不一致性是来自三种AI架构(包括Swin UNETR、nnU-Net和U-Net)的软预测的标准差。具有高标准差的区域表示模型预测的高度分歧,提示需要额外的手动修订。不一致性 i , c _{i,c} i,c的计算公式为:
Inconsistency i , c =
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1459
1459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











