







好消息!加入知识星球,详细阅读本文PDF完整版
论文信息
题目:EHCTNet: Enhanced Hybrid of CNN and Transformer Network for Remote Sensing Image Change Detection
EHCTNet:基于CNN和Transformer增强混合网络的遥感图像变化检测
作者:Junjie Yang, Haibo Wan, Zhihai Shang
论文创新点
双分支混合架构:论文提出了一种双分支混合架构,结合了CNN和Transformer块,以有效整合局部和全局特征。
新颖模块设计:作者设计了头残差快速傅里叶变换(HFFT)、基于KAN的通道和空间注意力块(CKSA)和尾残差快速傅里叶变换(BFFT)等新颖模块。
增强令牌挖掘:论文引入了基于增强令牌挖掘的Transformer模块,通过KAN层生成语义令牌,并利用Transformer编码器和解码器捕捉全局语义关系。
频率分量精炼:通过精炼模块I和II,论文提出了一种对称的FFT结构,用于精炼特征图像和语义图的频率分量。
摘要
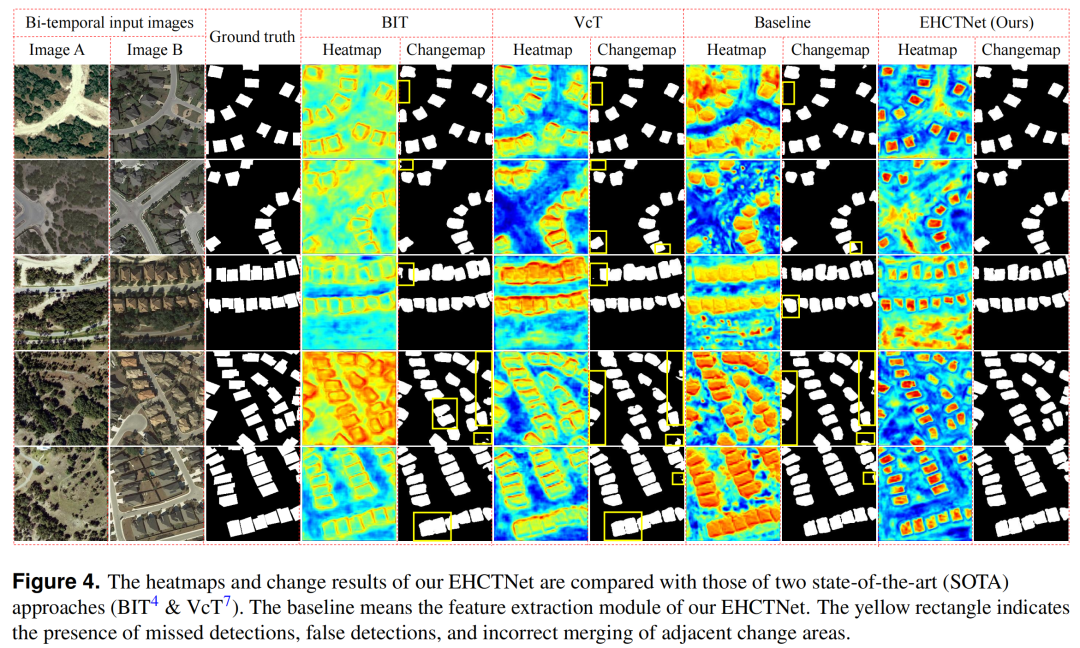
遥感(RS)变化检测由于漏检(false negatives)的高成本而面临挑战,漏检的成本通常高于误检(false positives)。现有的框架在提高Precision指标以减少误检成本方面存在局限,难以专注于感兴趣的变化,导致漏检和不连续问题。本文通过增强特征学习能力和整合特征信息的频率分量来解决这些问题,并提出了一种逐步提升Recall值的策略。作者提出了一种增强的CNN和Transformer混合网络(EHCTNet),用于有效挖掘感兴趣的变更信息。首先,使用双分支特征提取模块提取RS图像的多尺度特征。其次,通过改进的模块I利用这些特征的频率分量。第三,基于Kolmogorov-Arnold网络的增强令牌挖掘模块用于提取语义信息。最后,从改进的模块II中挖掘出对最终检测有益的语义变化信息的频率分量。大量实验验证了EHCTNet在理解复杂变化方面的有效性。可视化结果表明,EHCTNet能够检测到更完整和连续的变化区域,并且在相邻区域的区分上比现有最先进的模型更为准确。
关键字
遥感图像,变化检测,卷积神经网络,Transformer,Kolmogorov-Arnold网络,频率分量
III. 提出的方法
EHCTNet的整体架构包括五个模块:1)特征提取模块,2)精炼模块I,3)基于增强令牌挖掘的Transformer模块,4)精炼模块II,以及5)检测头模块,如图1所示。特征提取模块由CNN和Transformer的双分支混合架构(HCT)组成,旨在从双时相图像中提取原始多尺度特征。HCT结合了CNN的局部特征提取能力和Transformer的全局上下文特征学习能力,显著增强了原始特征表示。精炼模块I位于特征提取模块之后,是一个频率注意力模块,旨在精炼原始多级特征的频率细节并生成一阶特征。基于增强令牌挖掘的Transformer模块采用一阶精炼特征作为输入,以获取语义信息。精炼模块II位于EHCTNet的深层,与精炼模块I对称,也是一个频率注意力模块,旨在精炼基于增强令牌挖掘的Transformer模块中的语义信息的频率分量,并生成二阶语义差异信息。精炼模块I主要帮助模型获取每个图像的精炼频率特征,这对变化检测有益,而精炼模块II用于从语义差异图中学习高层次的语义差异信息。最后,检测头用于生成变化图。
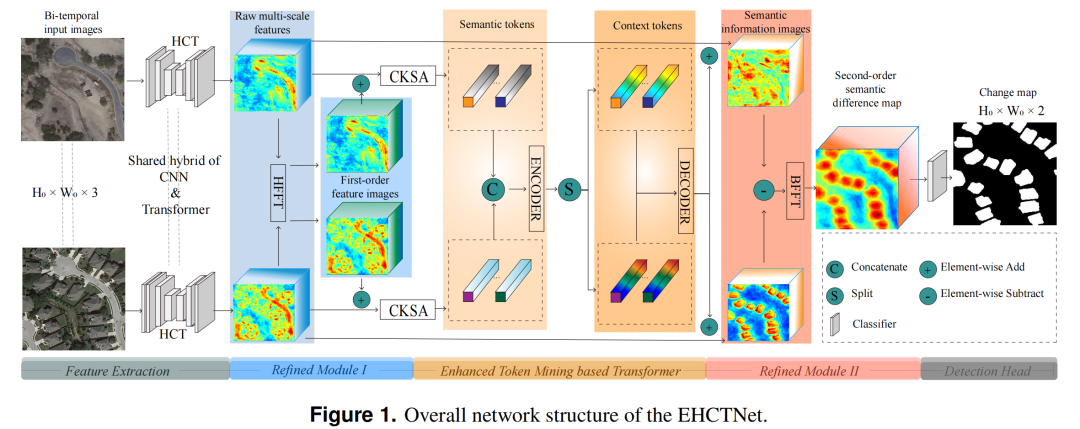
特征提取模块
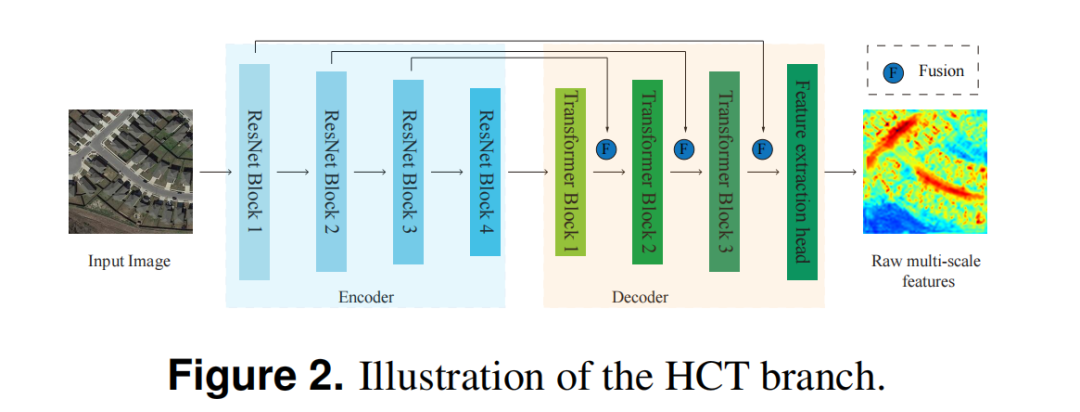
受混合思想和CMTFNet模型的启发,作者构建了一个双HCT块,称为特征提取模块,以融合局部特征和全局特征。特征提取模块的两个分支共享可学习参数,结构相同。每个分支都是一个HCT,HCT的结构如图2所示。编码器部分使用ResNet50编码层次特征,而解码器部分由3个Transformer块组成,用于解码多尺度全局上下文特征。为了融合局部层次特征和全局上下文特征,在前三个解码器块之后执行融合操作。前两次融合操作捕捉了丰富的局部特征和全局上下文信息,但缺乏空间细节。因此,第三次融合对于整合来自第一个CNN模块的空间特征(如辐射强度、边缘、角落和纹理)至关重要。解码器生成多尺度全局上下文信息,并通过融合从CNN模块获得的层次特征逐步恢复特征分辨率。此外,使用一个可学习变量来权衡局部特征和全局上下文信息在融合过程中的重要性。因此,两个元素对输出的贡献公式为:
其中表示融合的输出,表示可学习变量,是编码器部分的局部特征输出,是解码器部分的全局上下文信息输出。
精炼模块I
结合光谱层和多头注意力机制,模型可以实现最先进的性能。因此,作者设计了由精炼模块I、基于增强令牌挖掘的Transformer模块和精炼模块II组成的联合模块,这些模块位于特征提取模块之后。精炼模块I生成一阶特征,这些特征有助于表示每个原始特征图像中的详细信息。在本文中,精炼模块I主要由快速傅里叶变换(FFT)层、加权门控机制和逆FFT层组成,可以表示为:
其中是、和操作的输出,是原始特征图像,、和分别表示精炼模块I中的FFT、加权门控机制和逆FFT过程。
公式2中的FFT层将特征图从物理空间转换到频谱空间。加权门控机制作为神经网络中的可学习权重参数,可以通过训练过程中的反向传播调整其权重,有效识别特征图中的频域特征,从而确定每个频率分量在特征表示中的重要性。逆FFT将特征图从频谱空间转换回空间域,从而生成具有增强细节的精炼频率特征,称为一阶特征。
最后,精炼模块I的输出通过残差连接保留原始特征图像中的特征。上述过程可以表示为:
其中是精炼模块I的输出。
基于增强令牌挖掘的Transformer模块
特征提取模块在前两个步骤中从双时相RS图像中提取并融合多尺度特征。然后,作者利用精炼模块I获取一阶特征。在这一步中,基于增强令牌挖掘的Transformer模块用于语义令牌提取和语义信息感知。基于增强令牌挖掘的Transformer模块由两个单元组成:基于KAN的通道和空间注意力(CKSA)块和Transformer单元。
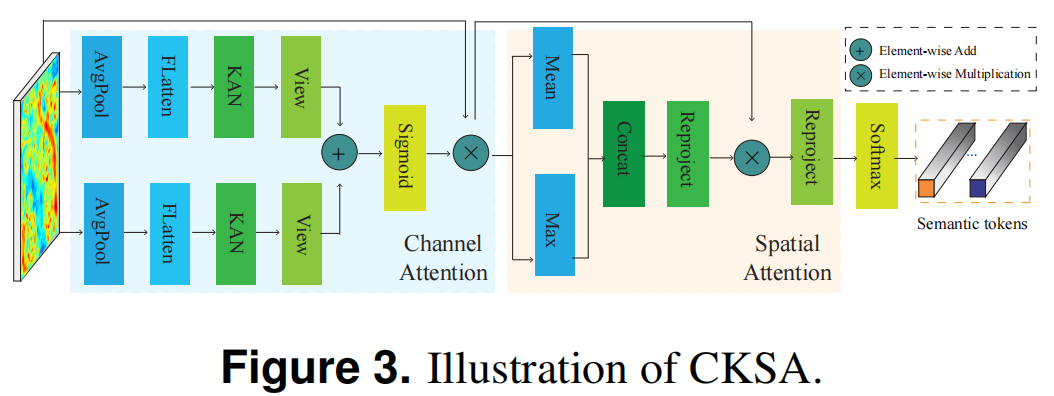
语义令牌操作有助于在遥感变化检测任务中与变化信息进行交互。语义令牌表示感兴趣变化的高层次概念。它是变化检测中的关键元素之一。此外,KAN层在网络边缘促进定制激活学习并计算每个输入通道的贡献的能力已在计算机视觉领域和RS领域得到验证。受KAN层能力的启发,作者首先设计了CKSA块(图3),以生成两个浓缩令牌集,用于精确学习该模块中的语义令牌。CKSA块主要由通道和空间注意力单元组成。具体来说,作者用KAN层替换了全连接层。在CKSA中,将特征图像转换为令牌的过程可以表示为:
其中是CKSA的输出令牌,CKA表示基于KAN的通道注意力操作,SA表示空间注意力操作。
CKSA获取图像特征的令牌,这些令牌包含特征图像中变化的丰富细节,但缺乏令牌之间的交互关系语义信息。Transformer可以充分利用令牌空间中的高层次全局语义关系。因此,作者在基于增强令牌挖掘的Transformer模块的后续阶段引入了一个Transformer块。首先,将来自CKSA的两个令牌集连接起来形成令牌聚合,然后将其输入Transformer的编码器以捕捉这些令牌之间的全局语义上下文。由于令牌聚合涉及沿第二维度()连接语义令牌集,因此可以将其比作将两捆令牌条绑定在一起。因此,Transformer编码器可以提取一组令牌内的内部关系和两组语义令牌之间的相互关系。结果,Transformer编码器的输出富含了令牌内的高层次语义信息和令牌间的全局语义信息。
作者将高层次语义上下文分为两组上下文令牌,每组具有与CKSA令牌相同的维度。这两组上下文令牌封装了浓缩的语义上下文,并代表了热点的高层次信息。随后,部署Transformer解码器将这两组上下文令牌恢复到像素空间中的双语义像素图。双分支像素图富含高质量的语义信息,使得每个像素都可以由两组上下文令牌表示。这种表示有效地突出了语义图中感兴趣的像素值。
语义像素图有效地揭示了特征空间中的语义热点。随后,将语义像素图相减以获得语义差异图,该图表示变化的语义信息。语义像素图之间的减法可能导致正负结果。为了确保所有值均为非负,作者将任何负结果转换为其绝对值,定义为:
其中和表示语义像素图的像素值,表示通过取减法绝对值生成的语义差异图的像素值。
精炼模块II
精炼模块I的HFFT和精炼模块II的BFFT在EHCTNet模型的早期和晚期阶段对称放置,如图1所示。与HFFT类似,BFFT也包括FFT层、加权门控、逆FFT层和残差连接。BFFT用于精炼语义差异图并生成二阶语义差异图。精炼模块II可以表示为:
其中是精炼模块II的输出。
在本小节中,首先将语义差异图重新缩放以匹配原始RS图像的尺寸。BFFT将重新缩放的语义差异图的物理空间转换为频谱空间,在其中描绘语义差异图的详细信息。然后将其恢复为物理空间,从而在精炼的语义差异图中生成二阶语义差异信息。
检测头
精炼语义差异图中的二阶语义差异信息表示语义信息的最终阶段。它直接用于检测头模块以区分变化区域和背景区域。检测头中采用全卷积网络生成变化图,其维度为,其中和表示原始双时相RS图像的高度和宽度。
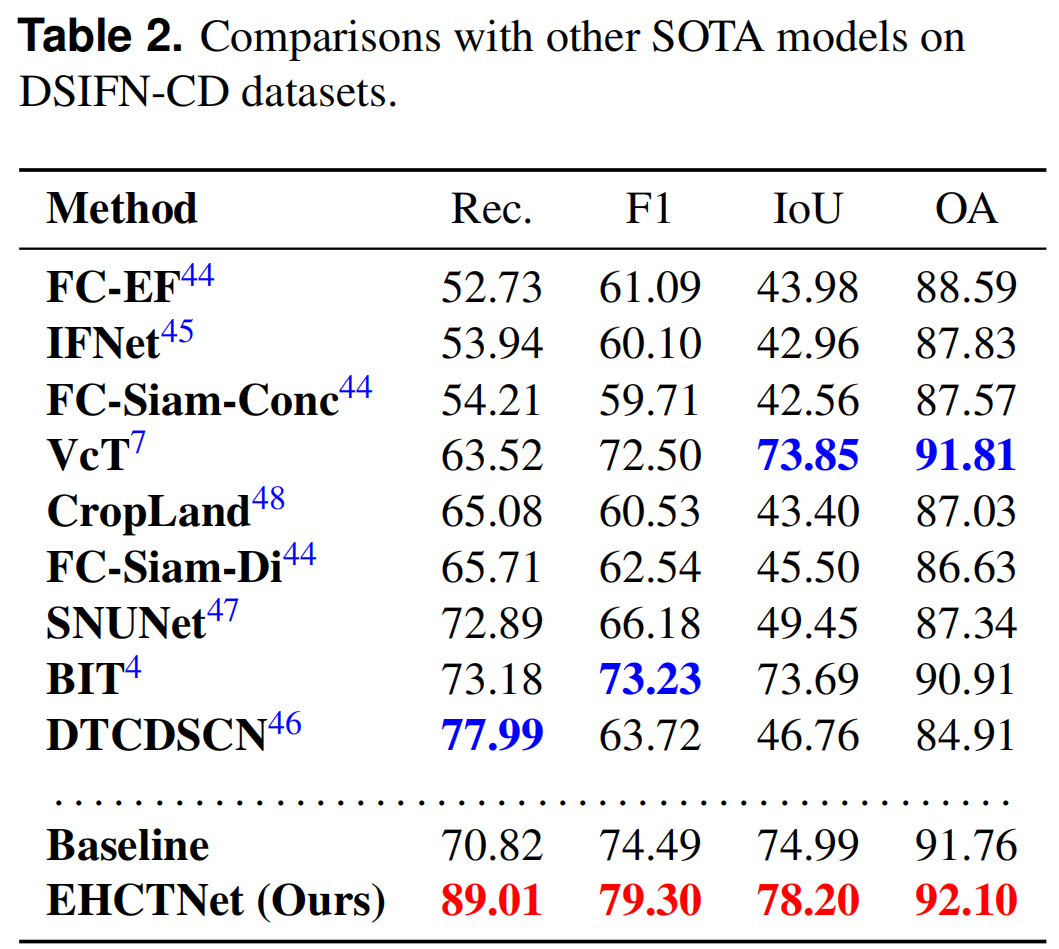
IV. 实验与分析

声明
本文内容为论文学习收获分享,受限于知识能力,本文对原文的理解可能存在偏差,最终内容以原论文为准。本文信息旨在传播和学术交流,其内容由作者负责,不代表本号观点。文中作品文字、图片等如涉及内容、版权和其他问题,请及时与我们联系,我们将在第一时间回复并处理。

#论 文 推 广#
让你的论文工作被更多人看到
你是否有这样的苦恼:自己辛苦的论文工作,几乎没有任何的引用。为什么会这样?主要是自己的工作没有被更多的人了解。
计算机书童为各位推广自己的论文搭建一个平台,让更多的人了解自己的工作,同时促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。 计算机书童 鼓励高校实验室或个人,在我们的平台上分享自己论文的介绍、解读等。
稿件基本要求:
• 文章确系个人论文的解读,未曾在公众号平台标记原创发表,
• 稿件建议以 markdown 格式撰写,文中配图要求图片清晰,无版权问题
投稿通道:
• 添加小编微信协商投稿事宜,备注:姓名-投稿

△长按添加 PaperEveryday 小编



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









