







好消息!加入知识星球,详细阅读本文PDF完整版
论文信息
题目:When Fast Fourier Transform Meets Transformer for Image Restoration
快速傅里叶变换与Transformer结合用于图像恢复
作者:Xingyu Jiang , Xiuhui Zhang , Ning Gao , and Yue Deng
源码:https://github.com/deng-ai-lab/SFHformer
论文创新点
提出创新框架:提出了SFHformer框架,将快速傅里叶变换机制融入Transformer架构,为图像恢复提供了一种高效的解决方案。具体而言,设计了一种双域混合结构用于多尺度感受野建模,其中空间域和频域分别专注于局部建模和全局建模。
设计独特模块:设计了独特的位置编码和频率动态卷积,用于每个频率分量以提取丰富的频域特征。此外,还引入了多尺度表示学习,通过多内核感受野聚合局部和全局特征,增强了模型对不同尺度特征的捕捉能力。
采用混合损失函数:引入了一种双域损失函数,包括空间域损失和频域损失,以更好地约束预测图像与真实图像的相似性,提升了模型在图像恢复任务中的性能。
实现多任务高效恢复:在多个图像恢复任务上进行了广泛实验,包括去雨、去雾、去雪、去雨滴、运动模糊去除、单图像散焦模糊去除、图像降噪、图像超分辨率、水下图像增强和低光图像增强等,实验结果表明SFHformer在性能、参数大小和计算成本之间实现了良好的平衡,超越了现有方法。
摘要
自然图像可能会受到不利大气条件或独特退化机制导致的各种退化现象影响。这种多样性使得设计一个通用的图像修复框架来应对各类修复任务颇具挑战。现有图像修复方法并非探索不同退化现象间的共性,而是在有限的修复先验条件下,专注于网络架构的改进。在这项工作中,作者首先从频率角度回顾了各种退化现象,并将其作为先验知识。在此基础上,作者提出了一种高效的图像修复框架SFHformer,该框架将快速傅里叶变换机制融入Transformer架构。具体而言,作者设计了一种双域混合结构用于多尺度感受野建模,其中空间域和频率域分别侧重于局部建模和全局建模。此外,作者为每个频率分量设计了独特的位置编码和频率动态卷积,以提取丰富的频域特征。在31个修复数据集上针对诸如去雨、去雾、去模糊、去雪、去噪、超分辨率以及水下/低光照增强等10种修复任务进行的大量实验表明,SFHformer超越了当前最先进的方法,并在性能、参数规模和计算成本之间实现了良好的平衡。
三、方法
所提出的SFHformer采用了一个五阶段的分层编码器 - 解码器结构:一个两尺度编码器(阶段1和阶段2)、一个瓶颈层(阶段3)以及一个两尺度解码器(阶段4和阶段5)。在本节的其余部分,作者将首先介绍SFHformer的整体架构(见图2),然后描述所提出的SFHformer模块的核心组件:(a)局部 - 全局感知混合器(LGPM)和(b)多内核卷积前馈网络(MCFN)。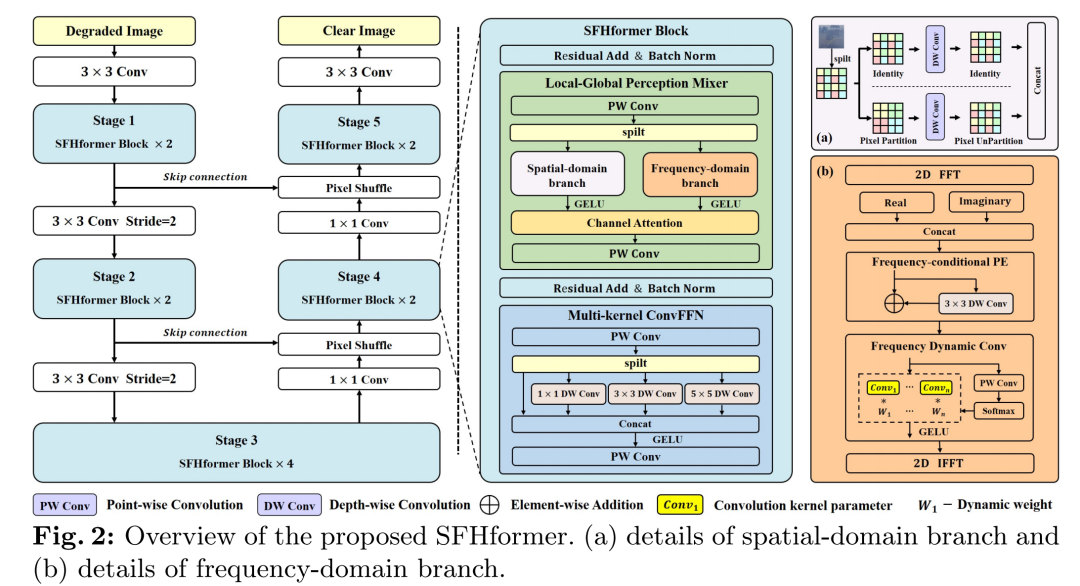
3.1 整体架构
如图2所示,给定一个退化图像 ,SFHformer首先应用一个 卷积来提取低级特征 ;其中 表示空间维度, 是通道数。接下来,浅层特征 依次通过一个5阶段的分层编码器 - 解码器结构。在每个阶段之间,空间分辨率在编码器中通过下采样操作( ,步长为2的卷积层)逐渐降低,然后在解码器中通过上采样操作(像素混洗)提高。在每个阶段内部,输入特征 通过 个SFHformer模块,以提取多尺度潜在特征 。然后,为了保留修复所需的结构和纹理特征,低级潜在特征 ( )通过跳跃连接与高级潜在特征 ( )连接。最后,对最终的潜在特征 应用一个 卷积层,生成残差图像 ,通过 得到清晰图像 。在接下来的两个小节中,作者将介绍两个基本模块的配置:LGPM和MCFN。
3.2 局部 - 全局感知混合器
顾名思义,LGPM被配置为局部 - 全局建模结构,它由两个关键分支组成:用于局部感知的空间分支和用于全局感知的频率分支。如图2所示,LGPM首先应用一个逐点卷积 将输入特征 的通道维度翻倍。接下来,增加后的特征 被分成两部分: 和 ,它们随后分别通过空间域分支和频率域分支。然后,作者采用通道注意力操作来保持通道级别的特征聚合。最后,应用另一个逐点卷积得到降维后的特征 。空间域分支和频率域分支的实现细节将在以下段落中描述。
空间域分支:空间域分支专注于捕捉像素级别的局部和区域相关性的空间特征。具体来说,如图2a所示,输入特征 首先被分成两个数据流: 和 ,其中 保持不变,通过深度可分离卷积 提取局部特征,而另一个 进行像素划分以获得半全局感受野来提取区域特征。在实际应用中,为了提高效率,作者采用扩张卷积 来实现区域感受野。最后,作者聚合来自两个数据流的特征,得到深度空间特征 。上述描述可以表示为:
频率域分支:频率域分支专注于捕捉围绕整个图像的全局建模的频率特征。在此,作者回顾一下傅里叶变换,它广泛用于分析图像的频率特性。给定一个图像 ,快速傅里叶变换(FFT) 将其转换到频率空间,成为复数分量 ,其表达式为:
其中 和 是傅里叶空间的坐标。 表示逆快速傅里叶变换(IFFT)。由FFT公式(2)可知,频域中的各个分量对应于空间域中特定的像素集,因此需要对每个频率分量进行不同的处理。因此,为了有效地提取各种退化过程中独特的频率特征,作者引入了两个核心组件。首先,作者实现了频率条件位置编码(FCPE),为每个频率分量分配一个独特的标识。其次,作者引入了频率动态卷积(FDC),允许根据每个频率分量的输入进行灵活建模。这些设计利用定制的处理方法,有效地利用了每个频率分量的独特特征。
具体来说,如图2b所示,输入特征 首先通过一个二维FFT ,得到频域中的复数特征:实部 和虚部 。接下来,与分别从实部和虚部提取特征不同,作者在通道维度上聚合实部 和虚部 ,得到联合特征 。然后, 依次通过两个关键模块:FCPE和FDC。在FCPE中,由深度可分离卷积 建模的位置编码以残差的形式合并到 中,得到特征 。FCPE可以写为:
在FDC中,作者进行逐点卷积 和softmax操作,为一系列可学习的卷积参数 获取动态权重 。因此,在傅里叶空间中坐标为 处的频率动态卷积 可以写为:
最后,作者应用二维IFFT将调制后的频率特征转换回空间域。
3.3 多内核卷积前馈网络
前馈网络(FN)是Transformer中广泛采用的有效模块,但先前的研究[83, 98]表明,标准的FN在利用局部连接进行图像修复任务方面能力有限。为了解决这一限制,作者引入了多尺度表示学习[76],它将高维特征分成多个部分,从不同的感受野中提取局部关系。如图2所示,MCFN首先利用逐点卷积 将输入特征 的维度翻倍。然后,作者引入多内核卷积 将翻倍后的特征 分成多个头,并且在每个头中,应用各种内核大小的深度可分离卷积来提取局部信息。最后,在连接所有多内核特征后,应用另一个逐点卷积 得到降维后的特征 。整个操作可以表示为:
其中 是GELU激活函数,在多内核卷积 之后使用,以引入非线性。
3.4 损失函数
受[20, 22]的启发,作者在优化流程中引入了与频域分支一致的双域损失,如公式(6)所示,它由两部分组成:空间域损失和频域损失。
其中采用 损失来约束预测图像 与真实图像 相似, 设置为0.1以平衡双域学习。
四、实验与分析
4.2 实验结果
去雾:在表1中,作者的方法在所有五个合成和真实世界去雾数据集上,在PSNR和SSIM方面均取得了最佳性能。此外,值得注意的是,作者的方法在SOTS [38]室内和室外数据集上,仅用了MB - TaylorFormer [65] 52.1%的参数数量和30.2%的FLOPs,PSNR就分别比之前的SOTA方法高出0.39 dB和0.74 dB。如图3所示,与最先进的方法相比,作者的方法在颜色恢复和局部 - 全局层面的去雾方面表现更好。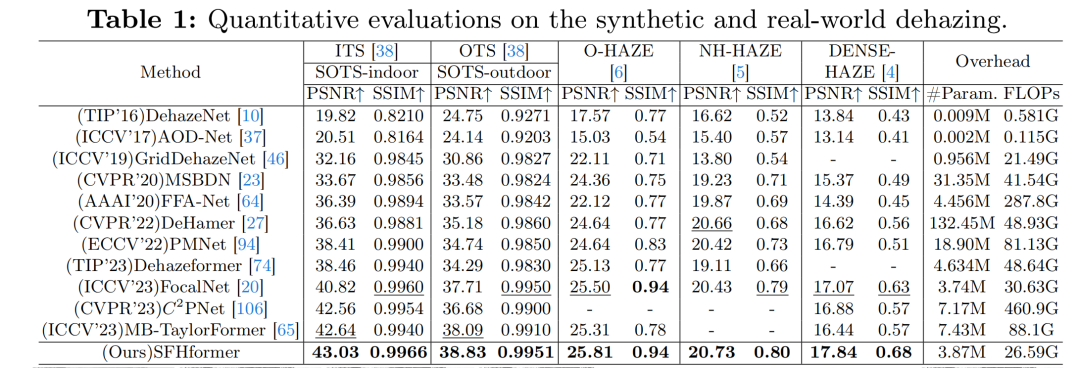

去雨:在表2中,作者的方法在所有五个合成和真实世界去雨数据集上,在PSNR和SSIM方面均取得了最佳性能。令人印象深刻的是,作者的方法在rain100L [91]和SPA - Data [82]数据集上,仅用了DRSformer [16] 22.6%的参数数量和20.8%的FLOPs,PSNR就分别比之前的SOTA方法高出0.62 dB和1.58 dB。如图4所示,在颜色和纹理方面,作者的方法恢复出的视觉质量与真实图像最为相似。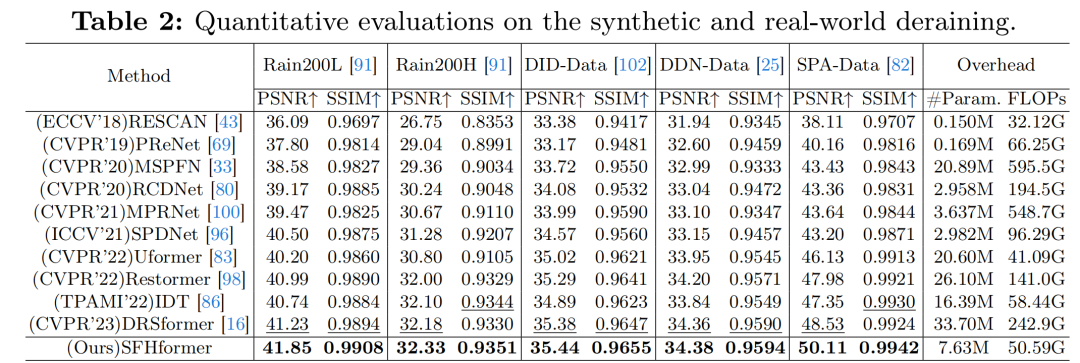

运动去模糊:表3展示了与SOTA运动去模糊方法在GoPro [55]和HIDE [73]数据集上的定量结果。在实际应用中,作者的模型仅在GoPro数据集上训练,并直接应用于HIDE数据集。作者的方法在GoPro [55]数据集上,比SOTA模型Restormer [98]在PSNR上提高了1.09 dB。图5展示了评估模型的视觉比较,作者的方法生成的结果更清晰,视觉上更忠实,具有更多高频细节。对于RealBlur [72],作者应用[98]的设置,将在GoPro上训练的模型应用于RealBlur数据集。

低光照增强:如表4所示,作者的模型在LOL - v1 [84]和LOL - v2 [93]数据集上,在PSNR和SSIM方面超越了大多数SOTA方法。特别是,作者的方法在LOL - v2 - real [93]数据集上,仅用了Retinexformer [11] 64.6%的参数数量和49.8%的FLOPs,PSNR就比之前的SOTA方法高出0.98 dB。如图6所示,作者的模型实现的对比度恢复与真实图像最为相似,而其他方法往往表现出过度明亮或黑暗的情况。FiveK [9]的详细结果可在补充材料中找到。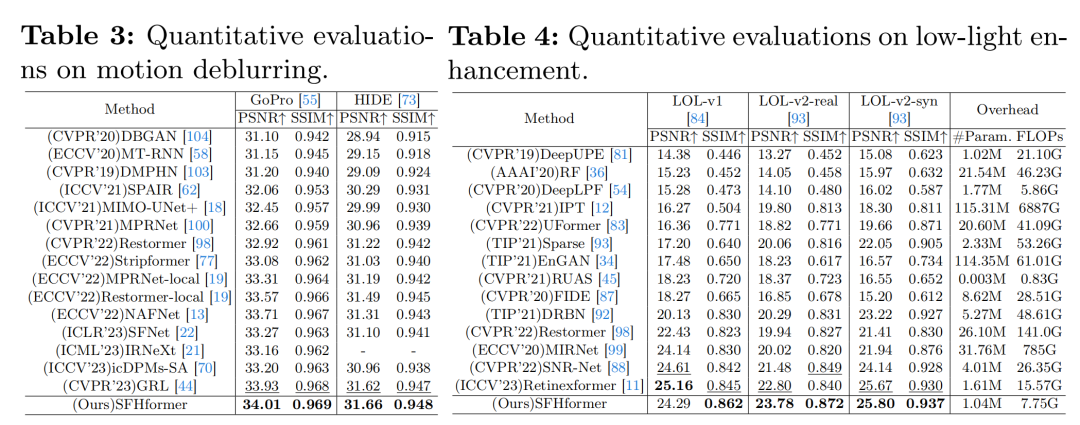 水下增强:如表5所示,作者的模型在UIEB [40]和LSUI [61]数据集上,在PSNR、SSIM和UCIQE [90]方面超越了大多数SOTA方法。特别是,作者的方法在LSUI和UIEB数据集上,仅用了URSCT - SESR [71] 34.4%的参数数量,PSNR就分别比之前的SOTA方法高出0.87 dB和0.82 dB。如图7所示,作者的方法重建出的水下修复图像与真实图像最为相似,并且在深水区域实现了更好的恢复质量。
水下增强:如表5所示,作者的模型在UIEB [40]和LSUI [61]数据集上,在PSNR、SSIM和UCIQE [90]方面超越了大多数SOTA方法。特别是,作者的方法在LSUI和UIEB数据集上,仅用了URSCT - SESR [71] 34.4%的参数数量,PSNR就分别比之前的SOTA方法高出0.87 dB和0.82 dB。如图7所示,作者的方法重建出的水下修复图像与真实图像最为相似,并且在深水区域实现了更好的恢复质量。
去雪:如表6所示,作者的模型在三个广泛使用的去雪数据集上,在PSNR和SSIM方面取得了最佳性能,且计算复杂度和参数规模较小。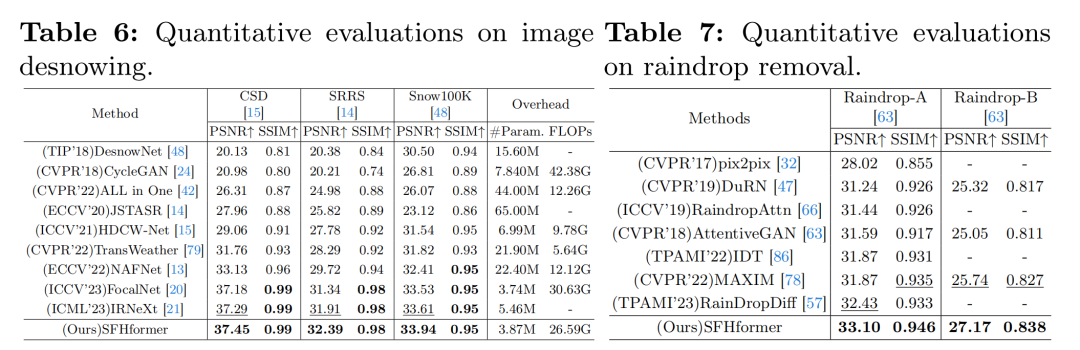
雨滴去除:如表7所示,作者的模型在PSNR和SSIM方面取得了最佳性能。具体来说,作者的方法在Raindrop - A数据集上,比之前的SOTA方法RainDropDiff [57]在PSNR上高出0.67 dB。
声明
本文内容为论文学习收获分享,受限于知识能力,本文对原文的理解可能存在偏差,最终内容以原论文为准。本文信息旨在传播和学术交流,其内容由作者负责,不代表本号观点。文中作品文字、图片等如涉及内容、版权和其他问题,请及时与我们联系,我们将在第一时间回复并处理。

#论 文 推 广#
让你的论文工作被更多人看到
你是否有这样的苦恼:自己辛苦的论文工作,几乎没有任何的引用。为什么会这样?主要是自己的工作没有被更多的人了解。
计算机书童为各位推广自己的论文搭建一个平台,让更多的人了解自己的工作,同时促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。 计算机书童 鼓励高校实验室或个人,在我们的平台上分享自己论文的介绍、解读等。
稿件基本要求:
• 文章确系个人论文的解读,未曾在公众号平台标记原创发表,
• 稿件建议以 markdown 格式撰写,文中配图要求图片清晰,无版权问题
投稿通道:
• 添加小编微信协商投稿事宜,备注:姓名-投稿

△长按添加PaperEveryday小编



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









