







F. 总结
作者的理论分析全面揭示了在四种典型学习场景下,扰动方向和范围对鲁棒模型的泛化性、鲁棒性和公平性有显著影响。主要发现总结如下:
- 与标准对抗训练相比,采用不同扰动范围的对抗训练增强了类别之间的公平性,并在鲁棒性、准确性和公平性之间实现了更好的平衡,如推论1、推论3和推论6所示。
- 与仅使用对抗样本相比,在训练中结合不同扰动范围的对抗样本和反对抗样本在鲁棒性、准确性和公平性之间实现了更优的平衡,如推论2、推论4、推论5和推论7所示。
- 组合策略在实现相同性能时比仅使用对抗样本所需的扰动范围更小,使其成为一种更有效的方法。现有研究忽略了有价值的反对抗样本。因此,作者提出了一个新的优化目标,该目标结合了不同扰动范围的对抗样本和反对抗样本。
IV. 方法
受理论发现的启发,作者首先建立了一个新的目标函数,在训练中为每个样本结合不同扰动范围的对抗样本和反对抗样本。元学习和强化学习通常用于样本加权和扰动的参数选择。相应地,作者分别提出了基于元学习和强化学习的两种方法来解决优化问题。它们的结构如图7所示。
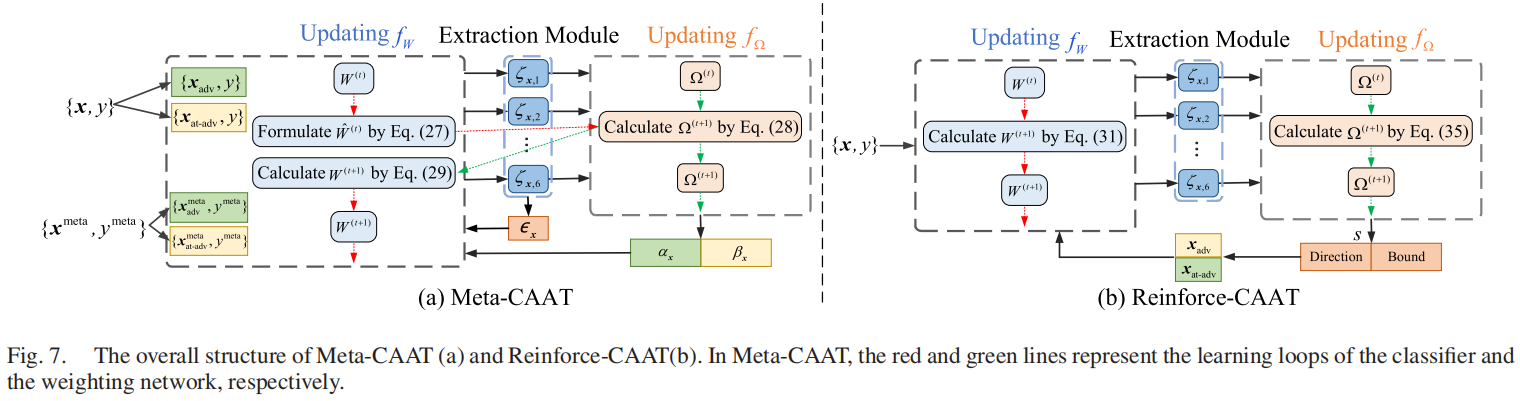
最外层的优化目标是最小化分类器的损失。内层优化目标旨在分别生成对抗样本和反对抗样本,

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











