







1 PSO算法的基本理论

- 将三个散点看做一个粒子

- 惯性分量就是
v
i
−
1
d
v^d_{i-1}
vi−1d
粒子群(PSO)算法是依托群鸟觅食的模型寻找最优解。群体特征基于以下3个简单的行为准则:
- 冲突避免:群体在一定空间移动,个体有自己的移动意志,但不能影响影响其他个体移动,避免碰撞和争执。
- 速度匹配:个体必须配合中心移动速度,不管在方向、距离和速率上都必须相互配合。
- 群体中心:个体将会向群体中心移动,配合群体中心向目标前进。
群鸟觅食其实是一个最佳决策的过程, 与人类决策的过程相似。Boyd和Re chars on探索了人类的决策过程,并提出了个体学习和文化传递的概念。根据他们的研究成果,人们在决策过程中常常会综合两种重要的信息:
- 第一种是自己的经验,即他们根据以前自己的尝试和经历,已经积累了一定的经验,知道怎样的状态会比较好。
- 第二种是他人的经验,即从周围人的行为获取知识,从中知道哪些选择是正面的,哪些选择是消极的。
同理,群鸟在觅食的过程中,每只鸟的初始状态都处于随机位置,且飞翔的方向也是随机的。每只鸟都不知道食物在哪里,但是随着时间的推移,这些初始处于随机位置的鸟类通过群内相互学习、信息共享和个体不断积累字觅食物的经验,自发组织积聚成一个群落,并逐渐朝唯一的目标-—食物前进。每只鸟能够通过一定经验和信息估计目前所处的位置对于能寻找到食物有多大的价值,即多大的适应值;每只鸟能够记住自己所找到的最好位置,称之为局部最优(pbest) 。此外, 还能记住群鸟中所有个体所能找到的最好位置, 称为全局最优(gbest) , 整个鸟群的觅食中心都趋向全局最优移动, 这在生物学上称之为“同步效应”。通过鸟群觅食的位置不断移动,即不断迭代,可以使鸟群朝食物步步进逼。
在群鸟觅食模型中,每个个体都可以被看成一个粒子,则鸟群可以被看成一个粒子群。假设在一个 D D D维的目标搜索空间中,有 m m m个粒子组成一个群体,其中第 i i i个粒子( i = 1 , 2 , ⋯ , m i= 1,2,\cdots,m i=1,2,⋯,m),位置表示为 X i X_i Xi = ( x i 1 , ⋯ , x i D x^1_{i},\cdots,x^D_{i} xi1,⋯,xiD),即第 i i i个粒子在 D D D维搜索空间中的位置为 X i X_i Xi。换言之,每个粒子的位置就是一个潜在解,将 X i X_i Xi代入目标函数就可以计算出其适应值,根据适应值的大小衡量其优劣。粒子个体经历过的最好位置记为 P i = ( p i 1 , ⋯ , p i D ) P_i = (p^1_{i},\cdots,p^D_{i}) Pi=(pi1,⋯,piD),整个群体所有粒子经历过的最好位置记为 P g = ( p g 1 , ⋯ , p g D ) P_g = (p^1_{g},\cdots,p^D_{g}) Pg=(pg1,⋯,pgD)。粒子 i i i的速度记为 V i = ( v i 1 , ⋯ , v i D ) V_i = (v^1_{i},\cdots,v^D_{i}) Vi=(vi1,⋯,viD)。
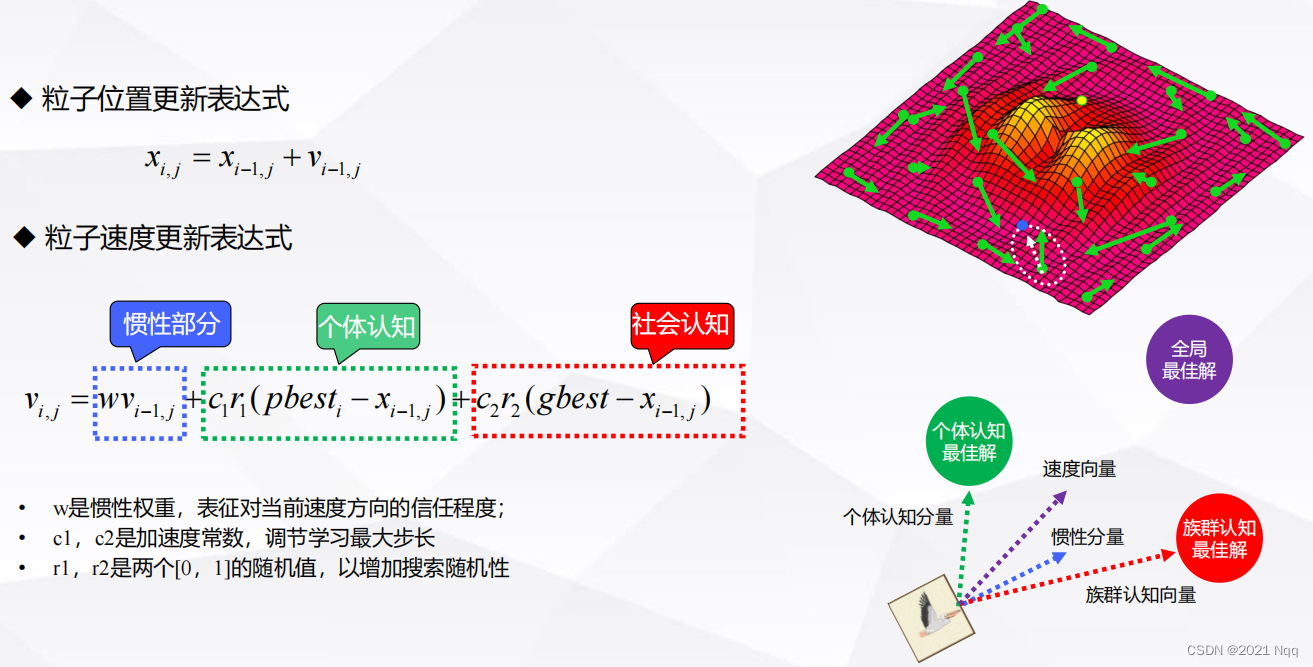
粒子群算法采用下列公式对粒子所在的位置不断更新(单位时间1):
v
i
d
=
w
v
i
−
1
d
+
c
1
r
1
(
p
i
d
−
x
i
d
)
+
c
2
r
2
(
p
g
d
−
x
i
d
)
(1)
{v^d_{i}=wv^d_{i-1}+c_1r_1(p^d_i-x^d_i)+c_2r_2(p_g^d-x_i^d) \tag{1}}
vid=wvi−1d+c1r1(pid−xid)+c2r2(pgd−xid)(1)
x
i
d
=
x
i
d
+
α
v
i
d
(2)
x_i^d=x_i^d+\alpha v_i^d \tag{2}
xid=xid+αvid(2)
- 自我认知: c 1 r 1 ( p i d − x i d ) 自我认知:c_1r_1(p^d_i-x^d_i) 自我认知:c1r1(pid−xid)
- 社会经验: c 2 r 2 ( p g d − x i d ) 社会经验:c_2r_2(p_g^d-x_i^d) 社会经验:c2r2(pgd−xid)
- i = 1 , 2 , ⋯ , m i = 1,2,\cdots,m i=1,2,⋯,m
- d = 1 , 2 , ⋯ , D d = 1,2,\cdots,D d=1,2,⋯,D
- w w w是非负数,称为惯性因子
- 加速度常数 c 1 、 c 2 c_1、c_2 c1、c2是非负数
- r 1 、 r 2 r_1、r_2 r1、r2是[0,1]范围内变换的随机数
- α \alpha α称为约束因子,目的是控制速度的权重
v i d ∈ [ − v m a x d , v m a x d ] v_i^d\in[-v^d_{max},v^d_{max}] vid∈[−vmaxd,vmaxd]范围内,即粒子 i i i的飞行速度 V i V_i Vi被一个最大速度 V m a x = ( v m a x 1 , ⋯ , v m a x D ) V_{max}=(v_{max}^1,\cdots,v_{max}^D) Vmax=(vmax1,⋯,vmaxD)所限制。如果当前时刻粒子在某维的速度 v i d v_i^d vid更新后超过该维的最大飞翔速度 v m a x d v_{max}^d vmaxd则当前时刻该维的速度被限制在 v m a x d v_{max}^d vmaxd。 v m a x v_{max} vmax 为常数,可以根据不同的优化问题设定。
迭代终止条件根据具体问题设定,一般达到预定最大迭代次数或粒子群且前为止搜索到的最优位置满足目标函数的最小允许误差。
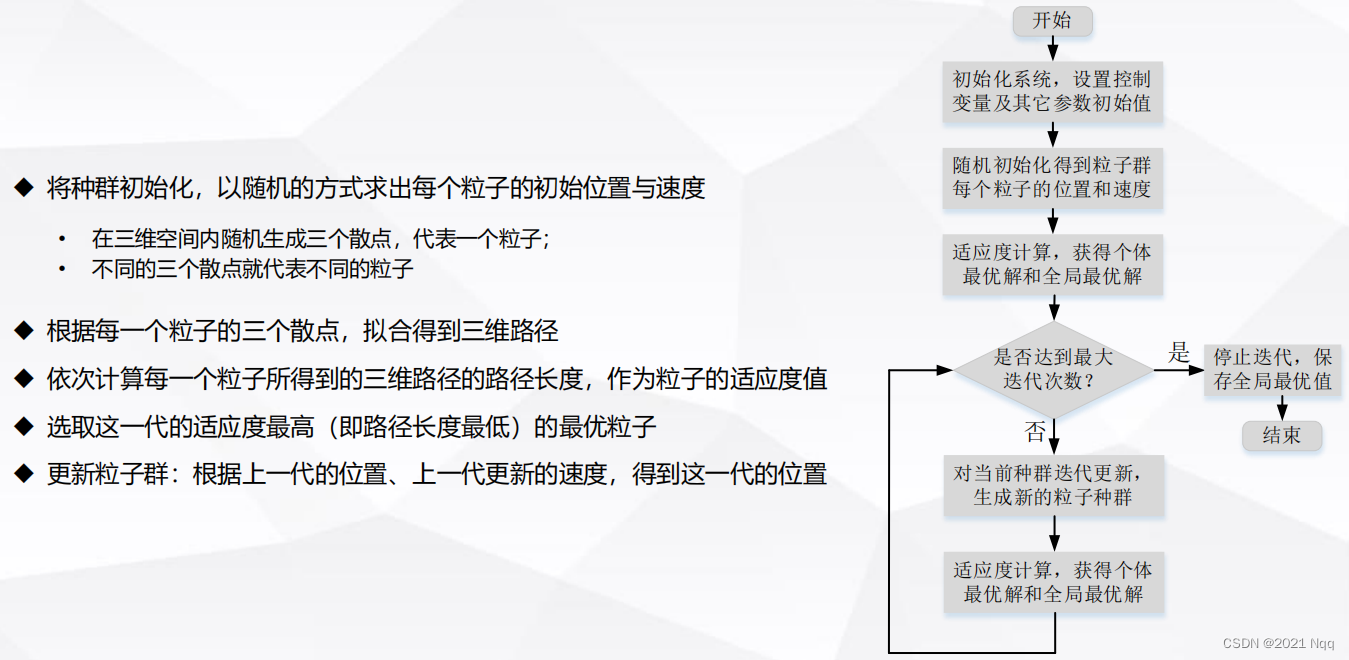
2 PSO算法程序设计流程
- 步骤1:初始化粒子群:速度、位置、惯性因子、加速常数、最大迭代次数、算法终止的最小允许误差。
- 步骤2:评价每个粒子的初始适应值。
- 步骤3:将初始适应值作为当前每个粒子的局部最优值,并将各适应值对应的位置作为每个粒子的局部最优值所在的位置。
- 步骤4:将最佳初始适应值作为当前全局最优值,并将最佳适应值对应的位置作为全局最优值所在的位置。
- 步骤5:依据式(1)更新每个粒子当前的飞翔速度。
- 步骤6:对每个粒子的飞翔速度进行限幅处理,使之不能超过设定的最大飞翔速度。
- 步骤7:依据式(2)更新每个粒子当前所在的位置。
- 步骤8:比较当前每个粒子的适应值是否比历史局部最优值好,如果好,则将当前粒子适应值作为粒子的局部最优值,其对应的位置作为每个粒子的局部最优值所在的位置。
- 步骤9:在当前群中找出全局最优值,并将当前全局最优值对应的位置作为粒子群的全局最优值所在的位置。
- 步骤10:重复步骤5~9,直到满足设定的最小误差或最大迭代次数。
- 步骤11:输出粒子群的全局最优值和其对应的位置以及每个粒子的局部最优值和其对应的位置。
3 MATLAB编程实现
function main()
clc;clear all; close all;
tic; % 程序运行计时
E0 = 0.001; % 允许误差
MaxNum = 100; % 粒子最大迭代次数
narvs = 1; % 目标函数的自变量个数
particlesize = 30; % 粒子群规模
c1 = 2; % 个体经验学习因子
c2 = 2; % 社会经验学习因子
w =0.6; % 惯性因子
vmax = 0.8; % 粒子的最大飞翔速度,rand(m,n)产生m*n的随机矩阵,范围(0,1)
x = -5 + 10 * rand(particlesize, narvs);% 粒子所在的位置 (rand产生的大小为0,1),规模是 粒子群数和参数需求数 设置了x的取值范围[-5,5]
v = 2*rand(particlesize,narvs); % 粒子的飞翔速度,生成每个粒子的飞翔速度,由于是只有一个变量,所以速度是一维的
% 用inline定义适应度函数以便将子函数文件与主程序文件放到一起
% 目标函数是:y = 1+(2.1*(1- x + 2*x.^2).*exp(-x.^2 / 2)) # 与Python不同的是,这里必须要写成.*
% .^之类的,因为定义不同
%inline命令定义适应度函数如下:
fitness = inline('1/(1+(2.1*(1 - x + 2 * x.^2).*exp(-x.^2/2)))','x'); % 这里求倒数,还在分母上加了个1,确保不会出现分母为0的情况,转为求最小值位置
% inline函数定义可以大大降低程序运行速度
for i= 1:particlesize
for j = 1:narvs
f(i) = fitness(x(i,j)); %i是粒子个数,j是维度就是变量个数,x(i,j)就是表示的x的值
end
end
% 完成了对每一个粒子,在各自位置上的适应值
% 粒子开始学习
personalbest_x=x; % 用于存储对于每一个粒子最佳经历点的x值
personalbest_faval=f; % 同时存储对于每一个粒子的最佳经历点的数值,用于更改
[globalbest_faval,i] = min(personalbest_faval); % min函数返回的第一个是最小值,还有一个就是最小值的下标,这里就是告诉了是在哪个粒子上
globalbest_x = personalbest_x(i,:); % 这个是必定是全局最优点的位置
k = 1; % 开始迭代计数
while k <= MaxNum % 当迭代次数达到设定的最大值的时候,就不要再进行迭代了
for i = 1:particlesize % 对于每一个粒子
for j = 1:narvs
f(i) = fitness(x(i,j)); % 得到每个粒子的当前位置 在函数上的适应值
end
if f(i) < personalbest_faval(i) % 如果这个值是小于个人最优解的位置的时候,就更新,我们经过转换,所以只用考虑求最小值的情况
personalbest_faval(i) = f(i); % 将第i个粒子的个人最优解设置为全局最优解
personalbest_x(i,:) = x(i,:); % 同时更改最优解的位置
end
end
[globalbest_faval,i] = min(personalbest_faval);
globalbest_x = personalbest_x(i,:); % 更新全局 全局信息由个体信息描述组成
for i = 1:particlesize %更新粒子群里每个个体的最新位置
v(i,:) = w*v(i,:) + c1*rand*(personalbest_x(i,:) - x(i,:)) + c2*rand*(globalbest_x-x(i,:)); % 由个人和全局的最佳信息数据进行更新移动速度
% 上面中rand会随机生成一个rand(0,1)然后会随机的降低学习因子的比例
for j = 1:narvs % 这个个循环确定了每个自变量上的速度,有没有超过对应的最大值
if v(i,j) > vmax;
v(i,j) = vmax;
else if v(i,j) < -vmax;
v(i,j) = -vmax;
end
end
x(i,:) = x(i,:) + v(i,:); % 通过速度更新位置
end
if abs(globalbest_faval) < E0,break,end
k = k + 1;
end
Value1 = 1/globalbest_faval - 1; % 还记得上面做了一个加1,求倒数的操作么?
Value1 = num2str(Value1);
%strcat指令可以实现字符的组合输出
disp(strcat('the maximum value',' = ', Value1)); % 主要是在这进行了展示
%输出最大值所在的横坐标的位置
Value2 = globalbest_x; % 得到了全局最优解的位置
Value2 = num2str(Value2);
disp(strcat('the maximum x = ', Value2));
% 绘图
x = -5:0.01:5;
y = 2.1*(1 - x + 2 * x.^2).*exp(-x.^2/2);
plot(x,y,'m--','linewidth',3); % m表示的是粉红色,-是表示的是连续的曲线线
hold on;
plot(globalbest_x, 1/globalbest_faval-1,'kp','linewidth',4);
legend('目标函数','搜索到的最大值');
xlabel('x'); % 给x轴贴标签
ylabel('y'); % 给y轴贴标签
grid on;
end
4 算法举例


5 函数
1 unifrnd函数
- sz = [2 3];r2 = unifrnd(0,1,sz) 表示生成2行3列的矩阵,数据范围是0~1
- R = unifrnd(-1,1,2,1),生成一个2行1列的矩阵R,矩阵元素在-1到1之间随机生成
















 2441
2441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











