






最近导师让了解注意力机制,简单做了下整理。
1.sequence to sequence模型:
经典的RNN结构:

输入和输出序列必有相同的时间长度 。
sequence to sequence模型是一类End-to-End的算法框架,也就是从序列到序列的转换模型框架,应用在机器翻译,自动应答等场景。Seq2Seq模型是输出的长度不确定时采用的模型 。
Seq2Seq一般是通过Encoder-Decoder(编码-解码)框架实现,Encoder和Decoder部分可以是任意的文字,语音,图像,视频数据,模型可以采用CNN、RNN、LSTM、GRU、BLSTM等等。
经典的Encoder-Decoder框架:
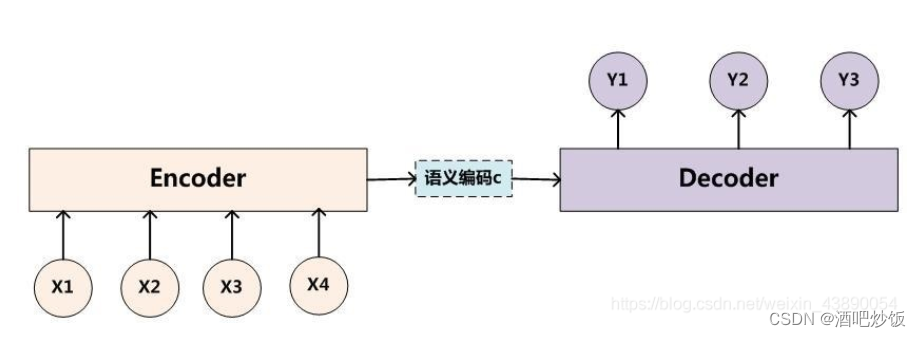
Encoder负责将输入序列压缩成指定长度的向量,这个向量就可以看成是这个序列的语义,这个过程称为编码 。
decoder则负责根据语义向量生成指定的序列,这个过程也称为解码 。
缺点:
seq2seq框架先用Encoder将输入序列编码成一个固定大小的语义向量,这个过程是对信息压缩的过程,不可避免地会损失很多信息,而且Decoder在解码时无法关注到输入序列的更多细节
2.注意力机制
假设现在我们要对一组输入 :
![]()
使用Attention机制计算重要的内容,这里往往需要一个查询向量 q,然后通过一个打分函数计算查询向量 q与每个输入hi 之间的相关性,得出一个分数。接下来使用softmax对这些分数进行归一化,归一化后的结果便是查询向量 q在各个输入hi 上的注意力分布
![]()
其中每一项数值和原始的输入
![]()
一一对应。以 ai 为例,相关计算公式如下:
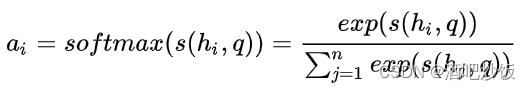
最后根据这些注意力分布可以去有选择性的从输入信息H中提取信息,这里比较常用的信息提取方式,是一种"软性"的信息提取,即根据注意力分布对输入信息进行加权求和,最终的这个结果 context 体现了模型当前应该关注的内容:

2.1打分函数
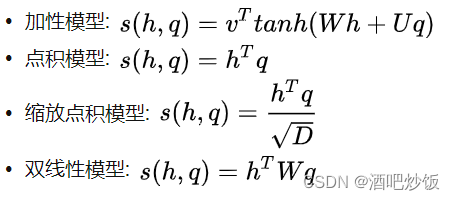
以上公式中的参数 W,U,v 均是可学习的参数矩阵或向量,D 为输入向量的维度
加性模型引入了可学习的参数,将查询向量 q和原始输入向量 H 映射到不同的向量空间后进行计算打分。
相较于加性模型,点积模型具有更好的计算效率。当输入向量的维度比较高的时候,点积模型通常有比较大的方差,从而导致Softmax函数的梯度会比较小。因此缩放点积模型通过除以一个平方根项来平滑分数数值来缓解这个问题。
最后,双线性模型可以重塑为

即分别对查询向量 q和原始输入向量 H 进行线性变换之后,再计算点积。相比点积模型,双线性模型在计算相似度时引入了非对称性。
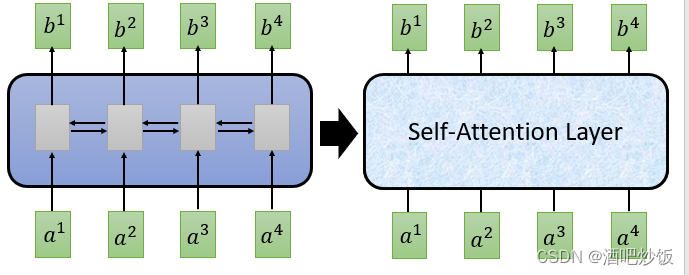
2.2自注意力机制
自注意力机制(self-Attention)中,这里的查询向量也可以使用输入信息进行生成,而不是选择一个上述任务相关的查询向量。相当于模型读到输入信息后,根据输入信息本身决定当前最重要的信息。
自注意力机制往往采用查询-键-值(Query-Key-Value)的模式
Q:匹配其他的k
K:用来计算权值
V:输出

Attention机制中的Q,K,V即是,我们对当前的Query和所有的Key计算相似度,将这个相似度值通过Softmax层进行得到一组权重,根据这组权重与对应Value的乘积求和得到Attention下的Value值

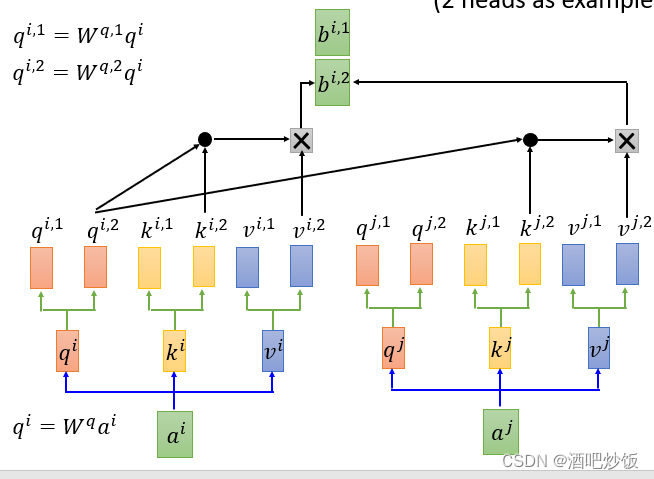
2.3多头注意力机制
多头注意力(Multi-Head Attention)是利用多个查询向量
![]()
并行地从输入信息
![]()
中选取多组信息。在查询过程中,每个查询向量 qi将会关注输入信息的不同部分,即从不同的角度上去分析当前的输入信息。
2.4通道注意力机制
本质是对赋予不同的通道其对应的权重。
SEnet:
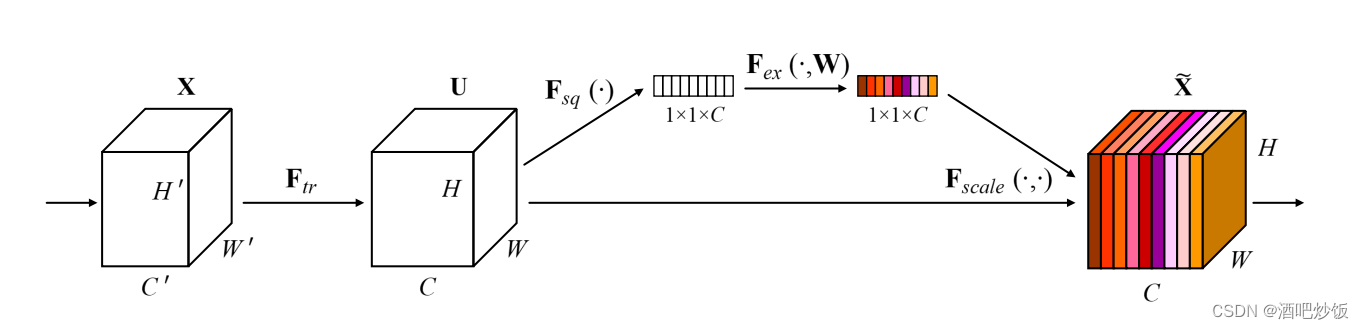
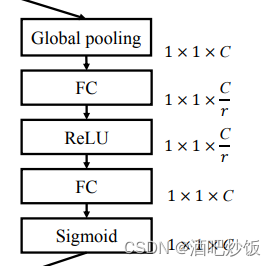
Squeeze:对输入的层进行压缩,综合整个层的信息
Excitation:对压缩后的进行信息整合
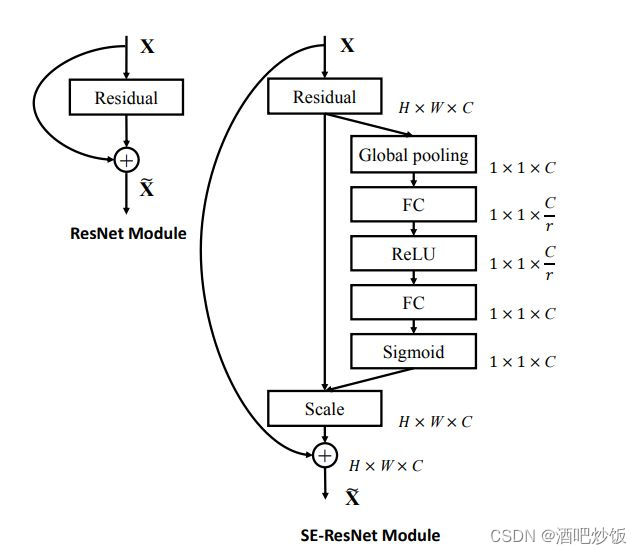
SEnet能方便的嵌入其他网络:
2.5空间注意力机制
空间注意力模型就是寻找网络中最重要的部位进行处理。

2.6空间和通道混合
空间注意力机制_CV中的Attention机制:简单而有效的CBAM模块_weixin_39890708的博客-CSDN博客
Positional Encoding的原理和计算_雨•人的博客-CSDN博客_positionencoding















 421
421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









