







文章目录
这是系列博客,记录了我学习DeepSeek V3/R1时的学习笔记。其他博客:
- DeepSeek 简介
- DeepSeek R1原理
- DeepSeek V3原理
- DeepSeek 优化方式
- 在Deepseek-R1-ZERO出现前,为何无人尝试放弃微调对齐,通过强化学习生成思考链推理模型?
- MoE硬件部署
DeepSeek 简介
参考资料:这或许是全网最全的 DeepSeek 使用指南,95% 的人都不知道的使用技巧(建议收藏) - 狂师 - 博客园

关于DeepSeek公司介绍
DeepSeek(深度求索),是一家在2023年7月17日成立的公司深度求索所开发的大模型名称。公司坐落于杭州,是幻方量化旗下的子公司,全称是杭州深度求索人工智能基础技术研究有限公司。
DeepSeek开发团队是由一群年轻且富有才华的高校毕业生组成,团队创始人梁文锋,是量化投资领域的资深专家,拥有丰富的量化投资经验和AI技术背景。其它主要成员大多数来自清华大学、北京大学和浙江大学等国内顶尖高校。
为什么DeepSeek这么火爆?
DeepSeek火爆出圈的最大原因是,它以极低的成本,做出了能比肩海外巨头的AI大模型。
DeepSeek 成立时间虽才一年多,但已经在中美APP store登上免费应用榜首,且应用成果和行业影响显著:
- 2024年5月,发布DeepSeek-V2,正式打响中国大模型价格战,当时新发布的 DeepSeek-V2 的API价格只有 GPT-4o 的 2.7%,随后一周时间,国产厂商全部跟进纷纷降价。
- 2024年12月,DeepSeek推出的DeepSeek-V3,在全球AI领域掀起了巨大的波澜,它以极低的训练成本,据说训练成本不到600W美元,实现了与GPT-4o和Claude Sonnet 3.5等顶尖模型相媲美的性能,震惊了业界。自此,东方的神秘力量彻底坐实。
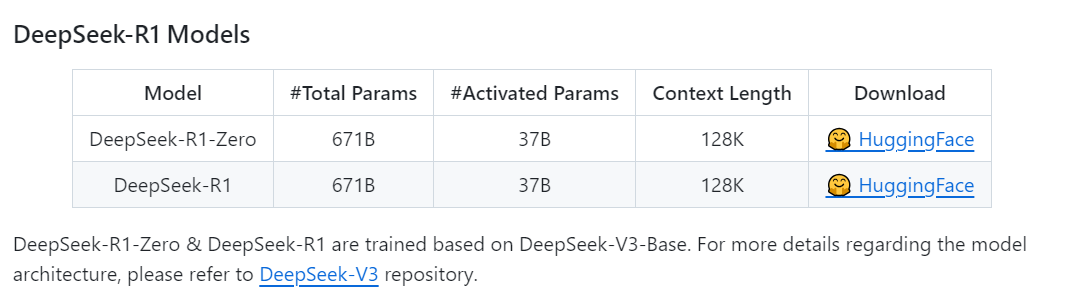
- 时隔不到一个月,2025年1月,DeepSeek又一次震动全球AI圈。和上次不同的是,今年1月份推出的新模型DeepSeek-R1(671B 参数 MoE,激活 37B 参数,128K 上下文的深度思考模型)不仅成本低,更是在技术上有了大幅提升。这款新模型延续了其高性价比的优势,仅用十分之一的成本就达到了GPT-o1级别的表现,API定价仅是国内外其他头部AI厂商几十分之一。DeepSeek R1出现如同一匹黑马,以惊人的姿态闯入AI圈。它不仅让英伟达市值一夜蒸发超1万亿美金,更是让各路AI大佬瞬间破防。
简单小结一下,OpenAI的GPT-4o模型虽强大,但光训练成本可能就已经达到上亿美元。而DeepSeek仅用了几百万美金,做出了性能接近的模型。再加上它对中文理解极佳,回答更自然,不像其他AI过于“模板化”,这也是它受欢迎的原因之一。
我也让DeepSeek列个GPT-4o和o1的对比表格,大家应该也能一目了然。
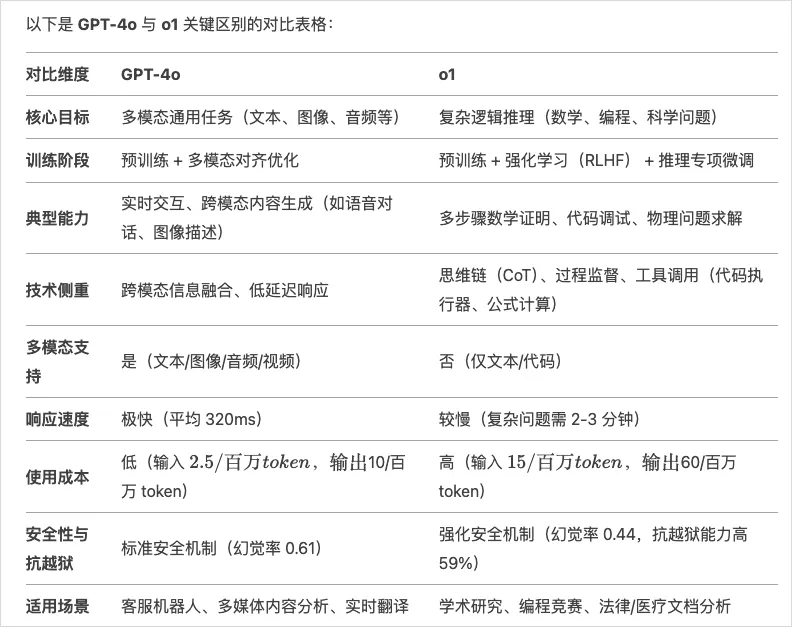
而R1,可以直接类比o1,两者在跑分上,几乎相同。
DeepSeek开源地址

DeepSeek 相关模型已经开源,以下是不同模型的开源地址:
1、DeepSeek Coder,它是代码大模型,仓库地址为:
https://github.com/DeepSeek-AI/DeepSeek-Coder
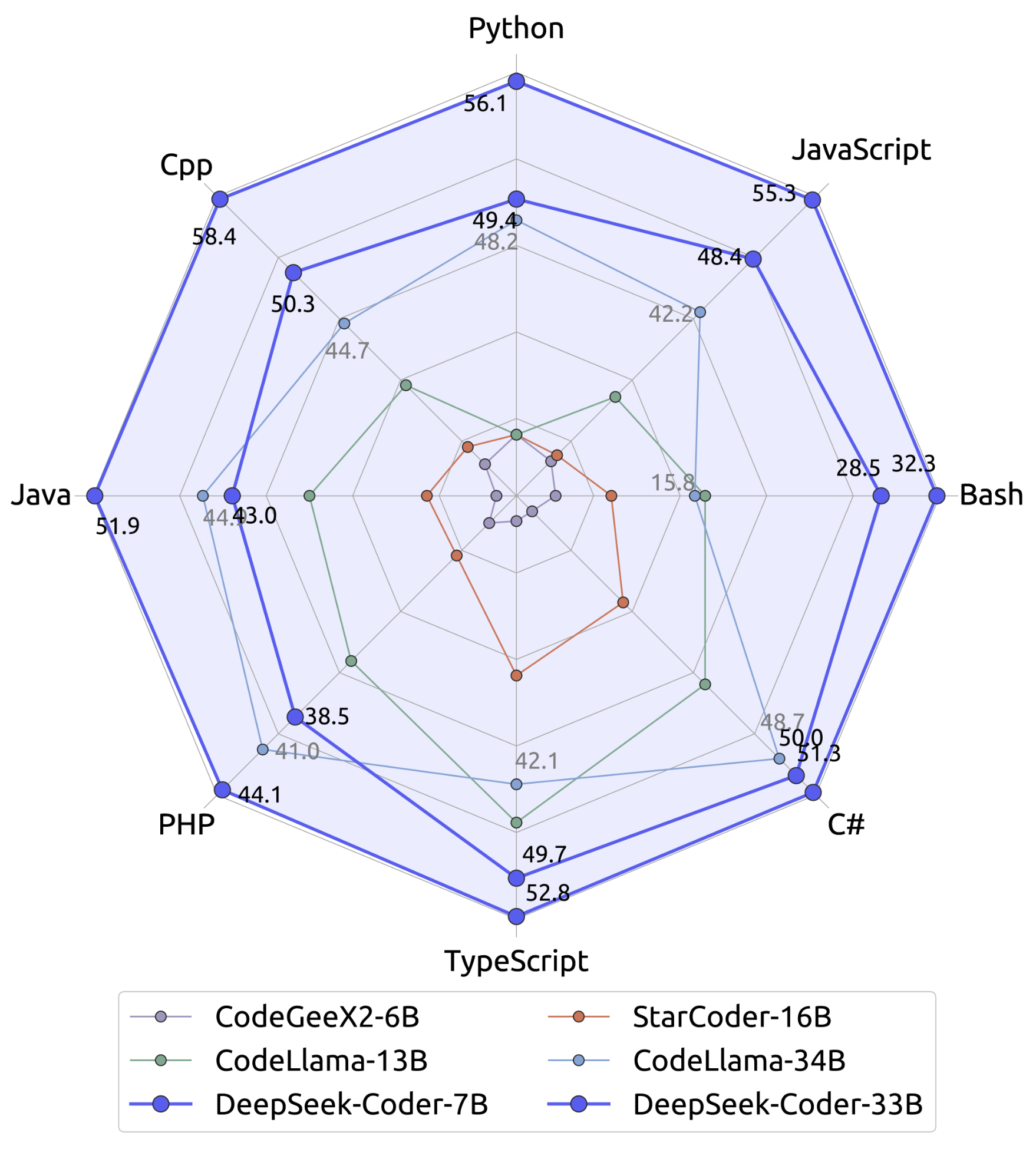
在这个仓库中,你可以找到模型的详细介绍、使用文档、代码示例,还能下载对应的模型权重来开展开发工作。
2、DeepSeek LLM, 它是通用大语言模型,仓库地址为:
https://github.com/DeepSeek-AI/DeepSeek-LLM
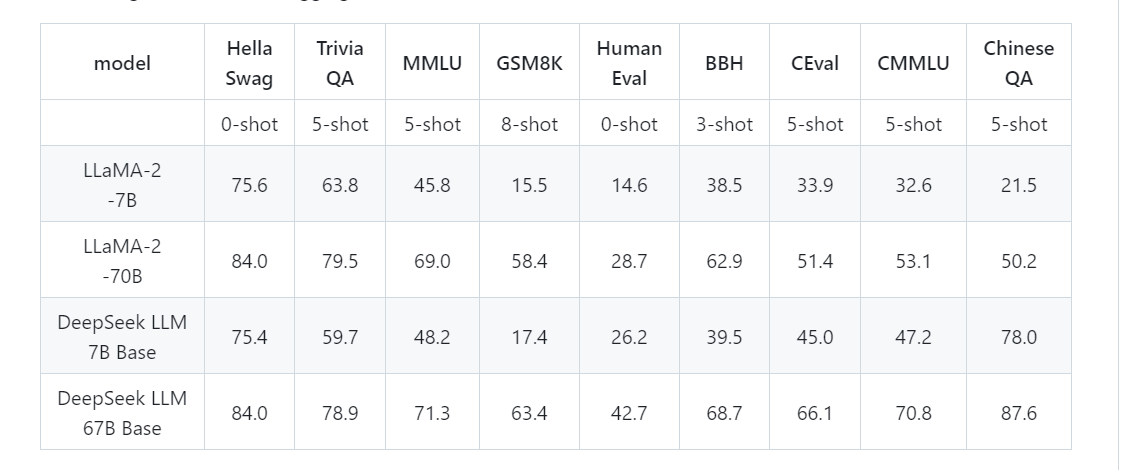
这里有关于该模型的架构、训练方法等方面的介绍,同时也提供了模型使用的指引。
3、DeepSeek-R1,仓库地址:
https://github.com/deepseek-ai/DeepSeek-R1
论文链接:https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
开源模型
DeepSeek-V3
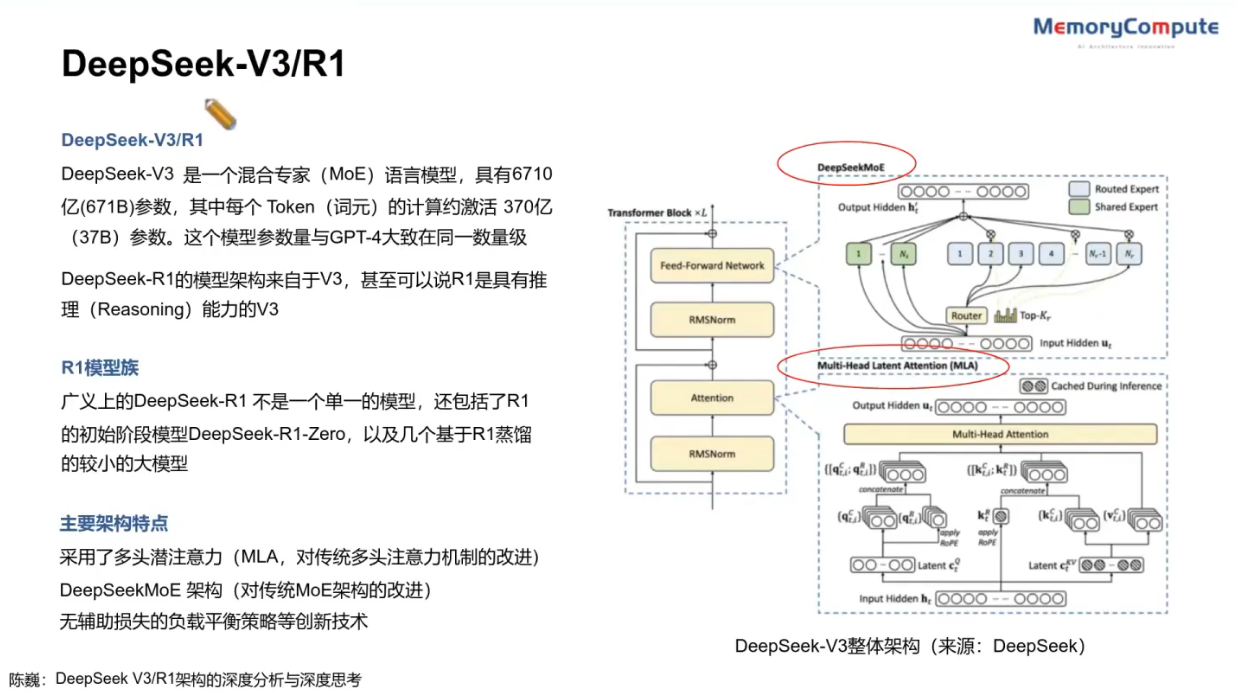
- 模型架构与训练:拥有6710亿参数的混合专家(MoE)模型,每次推理激活370亿参数,采用多头潜在注意力(MLA)机制和DeepSeekMoE架构。在14.8万亿tokens上完成训练,总训练成本约557.6万美元,远低于同级别模型。
- 性能表现:在Arena-Hard和AlpacaEval 2.0测试中,准确率分别达85.5%和70.0%。推理速度和质量超越OpenAI的GPT-4o,接近Anthropic的Claude 3.5 Sonnet ,上下文窗口为13万个Token,在大规模文本处理和长上下文任务表现优异。
- 适用场景:适合需要高效推理和大规模文本处理的场景。
DeepSeek-R1
- 模型版本与训练:基于V3开发的第一代推理模型,包含DeepSeek-R1-Zero和DeepSeek-R1两个版本。R1-Zero通过大规模强化学习(RL)训练,无需监督微调(SFT);R1引入冷启动数据和多阶段训练,解决R1-Zero可读性差和语言混合等问题。
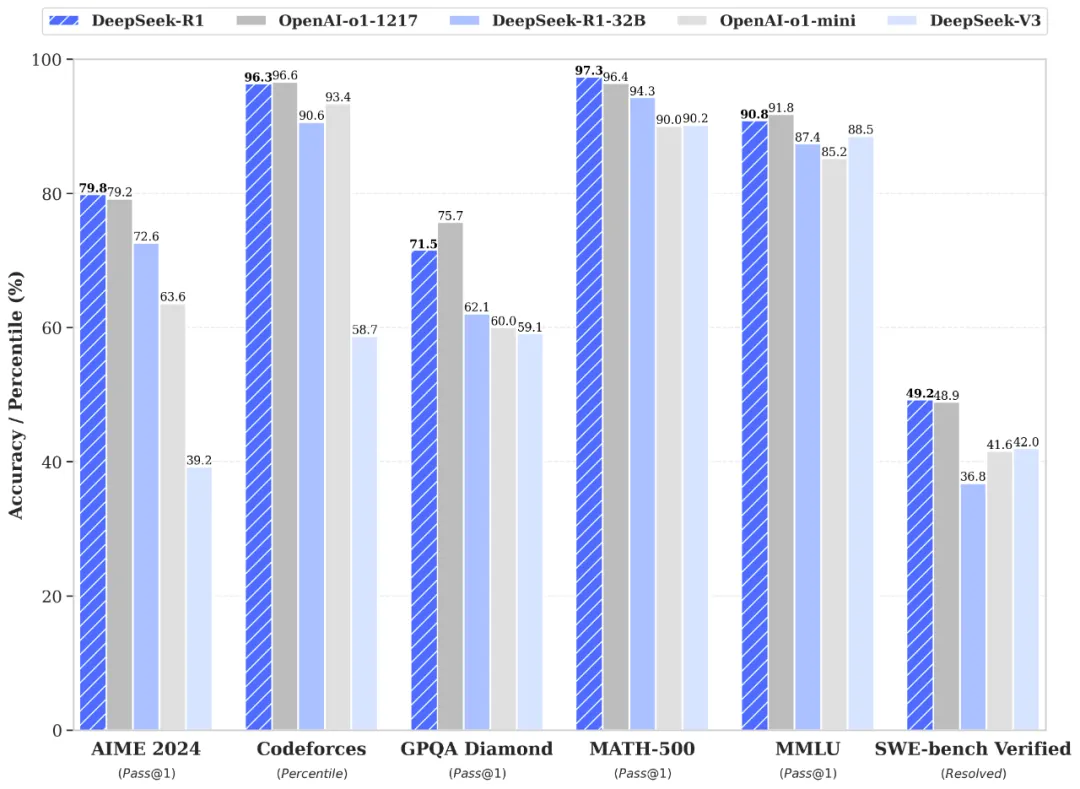
- 性能表现:在数学、编程和自然语言推理等任务表现出色,如在AIME 2024基准测试中超越OpenAI O1。在创意写作方面优于OpenAI的o1系列,推理能力与o1系列相当,但某些任务细节处理更优。
- 适用场景:适合深度逻辑分析任务,如数学问题求解、编程辅助、复杂推理等。
- 与DeepSeek-V3对比
| 特性 | DeepSeek-V3 | DeepSeek-R1 |
|---|---|---|
| 架构 | 混合专家(MoE)模型 | 基于V3的强化学习模型 |
| 参数量 | 6710亿总参数,每次激活370亿 | 同V3,但通过强化学习优化推理能力 |
| 训练策略 | 标准预训练+监督微调+强化学习 | 最小化监督微调,强化学习为主 |
| 推理能力 | 性能良好,但未针对推理优化 | 强化学习显著提升推理能力 |
| 训练复杂度 | 传统大规模预训练 | 强化学习驱动的自适应改进 |
| 流畅性与连贯性 | 监督微调后表现更好 | 初始较弱,强化学习后提升 |
| 长文本处理 | 监督微调中加强 | 通过强化学习自然涌现 |
| 性能对比 | 在数学推理、编程等任务中表现稍逊 | 在数学推理、编程等任务中表现更优 |
| 成本 | 输入输出token成本约为R1的1/6.5 | 成本较高,但推理能力更强 |
DeepSeek-R1-Distill
- 模型特性与训练:基于R1模型通过蒸馏技术生成的更小、更高效的模型。
- 性能表现:在多个基准测试中表现出色,如DeepSeek-R1-Distill-Qwen-32B在AIME 2024上Pass@1达72.6%,显著优于其他开源模型。计算成本低于大规模RL训练的模型(如DeepSeek-R1-Zero-Qwen-32B) ,在推理基准测试中表现优于OpenAI的o1-mini。
DeepSeek推理模型介绍
参考链接:GitHub - deepseek-ai/DeepSeek-R1
简介
包括第一代推理模型 DeepSeek-R1-Zero 和 DeepSeek-R1。DeepSeek-R1-Zero和DeepSeek-R1基于DeepSeek-V3-Base进行训练。
DeepSeek-R1-Zero 通过大规模强化学习(RL,reinforcement learning)训练而成,在没有监督微调(SFT,supervised fine-tuning)作为初步步骤的情况下,在推理方面表现出色,并且通过强化学习自然地出现了许多强大而有趣的推理行为。然而,它也面临着无尽重复、可读性差和语言混合等问题。
为了解决这些问题并进一步提高推理性能,引入了 DeepSeek-R1,它在强化学习之前结合了冷启动数据。DeepSeek-R1 在数学、代码和推理任务方面的性能与 OpenAI-o1 相当。
为了支持研究社区,作者开源了 DeepSeek-R1-Zero、DeepSeek-R1 以及基于 Llama 和 Qwen 从 DeepSeek-R1 提炼出的六个密集模型。DeepSeek-R1-Distill-Qwen-32B 在各种基准测试中优于 OpenAI-o1-mini,为密集模型实现了新的最先进结果。
后训练
“Post-Training: Large-Scale Reinforcement Learning on the Base Model” 指的是在基础模型上进行大规模强化学习的后续训练阶段。
首先,不依赖有监督的微调(SFT)作为初步步骤,直接将强化学习(RL)应用于基础模型。这种方法使模型能够探索思维链(CoT,chain-of-thought)以解决复杂问题,从而开发出 DeepSeek-R1-Zero。DeepSeek-R1-Zero 展示了自我验证、反思和生成长思维链等能力,这对研究社区来说是一个重要的里程碑。值得注意的是,这是第一个公开的研究,验证了大型语言模型(LLMs)的推理能力可以纯粹通过 RL 来激励,而不需要 SFT。
其次,介绍了开发 DeepSeek-R1 的流程。该流程包括两个 RL 阶段,旨在发现改进的推理模式并与人类偏好保持一致,以及两个 SFT 阶段,它们作为模型推理和非推理能力的种子。
知识蒸馏
首先可以将大型模型的推理模式提炼到小型模型中,并且这样做会比在小型模型上通过强化学习发现的推理模式有更好的性能表现。
开源的 DeepSeek-R1 及其 API 将有助于研究社区在未来提炼出更好的小型模型。
使用 DeepSeek-R1 生成的推理数据,对研究社区中广泛使用的几个密集模型进行了微调。评估结果表明,经过提炼的小型密集模型在基准测试中表现非常出色。
向社区开源了基于 Qwen2.5 和 Llama3 系列的 1.5B、7B、8B、14B、32B 和 70B 检查点。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









