







 本文详细介绍了机器学习中的建模技术,包括描述性建模(如聚类、降维和异常分析)和预测性建模(如分类、回归和评分),重点探讨了概率方法(如贝叶斯分类器和神经网络)和代数方法(如KNN和决策树)。文章还深入剖析了线性可分概念以及线性判别函数在多类问题中的应用。
本文详细介绍了机器学习中的建模技术,包括描述性建模(如聚类、降维和异常分析)和预测性建模(如分类、回归和评分),重点探讨了概率方法(如贝叶斯分类器和神经网络)和代数方法(如KNN和决策树)。文章还深入剖析了线性可分概念以及线性判别函数在多类问题中的应用。
1 机器学习中的建模
1.1 描述性建模
以方便的形式给出数据的主要特征,实质上是对数据的概括,以便在大量的或有噪声的数据中仍能观察到重要特征。重在认识数据的主要概貌,理解数据的重要特征。
- Task:聚类分析,数据降维,流形学习,密度估计,异常分析,可视化
1.2 预测性建模
以函数的形式给出感兴趣量(预测量)与可观测量之间的数量关系,实质上是根据观测到的对象特征来预测对象的其他特征。重在把握协变关系,据此进行预测。
- Task:分类(类别预测),回归(数值预测),评分(排名预测)
1.2.1 预测性建模方法
概率方法:生成式建模方法,借助训练数据对同类数据的生成机制(概率分布)进行估计,基于概率关系对变量取值进行概率预测。把模式视为随机变量的抽样,利用统计决策理论(贝叶斯统计)成熟的判决准则与方法,对模式样本进行分类
如:贝叶斯分类器、贝叶斯网络(概率图模型)、高斯混合模型、隐马尔可夫模型、受限玻尔兹曼机、生成对抗网络,变分自动编码器
代数方法:判别式建模方法,借助训练数据对观测量和预测量的函数关系进行直接建模,基于函数关系对变量取值进行数值预测。利用向量空间的直观概念,使用代数方程方法,对模式进行分类
如:KNN,感知机,判别分析,决策树,随机森林,支持向量机、逻辑回归,神经网络
1.3 判别函数
1.3.1 线性可分概念与线性分类算法
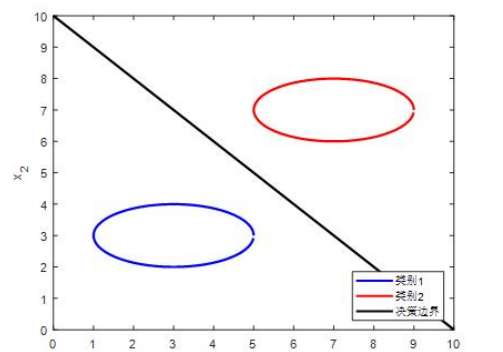
一个分类问题是否属于线性可分,取决于是否有可能找到一个点、直线、平面或超平面来分离开两个相邻的类别。如果每个类别样本的分布范围本身是全连通的单一凸集,且互不重叠,则这两个类别一定是线性可分的,如图所示。线性分类算法主要有线性判别函数、Fisher判别分析、单层感知器、逻辑回归等
1.3.2 判别函数的定义
直接用来对模式进行分类的决策函数,若分属于ω1,ω2两类的n维模式在空间中的分布区域,可以用一代数方程d(X) =0决定的超平面作为分隔面,两类样本分布在分隔面的两侧,那么就称d(X)为判别函数(discriminant function)或称决策函数(decisionfunction)。代数方程d(X) =0表示的是n维空间的(n-1)维判决面 {或超平面(hyperplane)或超曲面(hypersurface) ,视d(x)形式而定}。
Note:这里的模式或许可以直接理解成数学里的自变量。
为了清晰地了解d(x)的含义,应该画出判别函数值d(x)这一轴,在没有画出的时候,就在自变量(模式)空间中画出d(x)取正负值的区域——这就是所谓判别面的正侧、负侧。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 9132
9132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











