







我是一名在校大学生,这是第一次写博客,希望记录一下自己的学习过程,然后如果哪里做的不好打扰或者影响到您,可以联系我修改、删除。
哇,……弄了好久才明白咋回事。我想开头空两格写,然后发现空两格之后他就不会自动换行了,找了半天才发现原来不空两格就好了…………贼丢人(还是得多读书啊……)。言归正传,写这个博客,我主要是想记录一下自己的学习过程,同时如果有哪位兄弟姐妹看到了我踩的坑可以吸取教训的话,我也会非常的欣慰!!
一.主要目的:
最近在学习python网络爬虫,然后学到了selenium模块,然后就想主要用这个模块来爬去一下智联招聘网站。
二.前期准备:
这里我用的是windows7系统,使用的是anaconda中的环境(我平时比较懒,然后感觉anaconda包比较多,而且可视化界面也是非常舒服)
我希望模拟的是火狐浏览器,然后需要下载一个驱动:GeckoDriver(下载地址:https://github.com/mozilla/geckodriver/releases),然后这里的话如果希望用着方便可以直接把下载好的驱动直接放到Python的Scripts目录下,另外还可以有另一种方法,也是我这里用到的,定义一个driver_path变量。这里我是看的崔庆才大神所著的《Python3网络开发实战教程》。程序中我用到的模块:
from selenium import webdriver
from lxml import etree
import os
import time
from selenium .webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
import re
import csv
driver_path = r'E:\python_tools\geckodriver-v0.26.0-win64\geckodriver.exe'
三.思路分析:
1.在看了网站主页之后我决定从城市开始爬,从主页获取每个城市的页面链接,这个不难,直接使用selenium中的source_page获取(这里获取的直接是右键检查元素中的内容,不需要再打开源代码找了),因为我对xpath比较熟悉,所以习惯用xpath提取,另外这样速度好像也会更快些。我这里是定义了一个类,然后类里面有好多函数。
self.url = 'https://www.zhaopin.com/'
self.wait = WebDriverWait(self.browser, 5)
def run(self):
self.browser.get(self.url)
time.sleep(65)#让我登陆一下
self.browser.close()#因为登陆以后会有新的页面跳出
self.browser.switch_to.window(self.browser.window_handles[0])
source = self.browser.page_source
#因为网速原因有时候弹出框出的慢
# 因为会有弹出框
# know_btn = self.wait.until(EC.element_to_be_clickable((By.XPATH, '/html/body/div[5]/div/div/button'))) # 按钮必须这样真TMD坑
# know_btn.click()
time.sleep(1)#感觉可删,不过影响不大
htmlElement = etree.HTML(source)
# 获取后面每个城市的网页链接
city_links_all = htmlElement.xpath('//div[@id="footer"]//li//a/@href')
# 获取城市名
city_names_all = htmlElement.xpath('//div[@id="footer"]//li//a/text()')
2.进到某个诚实页面之后会出现一些职位分类,按照大方向分为:
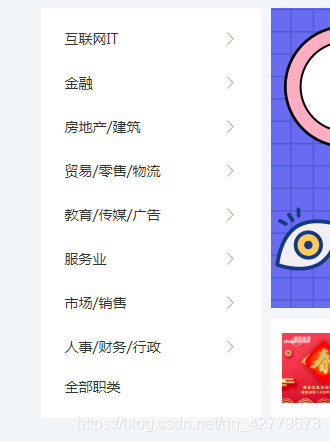
到这里之后可以发现内部这些大方向内部还有具体的小方向:
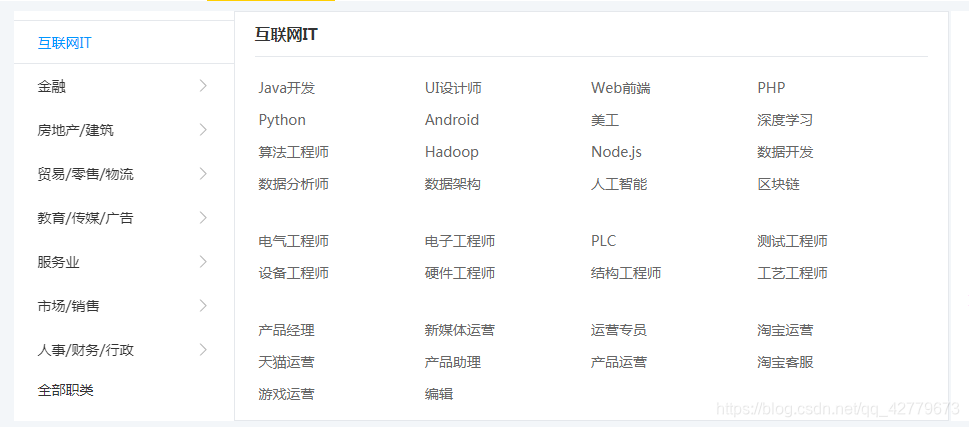 所以我希望可以为每个城市建立一个文件夹,在城市文件夹内部,按照每个城市的招聘信息中每个大方向分别创建自己的文件夹,最后在大方向文件夹内部每一个小方向是一个CSV文件。因为我只需要每个省会城市的信息(主要是都爬时间太长……),所以多加了一步。
所以我希望可以为每个城市建立一个文件夹,在城市文件夹内部,按照每个城市的招聘信息中每个大方向分别创建自己的文件夹,最后在大方向文件夹内部每一个小方向是一个CSV文件。因为我只需要每个省会城市的信息(主要是都爬时间太长……),所以多加了一步。
对了上面这个图里面小方向好像是在JS中,然后他也不是按钮也没法用click()点击,这点我很困惑,最终也没解决!!
我用的方法是,这一页上面有一个输入框可以查询具体方向的招聘信息,我通过控制浏览器然后模拟输入,点击按钮进行查询的方式进入到招聘信息页面
city_links = []
city_names = ['北京', '上海', '天津', '重庆', '哈尔滨', '银川', '郑州', '济南', '太原', '合肥', '长春', '沈阳', '呼和浩特', '石家庄', '乌鲁木齐',
'兰州', '西宁', '西安', '张家界', '武汉', '南京', '成都', '贵阳', '昆明', '南宁', '西藏', '杭州', '南昌', '广州', '福州', '海口']
for i in range(len(city_names)):
city_links.append("")
print(len(city_links))
for i in range(len(city_names_all)):
for index, city_name in enumerate(city_names):
if city_names_all[i] == city_name:
city_links[index] = city_links_all[i]
print(city_names,city_links)
print("一共要爬"+str(len(city_names))+"个城市")
for i in range(len(city_names)):
print('正在获取'+ city_names[i]+'的信息,该城市链接为'+city_links[i])
time.sleep(1)#爬每一个城市前停一下
city_directory = city_names[i]#城市名即为目录名
if not os.path.exists(city_directory):
os.mkdir(city_directory)#创建每个城市的目录
try:
self.request_city(city_links[i],city_names[i])
print(city_names[i] + '所有岗位已经爬取完毕')
print('=' * 40)
except Exception as e:
print(e)
print("城市页面加载出问题")
# time.sleep(1)#认为可删
print('='*40)
self.browser.close()
self.browser.switch_to.window(self.browser.window_handles[0]) # 这里爬完一整个城市,然后要关掉窗口
def request_city(self,url,city):
first_second_positions = {}
url = "https:"+url
self.browser.execute_script("window.open()")
self.browser.switch_to.window(self.browser.window_handles[1])#把当前控制页面切换到新一页
try:
self.browser.get(url)
city_source = self.browser.page_source
htmlElement = etree.HTML(city_source)
category_first_positions = htmlElement.xpath('//*[@id="root"]/div[3]/div/div[1]/ol/li/div[1]/text()')#大方向,比如IT,金融
for index,category_first_position in enumerate(category_first_positions):
category_second_positions = htmlElement.xpath('//*[@id="root"]/div[3]/div/div[1]/ol/li['+str(index+1)+']/div[2]/div/div/a//text()')
###################################
###还是有问题
#//*[@id="root"]/div[3]/div[2]/div[1]/ol/li[1]/div[2]/div/div//text()
first_second_positions[category_first_position] = category_second_positions
print(first_second_positions)
# category_second_positions = htmlElement.xpath('//*[@id="root"]/div[3]/div/div[1]/ol/li[1]/div[2]/div/div[2]//text()')#小方向,比如JAVA,PYTHON
# print(category_first_positions)
# print(category_second_positions)
# # print(category_first_positions,category_second_positions)
# time.sleep(1)
for key,value in first_second_positions.items():
if not os.path.exists(city+'/'+key):
key = re.sub(r'/', '', key)
if not os.path.exists(city+'/'+key):
os.mkdir(city+'/'+key)
for i in value:#这里的i就是每一个小方向,例如互联网IT下的python
road = city+'/'+key+'/'+i
if not os.path.exists(road+".csv"):
# second_url = 'https://sou.zhaopin.com/?jl=601&kw='+i+'&kt=3'
print('现在正在爬取'+city+"市"+key+"行业,"+i+'岗位')
input = self.browser.find_element_by_xpath(
"/html/body/div[1]/div[1]/div/div[2]/div/div/div[2]/div/div/input")
js = 'document.querySelector(".zp-search__input").value="";'
self.browser.execute_script(js)#NB
#input.clear() ########忘了后果很严重,TMD这里这个失效了,上网找了个大神的方法
input.send_keys(i)
button = self.browser.find_element_by_xpath('//*[@id="root"]/div[1]/div/div[2]/div/div/div[2]/div/div/a')
button.click()
try:
self.parse_second_position(road)
print(city + "市" + key + "行业," + i + '岗位,爬取完成')
except Exception as e:
print(e)
print(city + "市" + key + "行业," + i + "岗位页面加载出问题,城市页面没问题")
print('='*30)
# time.sleep(1)去掉或许可以提速
self.browser.close()
self.browser.switch_to.window(self.browser.window_handles[1])
#time.sleep(1)
# time.sleep(1)
#self.browser.close()#某市某行业下的小方向爬完之后,关闭网页
# print(city+"市"+category_first_position+"行业,"+category_second_position+'岗位已爬取成功')
# self.browser.close()#关闭该城市爬完的岗位
# self.browser.switch_to.window(self.browser.window_handles[0])
# time.sleep(1)继续提速
except Exception as e:
print(city+"城市页面出问题")
#查看该城市所有的招聘信息
# bt = self.browser.find_element_by_class_name('jobs-hot__button--more')
# bt.click()
# time.sleep(3)
# self.browser.close()
# self.browser.switch_to.window(self.browser.window_handles[2])
# print(self.browser.current_url)
# time.sleep(10)
# self.browser.quit()
这个代码是我改了好多遍的,但是为了提醒自己,我修改的时候只是给我觉得不合适的代码变成了注释。然后一开始没有加异常处理(主要原因是自己不太会,但是这个程序总是被错误中断,我就加了个异常处理)这里创建文件夹之前先判断是否存在,也是为了一次没爬完下次接着爬…………
3.然后就到了某个城市某个大方向下某个小方向中的每一条具体招聘信息的页面,我用的方法是,这一页上面有一个输入框可以查询具体方向的招聘信息,我通过控制浏览器然后模拟输入,点击按钮进行查询的方式进入到招聘信息页面

def parse_second_position(self,road):
try:
#i = 1#记录当前在爬的页数
second_position_informations = []
#self.browser.execute_script("window.open()")
#self.browser.switch_to.window(self.browser.window_handles[2])
self.browser.switch_to.window(self.browser.window_handles[2])
# self.browser.get(url)
# print(self.browser.current_url)
second_position_page_source = self.browser.page_source
htmlElement = etree.HTML(second_position_page_source)
element_judges = self.wait.until(EC.presence_of_all_elements_located((By.XPATH, '//*[@id="listItemPile"]/div[3]/div/div')))#这里是判断某地区的某行业中的某个小方向是否有招聘信息
# print(element_judges)
# print(element_judges[0].text)
judge = re.sub(r"[\s]","",element_judges[0].text)#这里是要去掉找不到那个中间的换行
# print(judge)#判断是否有信息
if judge != "很抱歉,您搜索的职位找不到!换个条件试试吧":
#print("现在在爬"+road+"第"+str(i)+"页")
element_as = self.wait.until(EC.presence_of_all_elements_located(
(By.XPATH, '//*[@id="listContent"]/div/div/a'))) # 这里得到的是元素a,列表。这里是为了防止网速慢,未加载出来
###########!!!!!!!这里面收到的错误类型不知道算什么.用TimeError,收不到这个错误类型 #
for element_a in element_as:
# print(element_a.get_attribute('href'))#具体职位的详情页面URL
link = element_a.get_attribute('href')
try:
second_position_informations.append(self.parse_detail_position(link))
print("收到请求数据")
except Exception as e:
print(e, "详情函数出问题")
print()
print()
self.browser.close()
self.browser.switch_to.window(self.browser.window_handles[2])
####这个翻页我整不成,不弄了,单独调试没有一点问题
# next_btn = self.wait.until(EC.presence_of_all_elements_located(
# (By.XPATH, '//*[@id="pagination_content"]/div/button[2]')))
# # print()
# #这里是判断是否有翻页
# print("判断是否有下一页")
# print(type(next_btn))
# if len(htmlElement.xpath('//*[@id="pagination_content"]/div/button[2]/@disabled'))!=0:
# break
# else:
# next_btn[0].click()
# i = i+1
# print("已点击翻页按钮")
#个人一些见解:如果try内部有函数,函数内发生异常(即使内部函数中也有try except依旧会出现触发外部的try except)如果是try except嵌套try except那么如果内层出现的错误符合内层的except则不会触发外部的except
#此处应该拉到前面,这样如果IF成立,也会建立文件
''' !!!!!!!!!!!!!!!!!!!!!!!!!!!此处有修改 '''
with open(road + '.csv', 'a', encoding='utf-8', errors='ignore') as fp:
print("开始写入数据")
fieldnames = ['职位名称', '工资', '城市', '工作经验', '教育背景', '人数需求', '职位亮点', '职位描述', '工作地点']
writer = csv.DictWriter(fp, lineterminator='\n', fieldnames=fieldnames)
writer.writeheader()
for row in second_position_informations:
try:
writer.writerow(row)
except UnicodeEncodeError as e:
print(e)
print("数据写入完成")
print()
except Exception as e:
print("大概率是second职位页面未加载出来页面")
print(e)
这个页面上有的小方向中的招聘信息是有分页的,然后我看了一下这个‘下一页’按钮如果有disabled属性则证明已经到了最后一页,我想用这个进行判断,单独在一个文件中试我确实成功了,但是整个代码一运行,这里总是出问题,最后我就放弃了…………如果有大神可以指导的话真的很感谢。然后我这个写入CSV文件的时候我也是采取了只要爬到数据就写入,也就是说如果我这个程序爬一个小方向中的具体招聘信息时出现异常,那么下一次我再重新爬的时候,他会检测到已经有该CSV文件了,就不会再解决有出现异常的那个数据(因为能力有限,确实只能做到这了)
4.进入到招聘信息的详情页面,我把这些数据存成字典形式
def parse_detail_position(self,url):
#print(url)
print('爬取中…………')
position_information = {}
self.browser.execute_script("window.open()")
self.browser.switch_to.window(self.browser.window_handles[3])
try:
self.browser.get(url)#因为这里有可能请求不到页面
# source = self.browser.page_source
# htmlElement = etree.HTML(source)
# print(htmlElement)
print("等待加载")
self.wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="root"]/div[3]/div/div/h3')))
# page_htmlElement = page_htmlElement.xpath('//*[@id="root"]')[0]#因为返回的是列表!!!!!!
# print(len(page_htmlElement))
print("加载完毕")
source = self.browser.page_source
htmlElement = etree.HTML(source)
if len(htmlElement.xpath('//*[@id="root"]/div[3]/div/div/h3/text()'))!=0:
position_name = htmlElement.xpath('//*[@id="root"]/div[3]/div/div/h3/text()')[0]
else:
position_name = '无'
# print(position_name)
position_information['职位名称'] = position_name
if len(htmlElement.xpath('//*[@id="root"]/div[3]/div/div/div[2]/div[1]/span/text()'))!=0:
salary = htmlElement.xpath('//*[@id="root"]/div[3]/div/div/div[2]/div[1]/span/text()')[0]
else:
salary="无"
position_information['工资'] = salary
if len(htmlElement.xpath('//*[@id="root"]/div[3]/div/div/div[2]/div[1]/ul/li[1]//text()'))!=0:
position_city = htmlElement.xpath('//*[@id="root"]/div[3]/div/div/div[2]/div[1]/ul/li[1]//text()')[0]
else:
posirion_city = "无"
position_information['城市'] = position_city
if len(htmlElement.xpath('//*[@id="root"]/div[3]/div/div/div[2]/div[1]/ul/li[2]//text()'))!=0:
work_years = htmlElement.xpath('//*[@id="root"]/div[3]/div/div/div[2]/div[1]/ul/li[2]//text()')[0]
else:
work_years = "无"
position_information['工作经验'] = work_years
if len(htmlElement.xpath('//*[@id="root"]/div[3]/div/div/div[2]/div[1]/ul/li[3]//text()'))!=0:
education_background = htmlElement.xpath('//*[@id="root"]/div[3]/div/div/div[2]/div[1]/ul/li[3]//text()')[0]
else:
education_background = "无"
position_information['教育背景'] = education_background
if len(htmlElement.xpath('//*[@id="root"]/div[3]/div/div/div[2]/div[1]/ul/li[4]//text()'))!=0:
num_demanded = htmlElement.xpath('//*[@id="root"]/div[3]/div/div/div[2]/div[1]/ul/li[4]//text()')[0]
else:
num_demanded = "无"
position_information['人数需求'] = num_demanded
if len(htmlElement.xpath('//*[@id="root"]/div[4]/div[1]/div[1]/div[1]/div//text()'))!=0:
position_advantages = htmlElement.xpath('//*[@id="root"]/div[4]/div[1]/div[1]/div[1]/div//text()')
position_advantages = ",".join(position_advantages)
else:
position_advantages = "无"
position_information['职位亮点'] = position_advantages
if len(htmlElement.xpath('/html/body/div[1]/div[4]/div[1]/div[1]/div[2]/div//text()'))!=0:
position_desc = htmlElement.xpath('/html/body/div[1]/div[4]/div[1]/div[1]/div[2]/div//text()')
position_desc = " ".join(position_desc)
else:
position_desc = "无"
position_information['职位描述'] = position_desc
if len(htmlElement.xpath('/html/body/div[1]/div[4]/div[1]/div[1]/div[3]/div/span/text()'))!=0:
work_address = htmlElement.xpath('/html/body/div[1]/div[4]/div[1]/div[1]/div[3]/div/span/text()')[0]
else:
work_address = "无"
position_information['工作地点'] = work_address
except Exception as e:
print(e)
print("详情页面404或者加载太慢")
print("爬取成功并返回结果!")
return position_information
爬取详情页的时候,爬完以后返回的是字典,因为这样好写到CSV中。这样的话就完事了。还有一点就是算是我的一点教训吧,就是我觉得像我这个代码模拟浏览器的时候需要进行页面的关闭和切换,我觉得都放在固定的位置比较好。比如说都放在内部函数中,或者内部函数外,这样比较好检查代码。我刚开始位置就不固定,给自己整蒙了。
四.源代码:
我的代码都会加注释的,是我从第一遍运行到最后完成所有的改动都保留了,可能看起来会比较难受…………
from selenium import webdriver
from lxml import etree
import os
import time
from selenium .webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
import re
import csv
import sys
class ZLspider():
driver_path = r'E:\python_tools\geckodriver-v0.26.0-win64\geckodriver.exe'
option = webdriver.FirefoxOptions()
#option.add_argument('-headless')#这个是加无头模式
# option.set_preference('permissions.default.image', 2)#不让加载图片为了提速
# option.set_preference('permissions.default.stylesheet', 2)#不让加载CSS
def __init__(self,file):
self.browser = webdriver.Firefox(executable_path=ZLspider.driver_path,options=ZLspider.option)
self.url = 'https://www.zhaopin.com/'
self.wait = WebDriverWait(self.browser, 5)
self.out_file = file
self.to_console = sys.stdout
def write_console(self,*args):
sys.stdout = self.to_console
for arg in args:
print(arg)
def write_file(self,*args):
# sys.stdout = open(self.out_file,'a',encoding='utf-8')
# for arg in args:
# print(arg)
pass
def run(self):
self.browser.get(self.url)
# time.sleep(65)#让我登陆一下
# self.browser.close()#因为登陆以后会有新的页面跳出
# self.browser.switch_to.window(self.browser.window_handles[0])
source = self.browser.page_source
#因为网速原因有时候弹出框出的慢
# 因为会有弹出框
know_btn = self.wait.until(EC.element_to_be_clickable((By.XPATH, '/html/body/div[5]/div/div/button'))) # 按钮必须这样真TMD坑
know_btn.click()
# time.sleep(1)#感觉可删,不过影响不大
htmlElement = etree.HTML(source)
# 获取后面每个城市的网页链接
city_links_all = htmlElement.xpath('//div[@id="footer"]//li//a/@href')
# 获取城市名
city_names_all = htmlElement.xpath('//div[@id="footer"]//li//a/text()')#####这里验一下是不是页面有问题
##########################
###这里有问题,扬州的提取方式和其他的不一样,位置放的不一样,fuck!
# print(city_links_all)
# print(city_names_all)
# for i in range(len(city_links_all)):
# print(city_links_all[i],city_names_all[i])
city_links = []
city_names = ['北京', '上海', '天津', '重庆', '哈尔滨', '银川', '郑州', '济南', '太原', '合肥', '长春', '沈阳', '呼和浩特', '石家庄', '乌鲁木齐','兰州', '西宁', '西安', '张家界', '武汉', '南京', '成都', '贵阳', '昆明', '南宁', '西藏', '杭州', '南昌', '广州', '福州', '海口']
for i in range(len(city_names)):
city_links.append("")
self.write_console(len(city_links))
self.write_file(len(city_links))
for i in range(len(city_names_all)):
for index, city_name in enumerate(city_names):
if city_names_all[i] == city_name:
city_links[index] = city_links_all[i]
self.write_console(city_names[index],city_links[index])
self.write_file(city_names[index],city_links[index])
# print(city_names)###有几个城市名称和链接对不上
# print(city_links)
self.write_console("一共要爬"+str(len(city_names))+"个城市")
self.write_file("一共要爬"+str(len(city_names))+"个城市")
for i in range(len(city_names)):
self.write_console('正在获取'+ city_names[i]+'的信息,该城市链接为'+city_links[i])
self.write_file('正在获取'+ city_names[i]+'的信息,该城市链接为'+city_links[i])
time.sleep(1)#爬每一个城市前停一下
city_directory = city_names[i]#城市名即为目录名
if not os.path.exists(city_directory):
os.mkdir(city_directory)#创建每个城市的目录
#这个异常处理有意义吗?
self.request_city(city_links[i],city_names[i])
self.write_console(city_names[i] + '所有岗位已经爬取完毕')
self.write_file(city_names[i] + '所有岗位已经爬取完毕')
self.write_console('=' * 40)
self.write_file('=' * 40)
time.sleep(1)#认为可删
self.browser.close()
self.browser.switch_to.window(self.browser.window_handles[0]) # 这里爬完一整个城市,然后要关掉窗口
def request_city(self,url,city):
first_second_positions = {}
url = "https:"+url
self.browser.execute_script("window.open()")
self.browser.switch_to.window(self.browser.window_handles[1])#把当前控制页面切换到新一页
try:
self.browser.get(url)
city_source = self.browser.page_source
htmlElement = etree.HTML(city_source)
category_first_positions = htmlElement.xpath('//*[@id="root"]/div[3]/div/div[1]/ol/li/div[1]/text()')#大方向,比如IT,金融
for index,category_first_position in enumerate(category_first_positions):
category_second_positions = htmlElement.xpath('//*[@id="root"]/div[3]/div/div[1]/ol/li['+str(index+1)+']/div[2]/div/div/a//text()')
###################################
###还是有问题
#//*[@id="root"]/div[3]/div[2]/div[1]/ol/li[1]/div[2]/div/div//text()
first_second_positions[category_first_position] = category_second_positions
self.write_console(first_second_positions)
self.write_file(first_second_positions)
# category_second_positions = htmlElement.xpath('//*[@id="root"]/div[3]/div/div[1]/ol/li[1]/div[2]/div/div[2]//text()')#小方向,比如JAVA,PYTHON
# print(category_first_positions)
# print(category_second_positions)
# # print(category_first_positions,category_second_positions)
# time.sleep(1)
for key,value in first_second_positions.items():
if not os.path.exists(city+'/'+key):
key = re.sub(r'/', '', key)
if not os.path.exists(city+'/'+key):
os.mkdir(city+'/'+key)
for i in value:#这里的i就是每一个小方向,例如互联网IT下的python
road = city+'/'+key+'/'+i
if not os.path.exists(road+".csv"):
# second_url = 'https://sou.zhaopin.com/?jl=601&kw='+i+'&kt=3'
input = self.browser.find_element_by_xpath(
"/html/body/div[1]/div[1]/div/div[2]/div/div/div[2]/div/div/input")
js = 'document.querySelector(".zp-search__input").value="";'
self.browser.execute_script(js)#NB
#input.clear() ########忘了后果很严重,TMD这里这个失效了,上网找了个大神的方法
input.send_keys(i)
button = self.browser.find_element_by_xpath('//*[@id="root"]/div[1]/div/div[2]/div/div/div[2]/div/div/a')
button.click()
# try:
self.write_console('现在正在爬取' + city + "市" + key + "行业," + i + '岗位')
self.write_file('现在正在爬取' + city + "市" + key + "行业," + i + '岗位')
self.parse_second_position(road)
self.write_console(city + "市" + key + "行业," + i + '岗位,爬取完成')
self.write_file(city + "市" + key + "行业," + i + '岗位,爬取完成')
# except Exception as e:
# print(e)
# print(city + "市" + key + "行业," + i + "岗位页面加载出问题,城市页面没问题")
self.write_console('='*30)
self.write_file('='*30)
# time.sleep(1)去掉或许可以提速
self.browser.close()
self.browser.switch_to.window(self.browser.window_handles[1])
#time.sleep(1)
# time.sleep(1)
#self.browser.close()#某市某行业下的小方向爬完之后,关闭网页
# print(city+"市"+category_first_position+"行业,"+category_second_position+'岗位已爬取成功')
# self.browser.close()#关闭该城市爬完的岗位
# self.browser.switch_to.window(self.browser.window_handles[0])
# time.sleep(1)继续提速
except Exception as e:
self.write_console(e)
self.write_file(e)
self.write_console(city+"城市页面出问题")
self.write_file(city+"城市页面出问题")
#查看该城市所有的招聘信息
# bt = self.browser.find_element_by_class_name('jobs-hot__button--more')
# bt.click()
# time.sleep(3)
# self.browser.close()
# self.browser.switch_to.window(self.browser.window_handles[2])
# print(self.browser.current_url)
# time.sleep(10)
# self.browser.quit()
def parse_second_position(self,road):
try:
#i = 1#记录当前在爬的页数
second_position_informations = []
#self.browser.execute_script("window.open()")
#self.browser.switch_to.window(self.browser.window_handles[2])
self.browser.switch_to.window(self.browser.window_handles[2])
# self.browser.get(url)
# print(self.browser.current_url)
second_position_page_source = self.browser.page_source
htmlElement = etree.HTML(second_position_page_source)
element_judges = self.wait.until(EC.presence_of_all_elements_located((By.XPATH, '//*[@id="listItemPile"]/div[3]/div/div')))#这里是判断某地区的某行业中的某个小方向是否有招聘信息
# print(element_judges)
# print(element_judges[0].text)
judge = re.sub(r"[\s]","",element_judges[0].text)#这里是要去掉找不到那个中间的换行
# print(judge)#判断是否有信息
if judge != "很抱歉,您搜索的职位找不到!换个条件试试吧":
#print("现在在爬"+road+"第"+str(i)+"页")
element_as = self.wait.until(EC.presence_of_all_elements_located(
(By.XPATH, '//*[@id="listContent"]/div/div/a'))) # 这里得到的是元素a,列表。这里是为了防止网速慢,未加载出来
###########!!!!!!!这里面收到的错误类型不知道算什么.用TimeError,收不到这个错误类型 #
for element_a in element_as:
# print(element_a.get_attribute('href'))#具体职位的详情页面URL
link = element_a.get_attribute('href')
detail_information = self.parse_detail_position(link)
self.write_console(detail_information)
self.write_file(detail_information)
if detail_information:
second_position_informations.append(detail_information)
self.write_console("收到请求数据,并加入列表")
self.write_file("收到请求数据,并加入列表")
else:
self.write_console("请求数据为空")
self.write_file("请求数据为空")
self.write_file()
self.write_console()
self.browser.close()
self.browser.switch_to.window(self.browser.window_handles[2])
if len(second_position_informations)!=0:
####这个翻页我整不成,不弄了,单独调试没有一点问题
# next_btn = self.wait.until(EC.presence_of_all_elements_located(
# (By.XPATH, '//*[@id="pagination_content"]/div/button[2]')))
# # print()
# #这里是判断是否有翻页
# print("判断是否有下一页")
# print(type(next_btn))
# if len(htmlElement.xpath('//*[@id="pagination_content"]/div/button[2]/@disabled'))!=0:
# break
# else:
# next_btn[0].click()
# i = i+1
# print("已点击翻页按钮")
#个人一些见解:如果try内部有函数,函数内发生异常(即使内部函数中也有try except依旧会出现触发外部的try except)如果是try except嵌套try except那么如果内层出现的错误符合内层的except则不会触发外部的except
#此处应该拉到前面,这样如果IF成立,也会建立文件
with open(road + '.csv', 'a', encoding='utf-8', errors='ignore') as fp:
self.write_console("开始写入数据")
self.write_file("开始写入数据")
fieldnames = ['职位名称', '工资', '城市', '工作经验', '教育背景', '人数需求', '职位亮点', '职位描述', '工作地点']
writer = csv.DictWriter(fp, lineterminator='\n', fieldnames=fieldnames)
writer.writeheader()
for row in second_position_informations:
try:
writer.writerow(row)
except UnicodeEncodeError:
self.write_console("写入文件时,出现编码问题")
self.write_file("写入文件时,出现编码问题")
self.write_console("数据写入完成")
self.write_file("数据写入完成")
self.write_console()
self.write_file()
else:
with open(road + '.csv', 'a', encoding='utf-8', errors='ignore') as fp:
self.write_console("开始写入数据")
self.write_file("开始写入数据")
fieldnames = ['职位名称', '工资', '城市', '工作经验', '教育背景', '人数需求', '职位亮点', '职位描述', '工作地点']
writer = csv.DictWriter(fp, lineterminator='\n', fieldnames=fieldnames)
writer.writeheader()
except TimeoutException as e:
self.write_console("招聘信息未加载出来")
self.write_file("招聘信息未加载出来")
self.write_console(e)
self.write_file()
except BaseException as e:
self.write_file(e)
self.write_console(e)
# time.sleep(3)#为了防止网速慢导致加载不出来
# detail_position_page_urls = htmlElement.xpath('//*[@id="listContent"]/div/div/a/@href')
# print(detail_position_page_urls)
# detail_position_page_urls =
# print(detail_position_page_urls)
# for element_a in element_as:
# print(element_a.get_attribute('href'))
# self.parse_detail_position(element_a.get_attribute('href'))
# break
# for detail_position_page_url in detail_position_page_urls:
# self.parse.detail_position(detail_position_page_url)
# judge_next = htmlElement.xpath('/html/body/div[1]/div[1]/div[4]/div[3]/div[3]/div/div[11]/div/div[2]/div/button[2]/@disabled')
# print(judge_next)#//*[@id="pagination_content"]/div/button[2]/@disabled
# if judge_next[0] == "disabled":
# break
# else:
# next_btn = self.wait.until(
# EC.element_to_be_clickable((By.XPATH, '/html/body/div[5]/div/div/button'))) # 按钮必须这样真TMD坑
# next_btn.click()
###############################################!!!!!!!!!!!!!!!!!!!!
##好像是如果try中调用函数,然后这个函数中也有try,然后函数中发生异常,那么外层的也会发生异常
# print("出来for循环")
##此处有没有方法打开文件,然后再文件中调函数,然后在内函数中写文件
def parse_detail_position(self,url):
#print(url)
self.write_console('爬取中…………')
self.write_file('爬取中…………')
position_information = {}
self.browser.execute_script("window.open()")
self.browser.switch_to.window(self.browser.window_handles[3])
try:
self.browser.get(url)#因为这里有可能请求不到页面
# source = self.browser.page_source
# htmlElement = etree.HTML(source)
# print(htmlElement)
self.write_console("等待加载")
self.write_file("等待加载")
self.wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="root"]/div[3]/div/div/h3')))
# page_htmlElement = page_htmlElement.xpath('//*[@id="root"]')[0]#因为返回的是列表!!!!!!
# print(len(page_htmlElement))
self.write_file("加载完毕")
self.write_console("加载完毕")
source = self.browser.page_source
htmlElement = etree.HTML(source)
if len(htmlElement.xpath('//*[@id="root"]/div[3]/div/div/h3/text()'))!=0:
position_name = htmlElement.xpath('//*[@id="root"]/div[3]/div/div/h3/text()')[0]
else:
position_name = '无'
# print(position_name)
position_information['职位名称'] = position_name
if len(htmlElement.xpath('//*[@id="root"]/div[3]/div/div/div[2]/div[1]/span/text()'))!=0:
salary = htmlElement.xpath('//*[@id="root"]/div[3]/div/div/div[2]/div[1]/span/text()')[0]
else:
salary="无"
position_information['工资'] = salary
if len(htmlElement.xpath('//*[@id="root"]/div[3]/div/div/div[2]/div[1]/ul/li[1]//text()'))!=0:
position_city = htmlElement.xpath('//*[@id="root"]/div[3]/div/div/div[2]/div[1]/ul/li[1]//text()')[0]
else:
posirion_city = "无"
position_information['城市'] = position_city
if len(htmlElement.xpath('//*[@id="root"]/div[3]/div/div/div[2]/div[1]/ul/li[2]//text()'))!=0:
work_years = htmlElement.xpath('//*[@id="root"]/div[3]/div/div/div[2]/div[1]/ul/li[2]//text()')[0]
else:
work_years = "无"
position_information['工作经验'] = work_years
if len(htmlElement.xpath('//*[@id="root"]/div[3]/div/div/div[2]/div[1]/ul/li[3]//text()'))!=0:
education_background = htmlElement.xpath('//*[@id="root"]/div[3]/div/div/div[2]/div[1]/ul/li[3]//text()')[0]
else:
education_background = "无"
position_information['教育背景'] = education_background
if len(htmlElement.xpath('//*[@id="root"]/div[3]/div/div/div[2]/div[1]/ul/li[4]//text()'))!=0:
num_demanded = htmlElement.xpath('//*[@id="root"]/div[3]/div/div/div[2]/div[1]/ul/li[4]//text()')[0]
else:
num_demanded = "无"
position_information['人数需求'] = num_demanded
if len(htmlElement.xpath('//*[@id="root"]/div[4]/div[1]/div[1]/div[1]/div//text()'))!=0:
position_advantages = htmlElement.xpath('//*[@id="root"]/div[4]/div[1]/div[1]/div[1]/div//text()')
position_advantages = ",".join(position_advantages)
else:
position_advantages = "无"
position_information['职位亮点'] = position_advantages
if len(htmlElement.xpath('/html/body/div[1]/div[4]/div[1]/div[1]/div[2]/div//text()'))!=0:
position_desc = htmlElement.xpath('/html/body/div[1]/div[4]/div[1]/div[1]/div[2]/div//text()')
position_desc = " ".join(position_desc)
else:
position_desc = "无"
position_information['职位描述'] = position_desc
if len(htmlElement.xpath('/html/body/div[1]/div[4]/div[1]/div[1]/div[3]/div/span/text()'))!=0:
work_address = htmlElement.xpath('/html/body/div[1]/div[4]/div[1]/div[1]/div[3]/div/span/text()')[0]
else:
work_address = "无"
position_information['工作地点'] = work_address
self.write_console("详情页爬取成功")
self.write_file("详情页爬取成功")
self.write_console(position_information)
self.write_file(position_information)
return position_information
except TimeoutException as e:
self.write_console("详情页面404或者加载太慢")
self.write_file("详情页面404或者加载太慢")
except BaseException as e:
self.write_console("详情页面出现非超时异常")
self.write_file("详情页面出现非超时异常")
self.write_console(e)
self.write_file(e)
self.write_console("详情页爬取结束并返回结果!")
self.write_file("详情页爬取结束并返回结果!")
#####感觉这里应该修改一下,因为如果页面没加载出来,就会返回一个空值,这样列表会嵌套空字典
if __name__ == "__main__":
spider = ZLspider("01.txt")
spider.run()
五.遗留问题:
1.某个城市页面中的我想进入招聘信息页面,也就是某个大方向下某个小方向中的招聘信息,可不可以采取获取链接或者是点击的方式?
2.某城市的某个大方向下某个小方向中的招聘信息翻页问题。
3.能不能在对速度影响不大的情况下让程序每次执行的时候可以精确的查看某一条招聘信息是否在CSV中,这样可以让损失更小。
六.代码参考:
设置不加载CSS和图片,以及设置成headless参考链接:https://blog.csdn.net/formatfa/article/details/88680303
看了比较多的崔庆才大神写的《Python3网络爬虫开发实战》
可能还有,但是忘记了收藏博客,下次我会更加注意!
七.总结:
我个人认为智联的反爬可能算是比较友好的,我一开始比较担心封我的IP但是最后也没出问题。这个方法的话,反正是挺慢的,估计我要完成我的计划可能要一天一夜吧。还有就是感觉这个selenium方式受网速影响比较大,等待时间设置太长吧,会影响程序速度,但是太短吧又会损失数据,很纠结,我选择了要速度…………
我知道自己还有很多不足,希望可以得到大家的指导!然后如果文章中哪里影响到您,可以联系我,我修改或者删除文章。

















 2721
2721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









