Abstract

1.导入库
import copy
import torch
import torch.nn.functional as F
from torch import nn
import math
2.模型架构
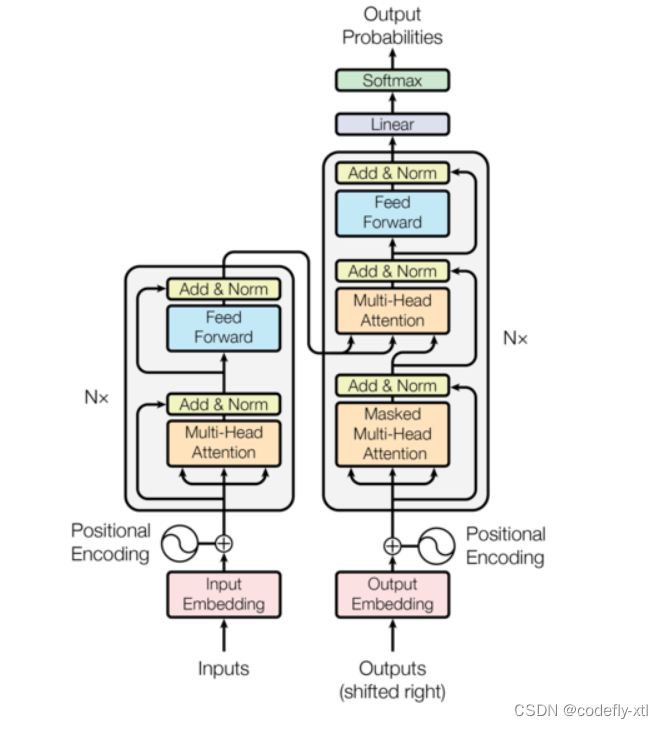
1.1 PositionalEncoding
class PositionalEncoding(nn.Module):
def __init__(self, device):
super().__init__()
self.device = device
def forward(self, X):
batch_size = X.shape[0]
num_steps = X.shape[1]
embedding_size = X.shape[2]
position = torch.zeros(num_steps, embedding_size, device=self.device)
value = torch.arange(num_steps, device=self.device).repeat(embedding_size, 1).permute(1, 0) / torch.pow(10000,torch.arange(embedding_size,device=self.device) / embedding_size).repeat(num_steps, 1)
position[:, 0::2] = torch.sin(value[:, 0::2])
position[:, 1::2] = torch.cos(value[:, 1::2])
return value.repeat(batch_size, 1, 1)
1.2 Multi_Head Attention
class MultiHeadAttention(nn.Module):
def __init__(self, query_size, key_size, value_size, num_hiddens, num_heads, device):
super().__init__()
self.device = device
self.num_heads = num_heads
self.W_Q = nn.Linear(query_size, num_hiddens, bias=False)
self.W_K = nn.Linear(key_size, num_hiddens, bias=False)
self.W_V = nn.Linear(value_size, num_hiddens, bias=False)
self.W_O = nn.Linear(num_hiddens, num_hiddens, bias=False)
def reform(self, X):
X = X.reshape(X.shape[0], X.shape[1], self.num_heads, -1)
X = X.permute(0, 2, 1, 3)
X = X.reshape(-1, X.shape[2], X.shape[3])
return X
def reform_back(self, X):
X = X.reshape(-1, self.num_heads, X.shape[1], X.shape[2])
X = X.permute(0, 2, 1, 3)
X = X.reshape(X.shape[0], X.shape[1], -1)
return X
def attention(self, queries, keys, values, valid_len):
keys_num_steps = keys.shape[1]
queries_num_steps = queries.shape[1]
d = queries.shape[-1]
A = torch.bmm(queries, keys.transpose(1, 2)) / math.sqrt(d)
if valid_len is not None:
valid_len = torch.repeat_interleave(valid_len, repeats=self.num_heads, dim=0)
mask = torch.arange(1, keys_num_steps + 1, device=self.device)[None, None, :] > valid_len[:, None, None]
mask = mask.repeat(1, queries_num_steps, 1)
A[mask] = -1e6
else:
mask = torch.triu(torch.arange(keys_num_steps).repeat(queries_num_steps, 1), 1) > 0
A[:, mask] = -1e6
A_softmaxed = F.softmax(A, dim=-1)
attention = torch.bmm(A_softmaxed, values)
return attention
def forward(self, queries, keys, values, valid_len):
Q = self.W_Q(queries)
K = self.W_K(keys)
V = self.W_V(values)
Q = self.reform(Q)
K = self.reform(K)
V = self.reform(V)
attention = self.attention(Q, K, V, valid_len)
attention = self.reform_back(attention)
return self.W_O(attention)
1.3 Feed Forward
class FeedForward(nn.Module):
def __init__(self, embedding_size):
super().__init__()
self.linear1 = nn.Linear(embedding_size, 2048)
self.linear2 = nn.Linear(2048, embedding_size)
def forward(self, X):
return self.linear2(F.relu(self.linear1(X)))
1.4 SubLayer
class SubLayer(nn.Module):
def __init__(self, layer, embedding_size):
super().__init__()
self.layer = layer
self.norm = nn.LayerNorm(embedding_size)
def forward(self, queries, keys=None, values=None, valid_len=None):
old_X = queries
if isinstance(self.layer, MultiHeadAttention):
X = self.layer(queries, keys, values, valid_len)
else:
X = self.layer(queries)
X = old_X + X
return self.norm(X)
1.5 EncoderBlock
class EncoderBlock(nn.Module):
def __init__(self, embedding_size, num_heads, device):
super().__init__()
self.device = device
query_size = key_size = value_size = num_hiddens = embedding_size
multiHeadAttention = MultiHeadAttention(query_size, key_size, value_size, num_hiddens, num_heads, self.device)
feedForward = FeedForward(embedding_size)
self.subLayer1 = SubLayer(multiHeadAttention, embedding_size)
self.subLayer2 = SubLayer(feedForward, embedding_size)
def forward(self, X, valid_len):
X = self.subLayer1(X, X, X, valid_len)
X = self.subLayer2(X)
return X
1.6 DecoderBlock
class DecoderBlock(nn.Module):
def __init__(self, embedding_size, num_heads, i, device):
super().__init__()
self.device = device
query_size = key_size = value_size = num_hiddens = embedding_size
multiHeadAttention1 = MultiHeadAttention(query_size, key_size, value_size, num_hiddens, num_heads, self.device)
multiHeadAttention2 = MultiHeadAttention(query_size, key_size, value_size, num_hiddens, num_heads, self.device)
feedForward = FeedForward(embedding_size)
self.subLayer1 = SubLayer(multiHeadAttention1, embedding_size)
self.subLayer2 = SubLayer(multiHeadAttention2, embedding_size)
self.subLayer3 = SubLayer(feedForward, embedding_size)
self.i = i
self.front = None
def forward(self, encoder_output, encoder_valid_len, X):
if self.training:
key_values = X
else:
key_values = torch.cat([self.front, X], dim=1)
self.front = key_values
X = self.subLayer1(X, key_values, key_values)
X = self.subLayer2(X, encoder_output, encoder_output, encoder_valid_len)
X = self.subLayer3(X)
return X
1.7 Encoder
class Encoder(nn.Module):
def __init__(self, encoder_vocab_size, embedding_size, num_layers, num_heads, device):
self.device = device
super().__init__()
self.num_layers = num_layers
self.embeddingLayer = nn.Embedding(encoder_vocab_size, embedding_size)
self.positionalEncodingLayer = PositionalEncoding(device)
self.encoderLayers = nn.ModuleList(
[copy.deepcopy(EncoderBlock(embedding_size, num_heads, device)) for _ in range(num_layers)])
self.embedding_size = embedding_size
def forward(self, source, encoder_valid_len):
X = self.embeddingLayer(source) * math.sqrt(self.embedding_size)
positionalembedding = self.positionalEncodingLayer(X)
X = X + positionalembedding
for i in range(self.num_layers):
X = self.encoderLayers[i](X, encoder_valid_len)
return X
1.8 Decoder
class Decoder(nn.Module):
def __init__(self, decoder_vocab_size, embedding_size, num_layers, num_heads, device):
super().__init__()
self.device = device
self.num_layers = num_layers
self.embeddingLayer = nn.Embedding(decoder_vocab_size, embedding_size)
self.positionalEncodingLayer = PositionalEncoding(device=self.device)
self.decoderLayers = nn.ModuleList(
[copy.deepcopy(DecoderBlock(embedding_size, num_heads, i, self.device)) for i in range(num_layers)])
self.embedding_size = embedding_size
def forward(self, encoder_output, encoder_valid_len, target):
X = self.embeddingLayer(target) * math.sqrt(self.embedding_size)
positionalembedding = self.positionalEncodingLayer(X)
X = X + positionalembedding
for i in range(self.num_layers):
X = self.decoderLayers[i](encoder_output, encoder_valid_len, X)
return X
1.9 EncoderDecoder
class EncoderDecoder(nn.Module):
def __init__(self, encoder_vocab_size, decoder_vocab_size, embedding_size, num_layers, num_heads, device):
super().__init__()
self.device = device
self.encoder = Encoder(encoder_vocab_size, embedding_size, num_layers, num_heads, self.device)
self.decoder = Decoder(decoder_vocab_size, embedding_size, num_layers, num_heads, self.device)
self.dense = nn.Linear(embedding_size, decoder_vocab_size)
def forward(self, source, encoder_valid_len, target):
encoder_output = self.encoder(source, encoder_valid_len)
decoder_output = self.decoder(encoder_output, encoder_valid_len, target)
return self.dense(decoder_output)























 516
516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









