










Dual Contrastive Learning: Text Classification via Label-Aware Data Augmentation
PyTorch实现:https://github.com/hiyouga/Dual-Contrastive-Learning.
Abstract
对比学习在无监督环境下通过自我监督进行表征学习方面取得了显著的成功。然而,有效地使对比学习适应于监督学习任务,在实践中仍然是一个挑战。在这项工作中,作者引入了一个双对比学习(DualCL)框架,它同时学习输入样本的特征和分类器的参数。具体来说,DualCL将分类器的参数视为关联到不同标签的增强样本,然后利用输入样本和增强样本之间的对比学习。对5个基准文本分类数据集及其低资源版本的实证研究表明,其分类精度的提高,并证实了学习DualCL的判别表示的能力。对5个基准文本分类数据集及其低资源版本的实证研究表明,其分类精度的提高,并证实了学习DualCL的判别表示的能力。
1 Introduction
表示法学习是现代深度学习的核心。在无监督学习的背景下,对比学习最近已被证明是获得下游任务的通用表征的有效方法。简单地说,无监督对比学习采用了一个损失函数,它迫使同一例子的不同“观点”的表示相似,而不同例子的表示则不同。最近,对比学习的有效性被证明是在同时实现了“对齐”和“一致性”方面。
这种对比学习方法也适用于监督表示学习,其中使用了类似的对比损失,坚持同一类中的例子表示是相似的,而不同类中的例子表示是不同的。然而,尽管它取得了成功,但与无监督的对比学习相比,这种方法似乎没有那么有原则。例如,表示法的一致性不再有效;它也不是必需的。事实上,我们认为标准的监督对比学习方法不是自然的监督表示学习。这至少体现在这种方法的结果不能直接给我们一个分类器,而需要开发另一个分类算法来解决分类任务。
本文旨在开发一种更自然的方法来实现在监督环境下的对比学习。开发的关键见解是,监督表示学习应该包括学习两种数量:一个输入x在适当的空间特性z足够的分类任务,和另一个是分类器的空间,或者分类器的参数θ作用于空间;我们将这个分类器称为“一例”分类器,例如 x x x。在这个视图中,很自然与每个例子 x x x两个量,一个适当的特征空间维度 d d d的向量 z ∈ R d z∈R^d z∈Rd和给 x x x定义一个线性分类器的矩阵 θ ∈ R d × K θ∈R^{d×K} θ∈Rd×K(假设K类分类问题),注意 z 和 θ 依 赖 于 x z和θ依赖于x z和θ依赖于x。在监督设置下的表示学习问题可以看作是学习为输入示例 x x x生成对 ( z , θ ) (z,θ) (z,θ)。
为了使分类器 θ θ θ对特征 z z z有效,只需要使用标准的交叉熵损失将 θ T z θ^Tz θTz的softmax transform与 x x x的标签对齐。此外,一种对比学习方法可以用来强制跨示例对这些 ( z , θ ) (z,θ) (z,θ)表示的约束。具体来说,让 θ ∗ θ^∗ θ∗表示与 x x x的地面真实标签对应的 θ θ θ列,可以设计两个对比损失。第一个损失对比 ( z , θ ∗ ) (z,θ^∗) (z,θ∗)有许多 ( z ′ , θ ∗ ) (z',θ^∗) (z′,θ∗),其中 z ′ z' z′是一个具有不同标签为 x x x的例子的特征;第二个对比 ( z , θ ∗ ) (z,θ^∗) (z,θ∗)有许多 ( z , θ ′ ∗ ) (z,θ^{'∗}) (z,θ′∗)进行对比,其中 θ ′ θ' θ′是与来自不同类的一个示例关联的分类器。作者将这个学习框架称为双对比学习(DualCL)。
尽管作者提出了基于概念洞察力的双重对比学习,但他们认为也有可能将这种学习方案解释为利用一种独特的数据增强方法。特别地,对于每个示例 x x x,其 θ θ θ的每一列都可以被视为“标签感知的输入表示”,或者是在特征空间中注入了标签信息的 x x x的增强视图。表1中的数字说明了这种方法的好处,从左边的两个数字可以看出,标准的对比学习不能利用标签信息。相反,从右边的两个图来看,DualCL有效地利用标签信息对其类中的输入样本进行分类。

在实验中,作者在5个基准文本分类数据集上验证了DualCL的有效性。通过使用双对比损失对预先训练好的语言模型(BERT和RoBERTa)进行微调,DualCL与现有的对比学习监督基线相比获得了最好的性能。作者还发现,DualCL提高了分类精度,特别是在低资源的场景下。此外,作者通过可视化所学习的表征和注意力图,对DualCL给出了一些解释。
本文Contribution总结如下:
-
提出了dual contrastive learning (DualCL),以自然地适应对比损失的监督设置。
-
引入标签感知数据增强来获得输入样本的多个视图,用于DualCL的训练。
-
在5个基准文本分类数据集上实证验证了DualCL框架的有效性。
2 Preliminaries
考虑一个具有 K K K个类的文本分类任务。假设给定的数据集 { x i , y i } i = 1 N \{x_i,y_i\}^{N}_{i=1} {xi,yi}i=1N包含 N N N个训练样本,其中 x i ∈ R L x_i∈R^L xi∈RL是由L个单词组成的输入句子, y i ∈ { 1 , 2 , ⋅ ⋅ ⋅ , K } y_i∈\{1,2,···,K\} yi∈{1,2,⋅⋅⋅,K}是分配给输入的标签。在整个研究过程中,作者用 I = { 1 , 2 , ⋅ ⋅ ⋅ , N } I=\{1,2,···,N\} I={1,2,⋅⋅⋅,N}表示训练样本的指标集,用 K = { 1 , 2 , ⋅ ⋅ ⋅ , K } K=\{1,2,···,K\} K={1,2,⋅⋅⋅,K}表示标签的指标集。
在介绍本文的方法之前,自我监督对比学习的家族的有效性已在许多研究中被广泛证实。给定N个训练样本 { x i } i = 1 N \{x_i\}^N_{i=1} {xi}i=1N,其中有一些增强样本,其中每个样本在数据集中至少有一个增强样本。设 j ( i ) j(i) j(i)为第 i i i个样本的增广样本的指标,标准对比损失定义为:
L s e l f = 1 N ∑ i ∈ I − log exp ( z i ⋅ z j ( i ) / τ ) ∑ a ∈ A i exp ( z i ⋅ z a / τ ) L_{self}=\frac{1}{N}\sum_{i∈I}{-\log\frac{\exp(z_i·z_{j(i)}/\tau)}{\sum_{a∈A_i}\exp(z_i·z_{a}/\tau)}} Lself=N1i∈I∑−log∑a∈Aiexp(zi⋅za/τ)exp(zi⋅zj(i)/τ)
其中 z i z_i zi为 x i x_i xi的归一化表示, A i : = I ∖ { i } A_i:=I\setminus \{i\} Ai:=I∖{i}为对比样本的索引集,符号表示点积, τ ∈ R + τ∈R^+ τ∈R+为温度因子。作者将第 i i i个样本定义为锚点,第 j ( i ) j(i) j(i)个样本是阳性样本,剩下的 N − 2 N−2 N−2个样本是第 i i i个样本的阴性样本。
然而,自监督对比学习不能利用监督信号。先前的研究以一种直接的方式将监督与对比学习相结合。它只是将同一类别的样本作为阳性样本,将不同类别的样本作为阴性样本。为监督任务定义了以下对比损失:
L s u p = 1 N ∑ i ∈ I 1 ∣ P i ∣ ∑ p ∈ P i − log exp ( z i ⋅ z j ( i ) / τ ) ∑ a ∈ A i exp ( z i ⋅ z a / τ ) L_{sup}=\frac{1}{N}\sum_{i∈I}\frac{1}{|P_i|}\sum_{p∈P_i}{-\log\frac{\exp(z_i·z_{j(i)}/\tau)}{\sum_{a∈A_i}\exp(z_i·z_{a}/\tau)}} Lsup=N1i∈I∑∣Pi∣1p∈Pi∑−log∑a∈Aiexp(zi⋅za/τ)exp(zi⋅zj(i)/τ)
其中, P i : = { p ∈ A i : y p = y i } P_i:=\{p∈A_i:y_p=y_i\} Pi:={p∈Ai:yp=yi}是阳性样本的指标集, ∣ P i ∣ |P_i| ∣Pi∣是 P i P_i Pi的基数
虽然这种方法已经显示出了它的优越性,但除了对比项外,还需要学习一个使用交叉熵损失的线性分类器。这是因为对比损失只能学习输入示例的一般表示。因此,作者认为,到目前为止发展起来的有监督的对比学习似乎是无监督的对比学习对分类问题的一种幼稚的适应。人们可能期望一个更优雅的方法在监督设置中的对比学习。
3 Dual Contrastive Learning
本文提出了一种学习“dual”表示的有监督的对比学习方法。第一个是在适当的空间中对分类任务的鉴别特征的input representation,第二个是分类器,或等价于该空间中分类器的参数。设 z i ∈ R d z_i∈R^d zi∈Rd为输入示例 x i x_i xi的特征,而 θ i ∈ R d × K θ_i∈R^{d×K} θi∈Rd×K为与 x i x_i xi关联的分类器。本文的目的是学习 z i 和 θ i 的 z_i和θ_i的 zi和θi的(标准化)表示,以使用所提出的方法将 θ i T z i θ^T_i z_i θiTzi的软极大变换与 x i x_i xi的标签对齐。
3.1 Label-Aware Data Augmentation
为了获得训练样本的不同视图,作者利用数据增强的思想来获得特征 z i z_i zi和分类器 θ i θ_i θi的表示。将 θ i 的 第 k θ_i的第k θi的第k列视为与标签 k k k相关联的输入示例 x i x_i xi的唯一视图,用 θ i k θ^k_i θik表示。称 θ i k θ^k_i θik为标签感知输入表示,因为它是注入标签 k 信 息 的 x i k信息的x_i k信息的xi的增强视图。
本文引入了具有标签感知功能的数据增强。实际上并没有引入额外的样本,只在一个前馈过程中得到每个样本的 K + 1 K+1 K+1视图。具体来说,使用一个预先训练过的编码器来学习1个特征表示和K个标签感知的输入表示,其中K是类的数量。预训练的语言模型(plm)在提取自然语言表示方面表现出显著的性能。因此,采用plm作为预先训练的编码器。让预先训练的编码器(如BERT,RoBERTa)为 f f f。将输入句子和所有可能的标签输入编码器f,并将每个标签视为一个标记。具体来说,作者列出了所有的标签 { 1 , . . . , K } \{1,...,K\} {1,...,K},并将它们插入到输入的句子 x i x_i xi之前。这个过程形成了一个新的序列里 r i ∈ R L + K r_i∈R^{L+K} ri∈RL+K。然后利用编码器 f f f提取该序列中每个token的特征。
作者将[CLS]标记的特征作为每个输入句子的表示,并将每个标签对应的标记的特征作为对标签进行感知的输入表示。用 z i 表 示 输 入 x i z_i表示输入x_i zi表示输入xi的特征表示,用 θ i k 表 示 标 签 k θ^k_i表示标签k θik表示标签k的标签感知输入表示。在实践中,以标签的名称作为标记,形成序列 r i r_i ri,如“positive”、“negative”等。对于包含多个单词的标签,采用token特征的平均池化来获得具有标签感知的输入表示。
3.2 Dual Contrastive Loss
利用输入示例 x i x_i xi的特征表示 z i z_i zi和分类器 θ i θ_i θi,作者尝试将 θ i T z i θ^T_i z_i θiTzi的softmax transform与 x i x_i xi的标签对齐。设 θ i ∗ 表 示 θ i θ^∗_i表示θ_i θi∗表示θi的列,对应于 x i x_i xi的ground-truth标签。期望点积 θ i ∗ T z i θ^{∗T}_iz_i θi∗Tzi是最大化的。因此,作者转向去学习带有监督信号的 θ i 和 z i θ_i和z_i θi和zi的更好的表示。这里本文定义了对偶对比损失来利用不同训练样本之间的关系,如果 x j 与 x i x_j与x_i xj与xi有相同的标签,则试图最大化 θ i ∗ T z j θ^{∗T}_iz_j θi∗Tzj,而如果 x j 与 x i x_j与x_i xj与xi有不同的标签,则最小化 θ i ∗ T z j θ^{∗T}_iz_j θi∗Tzj。
给定一个来自输入示例 x i 的 锚 定 z i x_i的锚定z_i xi的锚定zi,以 { θ j ∗ } j ∈ P i \{θ^∗_j\}_{j∈P_i} {θj∗}j∈Pi作为正样本, { θ j ∗ } j ∈ A i ∖ P i \{θ^∗_j\}_{j∈A_i\setminus P_i} {θj∗}j∈Ai∖Pi作为负样本,并定义以下对比损失:
L z = 1 N ∑ i ∈ I 1 ∣ P i ∣ ∑ p ∈ P i − log exp ( θ p ∗ ⋅ z i / τ ) ∑ a ∈ A i exp ( θ a ∗ ⋅ z i / τ ) L_{z}=\frac{1}{N}\sum_{i∈I}\frac{1}{|P_i|}\sum_{p∈P_i}{-\log\frac{\exp(θ^*_p·z_i/\tau)}{\sum_{a∈A_i}\exp(θ^*_a·z_i/\tau)}} Lz=N1i∈I∑∣Pi∣1p∈Pi∑−log∑a∈Aiexp(θa∗⋅zi/τ)exp(θp∗⋅zi/τ)
其中 τ ∈ R + τ∈R+ τ∈R+是温度因子, A i : = I ∖ { i } Ai:=I\setminus\{i\} Ai:=I∖{i}是对比样本的指标集, P i : = { p ∈ A i : y p = y i } Pi:=\{p∈A_i:y_p=y_i\} Pi:={p∈Ai:yp=yi}是正样本的指标集, ∣ P i ∣ 是 P i |P_i|是P_i ∣Pi∣是Pi的基数。
同样地,给定一个锚点 θ i ∗ θ^∗_i θi∗,可以取 { z j } j ∈ P i \{z_j\}_{j∈P_i} {zj}j∈Pi作为正样本, { z j } j ∈ A i ∖ P i \{z_j\}_{j∈A_i \setminus P_i} {zj}j∈Ai∖Pi作为负样本,并定义另一个对比损失:
L θ = 1 N ∑ i ∈ I 1 ∣ P i ∣ ∑ p ∈ P i − log exp ( θ i ∗ ⋅ z p / τ ) ∑ a ∈ A i exp ( θ i ∗ ⋅ z a / τ ) L_{θ}=\frac{1}{N}\sum_{i∈I}\frac{1}{|P_i|}\sum_{p∈P_i}{-\log\frac{\exp(θ^*_i·z_p/\tau)}{\sum_{a∈A_i}\exp(θ^*_i·z_a/\tau)}} Lθ=N1i∈I∑∣Pi∣1p∈Pi∑−log∑a∈Aiexp(θi∗⋅za/τ)exp(θi∗⋅zp/τ)
双对比损失是上述两个对比损失项的组合:
L D u a l = L z + L θ L_{Dual}=L_z+L_\theta LDual=Lz+Lθ
3.3 Joint Training & Prediction
为了充分利用监督信号,本文还期望 θ i θ_i θi是一个很好的 z i z_i zi分类器。因此,作者使用一个改进版本的交叉熵损失来最大化每个输入示例 x i 的 θ i ∗ T z i x_i的θ^{∗T}_iz_i xi的θi∗Tzi:
L C E = 1 N ∑ i ∈ I − log θ i ∗ ⋅ z i ∑ k ∈ K θ i k ⋅ z i L_{CE}=\frac{1}{N}\sum_{i∈I}-\log \frac{θ^*_i·z_i}{\sum_{k∈K} θ^k_i·z_i} LCE=N1i∈I∑−log∑k∈Kθik⋅ziθi∗⋅zi
最后最小化这两个训练目标来训练编码器 f f f。这两个目标同时提高了特征的表示质量和分类器的表示质量。总体损失应为:
L o v e r a l l = L C E + λ L D u a l L_{overall}=L_{CE}+\lambda L_{Dual} Loverall=LCE+λLDual
其中, λ λ λ是一个控制双对比损失项影响的超参数。在分类过程中,使用训练好的编码器 f f f来生成输入句子 x i x_i xi的特征表示 z i 和 分 类 器 θ i z_i和分类器θ_i zi和分类器θi。这里的 θ i θ_i θi可以看作是一个“one-example”的分类器,例如 x i x_i xi。将 θ i T z i θ^T_i z_i θiTzi的argmax结果作为模型预测:
y ^ i = arg max k ( θ i k ⋅ z i ) \hat y_i=\arg\max_k(\theta^k_i ·z_i) y^i=argkmax(θik⋅zi)
图1展示了dual对比学习的框架,其中
e
C
L
S
e_{CLS}
eCLS是特征表示,
e
P
O
S
e_{POS}
ePOS和
e
N
E
G
e_{NEG}
eNEG是分类器表示。在这个具体的例子中,作者假设具有“positive”类的目标样本作为锚点,并且有一个正样本具有相同的类标签,而有一个具有不同的类标签的负样本。双对比损失旨在同时将特征表示吸引到正样本之间的分类器表示上,并将特征表示排斥到负样本之间的分类器上。

3.4 The Duality between Representations
对比损失采用点积函数作为表示之间相似性的度量。这就带来了DualCL中的特征表示 z z z和分类器表示 θ θ θ之间的对偶关系。在线性分类器中,输入特征与参数之间的关系也出现了类似的现象。然后,可以将 θ θ θ看作是一个线性分类器的参数,这样预先训练好的编码器 f f f就可以为每个输入样本生成一个线性分类器。因此,DualCL很自然地学习如何为每个输入样本生成一个线性分类器来执行分类任务。
3.5 Theoretical Justification of DualCL
本节给出了dual对比学习的理论证明。设 X = { x i } i = 1 N X=\{x_i\}^N_{i=1} X={xi}i=1N和 Y = { y i } i = 1 N Y=\{y_i\}^N_{i=1} Y={yi}i=1N为 N N N个训练样本的输入和标签。下面的定理适用于对偶对比学习。
Theorem. 假设有一个常数 ϵ \epsilon ϵ, p ( x i , y i ) ≥ ϵ p(x_i,y_i)≥\epsilon p(xi,yi)≥ϵ持有所有的 i ∈ I i∈I i∈I和 p ( y j ∣ x i ) p ( y j ) ∝ ϕ ( x i , y j ) \frac{p(yj|xi)}{p(yj)}∝\phi(x_i,y_j) p(yj)p(yj∣xi)∝ϕ(xi,yj):
M I ( X , , Y ) ≥ log N − ϵ L D u a l MI(X,,Y)≥\log N-\epsilon L_{Dual} MI(X,,Y)≥logN−ϵLDual
其中 ϕ \phi ϕ是一个可以有不同定义的对称函数。在本文的例子中, ϕ ( x i , y j ) = ( exp ( θ i ∗ ⋅ z j ) + exp ( θ j ∗ ⋅ z i ) ) / 2 \phi (x_i,y_j)=(\exp(\theta^*_i · z_j)+\exp(\theta^*_j · z_i))/2 ϕ(xi,yj)=(exp(θi∗⋅zj)+exp(θj∗⋅zi))/2
可以发现,最小化对偶监督对比损失等价于最大化输入和标签之间的互信息。详细证明请见附录。
4 Experiments
4.1 Datasets
五个基准文本分类数据集:SST-2;SUBJ;TREC;PC;CR。

4.2 Implementation Details
为了使输入格式适应bert家族预训练语言模型,对于每个输入句子,所有标签的名称列为标记序列,并将其插入输入句子之前,并用一个特殊的[SEP]标记进行分割。作者还在输入序列的前面插入一个特殊的[CLS]标记,并在输入序列的末尾附加一个[SEP]标记。
BERT和RoBERTa都使用位置嵌入来利用输入序列中标记的顺序,因此,如果类标签按固定的顺序列出,则类标签将与位置嵌入相关联。为了减轻标签顺序的影响,我们在训练阶段,在形成输入序列之前,随机改变标签的顺序。在测试阶段,标签顺序保持不变。
使用AdamW优化器来优化预训练的BERT-base-uncased和robert-base模型,权重衰减为0.01。训练该模型30个时代,并使用从 2 × 1 0 − 5 2×10^{−5} 2×10−5到 1 0 − 5 10^{−5} 10−5的线性学习率衰减。将所有层的dropout设置为0.1,将所有数据集的批处理大小设置为64。对于超参数,采用网格搜索策略,在 0.01 , 0.05 , 0.1 {0.01,0.05,0.1} 0.01,0.05,0.1中选择最佳的 λ λ λ。温度系数 τ τ τ被选为0.1。
4.3 Experimental Results
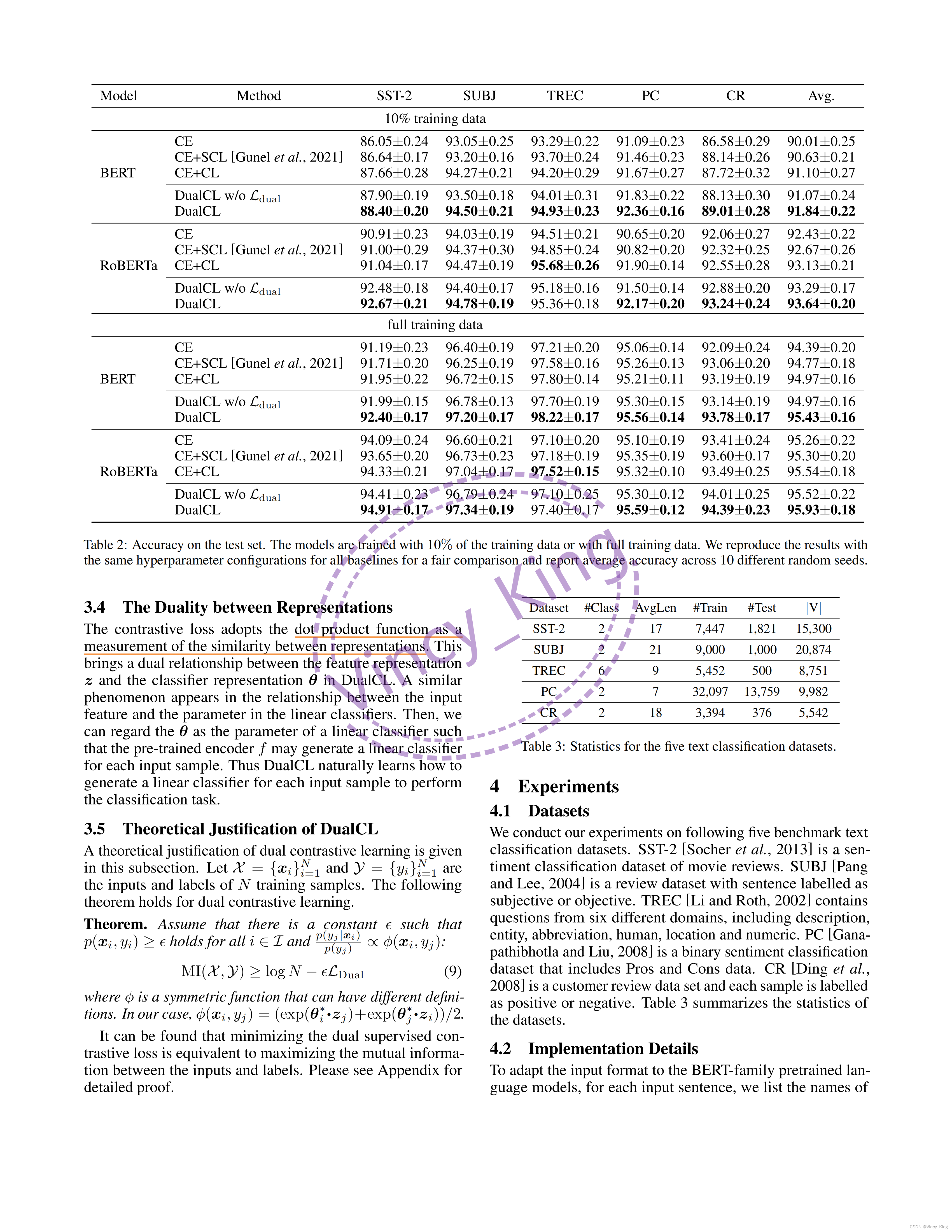
将DualCL与三个监督学习基线进行比较:使用交叉熵损失(CE)训练的模型,以及交叉熵损失和标准监督对比损失(CE+SCL),使用交叉熵损失和自我监督对比损失(CE+CL)。结果如表2所示。

- 从结果中可以看出,除了使用RoBERTa的TREC数据集外,同时使用BERT和RoBERTa编码器在几乎所有设置中都取得了最好的分类性能。与具有完整训练数据的CE+CL相比,DualCL在BERT和RoBERTa上的平均改善率分别为0.46%和0.39%。
- 此外,在10%的训练数据下,DualCL的性能明显大于CE+CL方法,在BERT和RoBERTa上分别高出0.74%和0.51%。同时,CE和CE+SCL的性能不能超过DualCL。这是因为CE方法忽略了样本与CE+SCL方法之间的关系,不能直接学习分类任务的分类器。
- dual对比损失项有助于模型在所有5个数据集上获得更好的性能。它表明,利用样本之间的关系有助于模型在对比学习中学习更好的表示。
4.4 Visualization
为了研究dual对比学习如何提高表征的质量,作者在SST-2测试集上绘制了学习的表征的tSNE图。使用RoBERTa作为编码器,并利用每个类的25个训练样本来微调编码器。图2中显示了CE、没有 L D u a l L_{Dual} LDual的DualCL和DualCL的结果。
在图2中,可以发现DualCL学习了输入样本和与每个样本关联的分类器的表示。将图2(b)和图2©进行比较,通过利用训练样本之间的关系和对模型施加额外的约束,双重对比损失有助于模型学习输入特征和分类器的更有区别性和鲁棒性的表示。

4.5 Effects in Low-Resource Scenarios
在DualCL中,它使用具有标签感知的输入表示作为输入样本的另一个视图。因此,作者推测,标签感知的数据增强应该适用于资源不足的场景。为了验证这一点,作者在低资源场景下对SST-2和SUBJ数据集进行了实验。使用每个类的N个训练样本来评估模型的性能,其中 N ∈ { 5 , 10 , 20 , 30 , 40 , 50 , 60 , 70 , 80 , 90 , 100 } N∈\{5,10,20,30,40,50,60,70,80,90,100\} N∈{5,10,20,30,40,50,60,70,80,90,100}。图3描绘了用CE训练的BERT,没有 L D u a l L_{Dual} LDual和DualCL训练的DualCL的结果。
在图3中,可以看到DualCL在简化的数据集上明显超过了CE方法。具体来说,SST2数据集的改进高达8.5%,而SUBJ数据集的改进高达5.4%,每个类只有5个训练样本。即使没有双对比损失,标签感知的数据增强也可以持续地提高模型在减少的数据集上的性能。

4.6 Case Study
为了验证DualCL是否能够捕获信息特征,作者计算了[CLS]标记的特征与句子中每个单词之间的注意得分。首先在整个训练集上调整RoBERTa编码器。然后计算特征之间的 l 2 l_2 l2距离,并可视化图4中的注意图。结果表明,在对情绪进行分类时,所捕获的特征是不同的。上面的例子来自SST-2数据集,可以看到本文模型更关注表达“积极”情绪的句子“predictably heart warming”。下面的例子来自CR数据集,可以看到该模型对表达“消极”情绪的句子更关注“小”。相反,CE方法没有集中于这些鉴别特征。结果表明,DualCL能够成功地处理句子中的信息性关键词。

5 Related Work
5.1 Text Classification
文本分类是将文本进行分类的典型任务,包括情绪分析、问答等。由于文本的非结构化性质,从文本中提取有用的信息可能会非常耗时和低效。随着深度学习的快速发展,神经网络方法已被广泛探索用于有效编码文本序列。然而,它们的能力受到计算瓶颈和长期依赖问题的限制。最近,基于变形器的大规模预训练语言模型(PLMs)已经成为文本建模的艺术。其中一些自回归PLMs,自动编码PLMs,如BERT,RoBERTa和 ALBERT。plm的惊人性能主要来自于用于预训练的大规模语料库中的广泛知识。
5.2 Contrastive Learning
尽管交叉熵在监督学习中具有最优性,但大量研究揭示了交叉熵损失的缺陷,例如,易受噪声标签的影响,边际差和弱的对抗性稳健性。受InfoNCE损失的启发,对比学习已被广泛用于无监督学习,以学习下游任务的良好通用表示。例如,[He等人,2020]利用一个动量编码器来维护一个查找字典来编码输入的示例。[Chenetal.,2020]使用数据增强作为正样本生成输入示例的多个视图,并将它们与数据集中的负样本进行比较。[Gaoetal.,2021]同样地退出每个句子两次,以生成正对。在监督场景中,[Khosla等人,2020]通过标签对训练示例进行聚类,以最大限度地提高同一类内训练示例表示的相似性,同时最小化不同类之间的相似性。[Gunel等人,2021]通过预先训练的语言模型将监督对比学习扩展到自然语言领域。[Lopez-Martinetal.,2022]使用精心设计良好的监督对比损失研究网络入侵检测问题。
6 Conclusion
本研究中从文本分类任务的角度,提出了一种双对比学习方法DualCL,来解决监督学习任务。在DualCL中,使用预先训练好的语言模型同时学习两种表示形式。一个是输入示例的discriminative feature,另一个是该示例的classifier。作者引入了具有标签感知的数据增强功能来生成输入样本的不同视图,其中包含特征和分类器。然后设计了一个dual对比损失,使分类器对输入特征有效。双重对比损失利用训练样本之间的监督信号来学习更好的表示。本文通过大量的实验验证了双重对比学习的有效性。DualCL在五个基准文本分类数据集上成功地实现了最先进的性能。本文还通过可视化学习表征来解释双重对比学习的机制。最后发现DualCL能够在低资源数据集中提高模型的性能。未来将对其他监督学习任务,如图像分类和图形分类中的双对比学习进行进一步的探索。
笔记展示























 1653
1653











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









