







论文标题
Contrastive Learning-Based Dual Dynamic GCN for SAR Image Scene Classification
论文作者、链接
作者:
Liu, Fang and Qian, Xiaoxue and Jiao, Licheng and Zhang, Xiangrong and Li, Lingling and Cui, Yuanhao
Introduction逻辑(论文动机&现有工作存在的问题)
合成孔径雷达(synthetic aperture radar,SAR)——对SAR数据的收集和分析,对SAR数据的无监督分类
用深度神经网络实现的SAR分类,主要分为两类:图片级和像素级——本文目标是解决图块级patch-level SAR图像场景分类问题
SAR数据的半监督学习——不仅要利用有/无标签的数据信息,也要实现结点之间的信息聚合,通过图卷积网络GCN实现
为了将GCN快速且高效的应用在SAR图片上,我们设计了基于注意力的结点特征表达以及不同结点之间的动态交互——首先,与高光谱图像不同,SAR图像每一个像素只对应一个灰度值,并且在像素空间中直接使用图卷积操作是不理想的——于是,更有效的操作是将SAR图像转换到嵌入空间中——利用自监督学习来学习内在的可转换的嵌入,来提高GCN效率——现有的对比学习都注重于不同数据增广下的数据的基本特征,却忽视了结构
后来,我们计算在嵌入空间中的结点和边——构建图块级的结点,会降低算法的计算复杂度——但是不同的图块可能属于不同的场景,一些可能是主要场景一些可能是干扰场景,特别存在于一些多重场景中——不区分这些场景会导致学到的特征区别度减弱,导致最后的分类结果变差——为了解决这个问题,我们设计了结点注意力模块,来自动的学习图块中的主要的场景,构建更具有区别度的结点——设计了一个动态相关性矩阵学习算法,来自适应的学习结点之间的边,学习空间邻居关系、非局部依赖特征、以及在预测的场景标签中的先验知识
GCN的半监督学习的表现会随着带标签数据的减少出现恶化——为了增强GCN的分类表现,我们构建了一个多尺度和多方向的全连接网络,将其加入动态GCN作为一个分支,添加后的GCN称为双路动态GCN(dual dynamic GCN ,DDGCN)——两个网络结构相同,参数共享,这样设计有三个好处:1)动态GCN保持了局部一致性和非局部依赖2)FCN的加入增强了不同场景的区分度3)参数共享减小了参数学习的复杂度
论文核心创新点
1.基于聚类的对比损失,用来捕捉视图和场景的结构
2.提出了动态GCN来保持局部一致性以及非局部的依赖,在动态相关性矩阵学习模块和结点注意力模块的帮助下
3.多重特征和参数共享双路网络框架
相关工作
对比自监督学习模型
图卷积网络
论文方法

基于聚类的自监督对比学习模型Clustering-Based Contrastive Self-Supervised Learning Model
对比自监督学习模型的目标是,针对不同的下游任务学习有用的特征,其中对比损失十分的重要。现有方法往往是通过减小相同样本的不同增广的距离来学习特征,忽略了场景结构,场景对SAR图像分类十分的重要。因此,我们添加了场景结构到对比学习的损失函数中,并且提出了基于聚类的自监督对比学习模型,如图2所示(感觉就是BYOL)
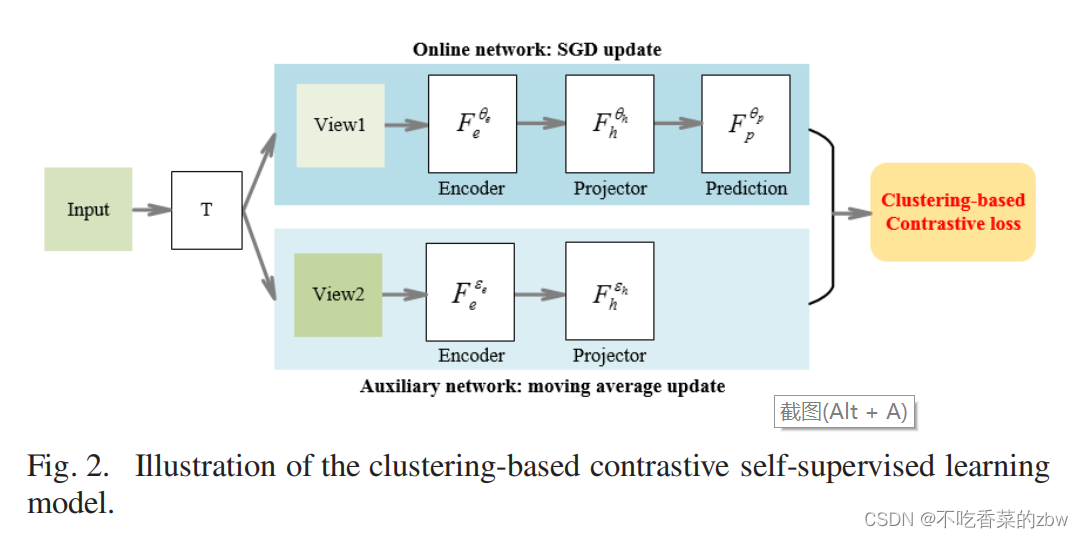
用表示尺寸为
的SAR图像。通过在
上使用滑动窗口来获得
个图块即
,其中滑动窗口的尺寸为
。与SimCRL和BYOL相似,使用三种数据增广策略将一个图块
转换成两个相关的视图
,包括随机剪裁、resize、随机旋转和随机高斯模糊,数据增广记为
。视图的生成过程记为:

然后,这两个视图被分别输入到在线网络和辅助网络中。在线网络由一个编码器和一个投影头组成。这两个网格的输出记为:

其中,表示神经网络,比如ResNet或者多层感知机MLP;
表示在线网络的参数,
表示辅助网络的参数。
在拿到网络的输出后,我们训练在线\辅助网络去预测辅助\在线网络的输出(交叉预测)。具体来说,在线网络的实际输出是辅助网络的目标输出,于此相反,
是在线网络的目标输出。此外,我们还添加了结构损失到目标函数中,该损失是用来减小相同场景的距离并且增大不同场景的差异性。新损失函数定义如下:

其中表示batchsize;
表示
正则化下的
的点乘操作;
代表相同的场景编号,
代表不同的场景编号,这个编号可以用不同的聚类算法在一个minibatch中区分;
是一个超参
损失函数的第一部分是用来学习视图的结构,第二部分是在聚类结果的指导下进行场景结构的捕获。损失函数的最终目标是,使得同一个图块的两个视图相近,属于同一个场景的图块相近,并且将不同场景的图块尽可能远离,于是网络就可以学习去区分并捕捉场景的基本特征。
为了使得损失函数对称,将输入到在线网络中计算
,
输入到辅助网络中去计算
,总的损失为
。与BYOL相似,在线网络的参数是使用随机梯度下降进行更新的,辅助网络的参数是根据在线网络的更新的参数进行动量更新的,这样会使得辅助网络的参数更新更为的平滑,不会出现琐碎解或是模型崩塌的情况。训练完成后,SAR图片会通过在线网络的编码器从像素映射到嵌入空间中
动态GCN Dynamic GCN
结点注意力模块Node Attention Module
直觉上来说,在图块级场景分类任务中,图块中的像素或是特征应该对分类任务结果的贡献是不同的。特别是在场景的边上,图块中的不同区域可能会属于不同的场景。为了在一个图块捕捉主要的场景的特征同时忽略掉干扰的场景,我们提出了结点注意力模块,该模块是基于自注意力机制,用来将一个局部的特征图块转换到一个结点嵌入向量。
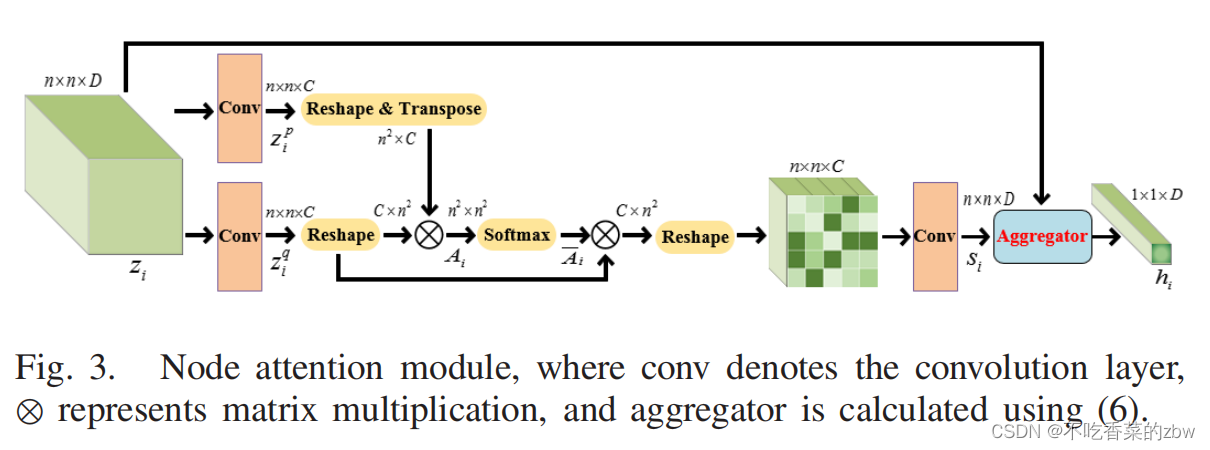
结点注意力模块如图三所示。代表图片
的嵌入特征,
是特征的维度。将
分成
个不相交的特征图块,尺寸为
,记作
,其中
以及
。
首先使用为卷积核的两层卷积层来将
转换到
和
,其中
代表输出通道数。然后,
会被reshape到尺寸
以及
,然后相乘得到
,最后用一层softmax对输出进行归一化,归一化结果为
。下一步,让
与
相乘,然后将结果reshape成尺寸
,后接一个
的卷积层生成注意力得分
。注意力得分的计算方式如下:

其中参考结点注意力网络,
为网络的参数。
计算注意力得分有两个目的。一方面,它可以减轻图块级分类方法所带来的影响。在分类后,我们设计了一个局部平滑策略,该策略基于注意力得分。特别地,我们计算每一个图块在不同类别下的权重之和,注意力得分用来当做权值。然后以得分最大的类别作为图块内所有像素的类别。另一方面,我们构建了一个特征聚合尺度,来计算基于注意力得分的结点嵌入向量,表示如下:

其中代表生成的结点嵌入向量,
代表
沿着特征维度的平均值,
表示逐个元素的乘法,
。通过整个动态结点注意力模块,我们可以得到
个结点,记为
动态相关矩阵学习算法Dynamic Correlation Matrix Learning Algorithm
我们将节点之间的关系称为相关性矩阵。不同类型的数据有不用的构建相关性矩阵的方法。在SAR图像中,我们根据场景间的相似性来构建边,不同场景的结点是没有边相连的。为了完全的捕捉结点间的相似性,基于从分类任务中挖掘出的先验知识以及对图像的特征的长距离的依赖,我们设计了动态相关性矩阵学习算法,去动态的学习优化结点之间的关系,这对结点之间的信息传递更具有指导意义。该算法有四步组成,如图4所示。

步骤1:基于空间邻接关系,计算初始的相关性矩阵。让
表示SAR图像中的所有的结点,其空间上相邻的节点可能属于同一场景。基于此先验知识,我们选择8个邻居结点去构建初始的相关性矩阵
。
步骤2:基于对场景的长距离依赖,学习一个由数据驱动的软相关性矩阵。除了相邻的结点可能属于同一个类以外,非邻居结点也可能属于同一个类。受到nonlocal network的启发,非局部依赖性可以被以下公式所捕获:
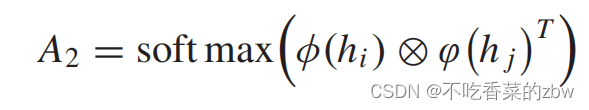
其中,代表两种不同的输入结点;
代表两种非线性的转换,以及
代表矩阵乘法。我们利用卷积网络去拟合
。我们使用一个带有
卷积核的卷积层
_layer去将
转换成
,一个带有
卷积核的卷积层
_layer去将
转换成
。然后
与
相乘,然后做一个归一化去生成尺寸为
的软相关性矩阵
步骤3:基于领域知识,计算一个相关性更新矩阵。构建相关性矩阵的目标是,链接同一个场景下的结点。因此,GCN的分类结果可以用来当做一种领域知识来优化相关性矩阵。我们将场景级语义标签关系的领域知识融入到相关矩阵学习中,设计了一种更新策略来增强同一场景内的节点关系,约束不同场景之间的节点关系。具体来说,那些在分类后置信度超过阈值的结点会被选择作为判别结点,剩下的则为未判别结点。在判别结点中,属于同一个场景的结点会被设为1,属于不同场景会被设为-1。非判别结点和判别姐结点的关系会被设为0,由此构建一个相关性更新矩阵
。
步骤4:将以上的初始相关性矩阵、数据驱动的软相关性矩阵、相关性更新矩阵结合起来,得到总的相关性矩阵,公式如下:

其中,是 两个超参
DDGCN and SAR Image Scene Classifification Algorithm
有了结点和边的学习模块,我们就可以应用GCN了。为了在有少量带标签的样本情况下,进一步对GCN的分类性能进行加速,我们设计了一个双路分支网络:一路是动态GCN,另一路是有多尺度、多方向的FCN。两路的网络结构相同,并且参数共享,整体结构如图1所示。基于聚类的对比自监督学习模型学到的特征,会被输入到动态GCN中。另一方面,考虑到SAR图像中各种土地覆被的尺度和方向差异较大,我们构建了多尺度、多方位的FCN,以更全面地获取土地覆被特征。我们计算了3个尺度、5个方向的人工设计的特征,作为FCN的输入,由此可以捕捉背景特征的层次性和多样性来描述不同的地形类型。

图5描述了多尺度和多方向的FCN输入。对于每一个像素,有3种尺度(小,中,大)和5种方向(左上,右上,中心,左下,右下)。这两个输入都先送入结点注意力模块,然后分别送入两个网络,两个输出则送入一个softmax分类器中。预测场景类标有两个目的,1)计算相关性更新矩阵,2)计算样本标签的分类损失。其余的如下算法所示。

消融实验设计
emmm比较复杂,建议看原文















 1280
1280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









