







 本文提出了一种双重对比学习(DualCL)框架,结合有监督学习和标签感知的数据增强,应用于文本多分类任务。在低资源环境下,这种方法能有效利用标签信息,提高分类精度。通过在多个文本分类数据集上的实验,DualCL显示出优于传统对比学习和交叉熵损失函数的表现,特别是在低资源设置中。
本文提出了一种双重对比学习(DualCL)框架,结合有监督学习和标签感知的数据增强,应用于文本多分类任务。在低资源环境下,这种方法能有效利用标签信息,提高分类精度。通过在多个文本分类数据集上的实验,DualCL显示出优于传统对比学习和交叉熵损失函数的表现,特别是在低资源设置中。
🍥关键词:对比学习、有监督学习、文本多分类、数据增强
🍥发表期刊:arXiv 2022
北航出了一篇比较有意思的文章,使用标签感知的数据增强方式,将对比学习放置在有监督的环境中 ,并将其运用到多类文本分类中,在低资源的环境中取得不错的效果。让我们来看看这篇论文
Abstract
对比学习在无监督环境下通过自我监督在表征学习中取得了显著的成功。然而,将对比学习有效地应用于监督学习任务仍然是实践中的一个挑战。在这项工作中,我们引入了一个双重对比学习(DualCL)框架,它同时学习输入样本的特征和分类器的参数。具体而言,DualCL将分类器的参数视为与不同标签相关联的增强样本,然后利用输入样本和增强样本之间的对比学习。对五个基准文本分类数据集及其低资源版本的实证研究表明,分类精度有所提高,并证实了学习DualCL的区分表示的能力
一、Introduction
传统的对比学习一直使用在无监督的环境中,具体来说,无监督的对比学习主要使用了一个损失函数,这可以使得同一个例子的的不同观点表示相近,而不同例子的表示不同。最近,对比学习被证明可以有效的同时实现alignment和uniformity
在有监督的环境中,虽然已经有人进行了研究,但是成果颇微,已有的成果其分类器和特征是分开学习。因此本篇论文希望在有监督的环境中开发一种更加自然的对比学习方法,每获得一个样本x后,它可以同时学到该样本的特征表示和分类器
(本文设计了一种one example分类)
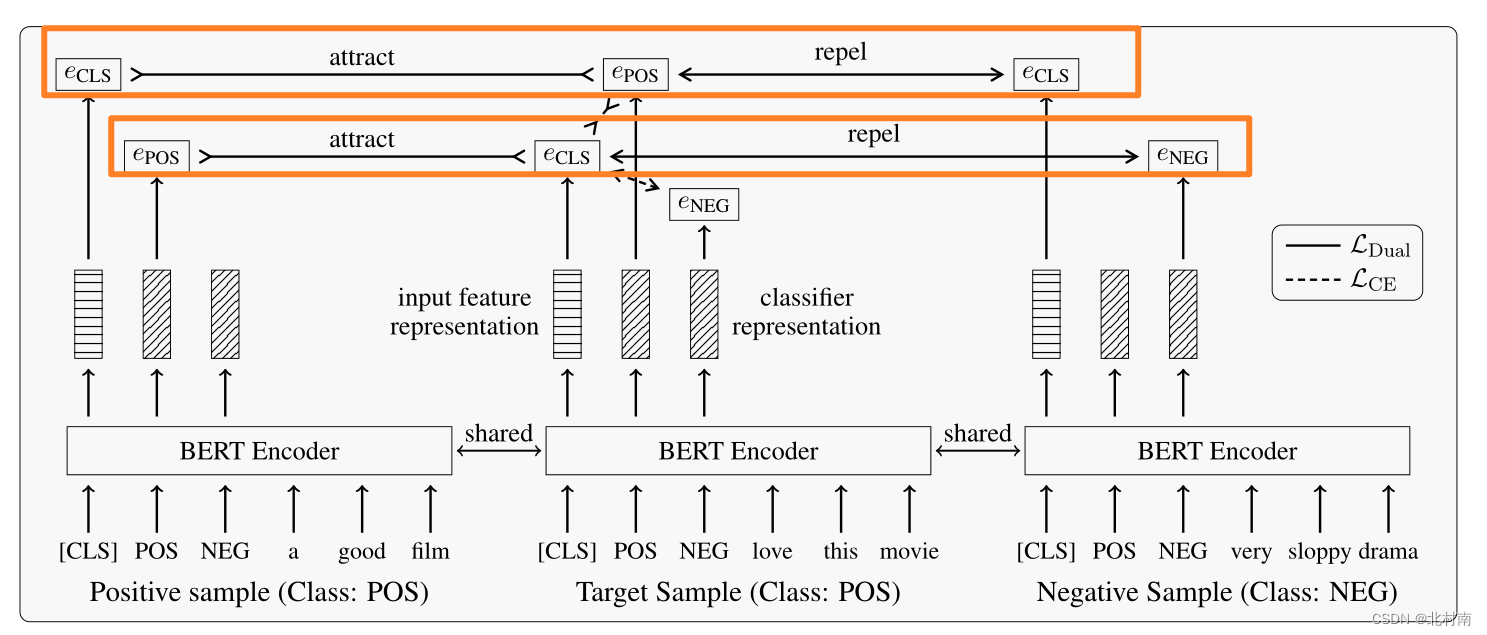
θ设计的比较有意思,它不仅仅是分类器,也是标签感知的数据增强样本集,随后作者对表征和分类器对比学习,直观的描述如图所示
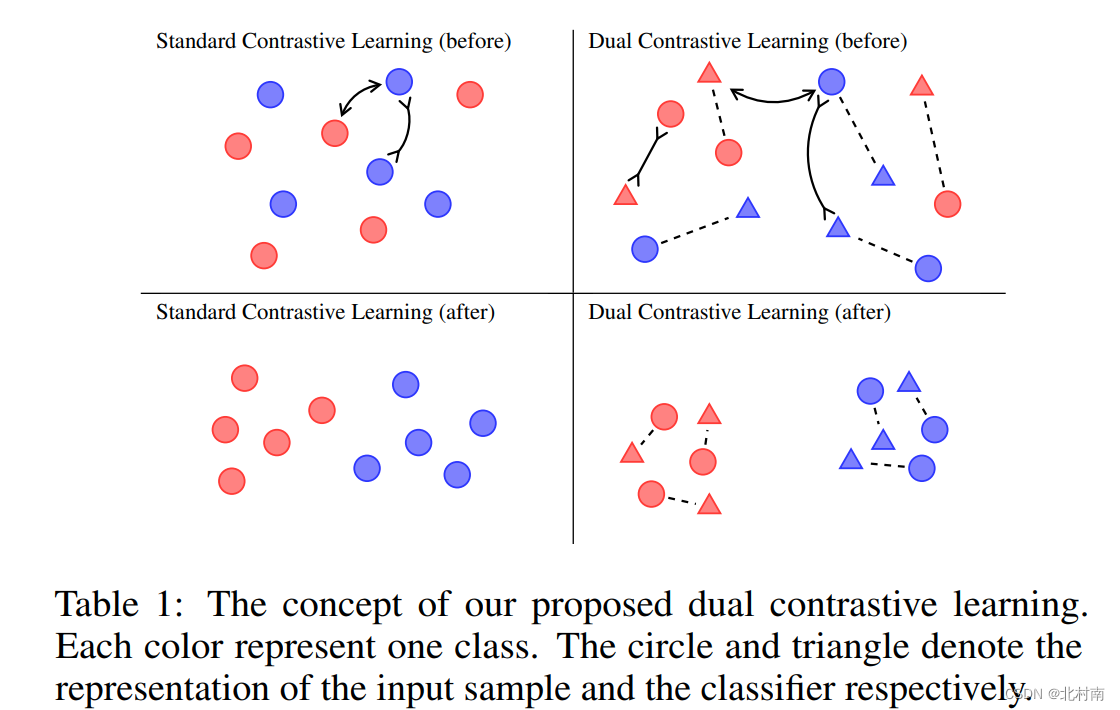
可以明显的看到标准对比学习不能利用标签信息,而DualCL可以有效利用标签信息对文本进行分类
总体来说,文本的主要内容如下
- 提出了Dual Contrastive Learning(DualCL),更自然的运用在有监督环境中
- 引入了标签感知的数据增强方式来获得样本的多个视图
- 在5个全资源和低资源版本的的文本分类数据集上验证了DualCL的有效性
二、Preliminaries
考虑一个具有K类的文本分类任务,假设给定的数据集包含了N个样本,是由L个单词组成的输入句子,对应的标签为
。
为
的标准化表示,
为第i个样本的增强样本,A为负样本集合。标准的对比学习任务正负样本的的构造方式为每个样本只有一个增强样本,其余的N-2项都是负样本,其对比损失函数如下
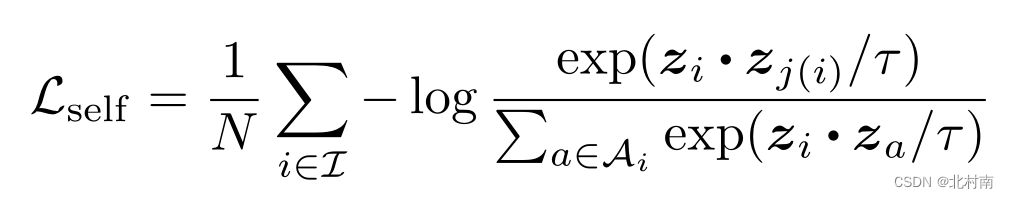
从损失函数角度看,要使Loss最小化,即最大化log后面的项,即最大化分子和最小化分母,直观的讲,分子分母项分别为样本与正、负样本之间的相似性,即拉进正样本,推远负样本。
随后有改进版的对比学习,其构造正负样本的方式为将同一类别的样本视为正样本,不同类的样本视为负样本,P为正样本集合,其损失函数如下
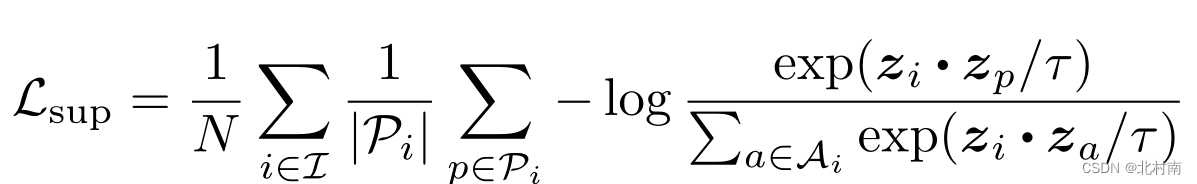
三、Dual Contrastive Learning
3.1 Label-Aware Data Augmention
本论文使用了标签感知的数据增强方式来获取训练样本的不同视图,具体做法是将标签与文本整合输入到Bert Encoder中(将标签输入到Bert中2021年有一篇论文也有这样的做法Fusing label Embedding into BERT An Efficient Improvement for Text Classification),随后会获得整个文本的特征表示即[CLS]和每个标签输出的token,假设输入有K个标签,那么输出的标签集合即分类器,对于包含多个单词的标签,采用token特征特征的平均池化方法。因为每个标签token都融合了文本信息,所以
的每一列
都是增强样本,每个样本都获得了K+1个视图
3.2 Dual Learning Loss
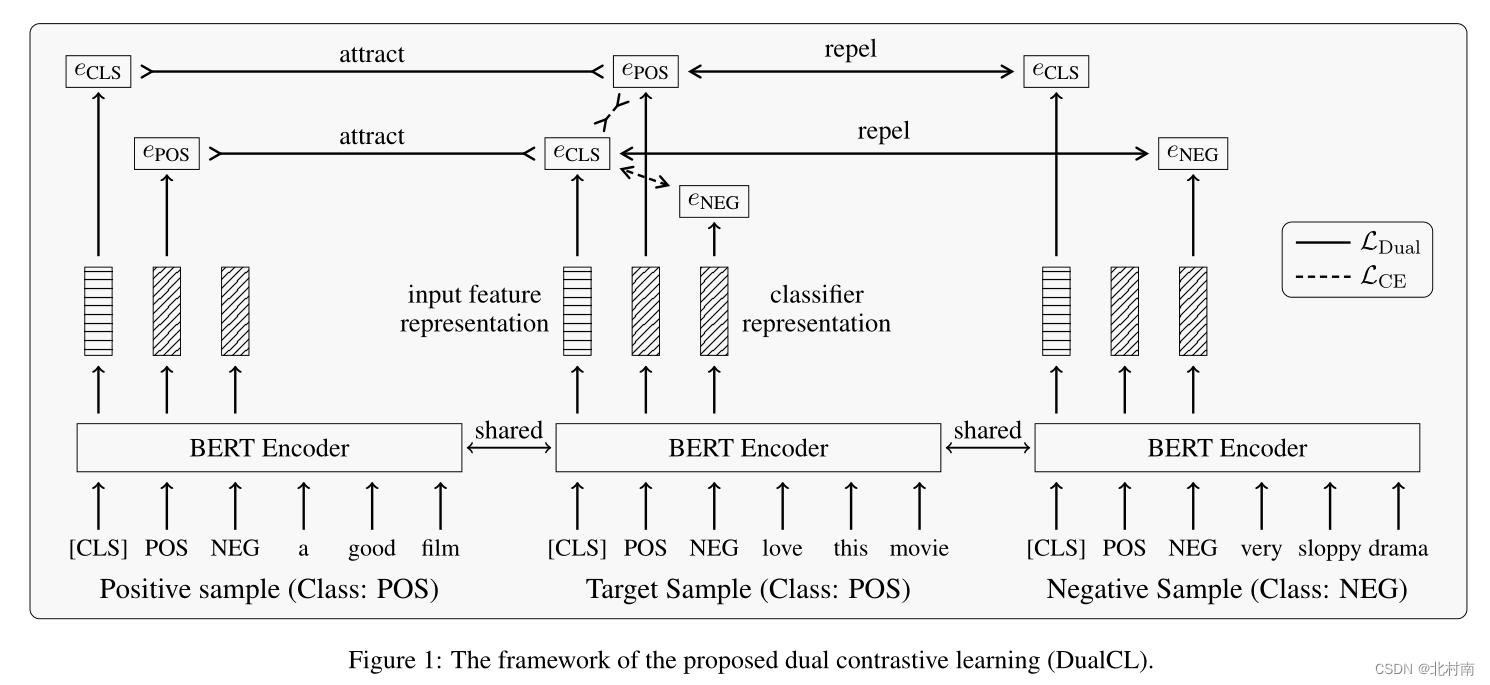
在获得了样本的多个视图之后,就可以使用这些视图来进行对比学习。对偶对比学习主要设计了两个对比损失函数,两个对比为下图中的两个橙色框。eCLS为该样本的特征表示,ePOS和eNEG为该样本的标签token。该对比学习的正负样本设计思想为,确定一个样本的文本序列,若其真实标签为POS,则所有其他样本的ePOS为正样本,而非ePOS为负样本。此外,确定一个样本真实标签ePOS,所有POS样本的CLS为正样本,非POS样本的CLS为负样本
设表示
的ground-truth对应的标签,A为除去当前样本的所有其他样本集合,P为正样本集合,
为样本表征。
以上图中上位置的橙色框为例,固定标签,定义以下的对比损失
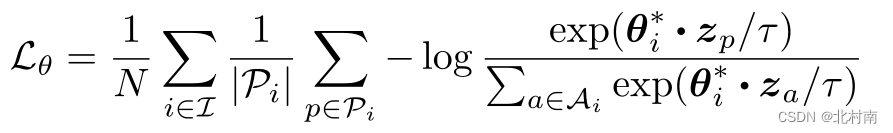
以上图中下位置的橙色框为例,固定表征,定义以下的对比损失
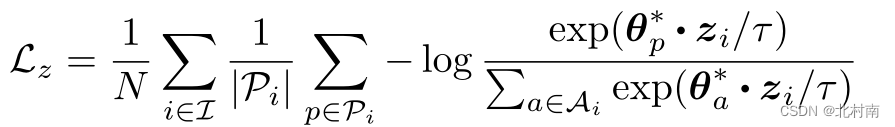
Dual的损失为将二者组合
![]()
3.3 Joint Training & Prediction
在训练上,作者使用了一个改进版的交叉熵
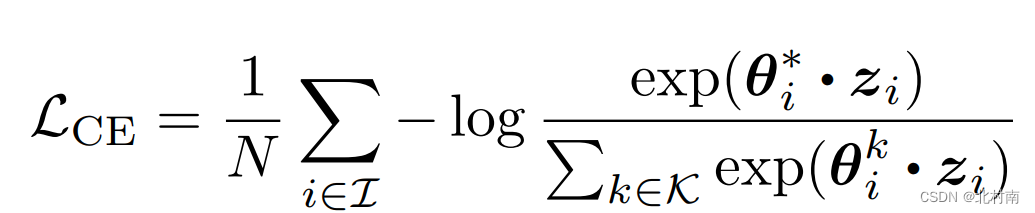
最终的损失函数为交叉熵加上与超参数λ调节的对比损失函数
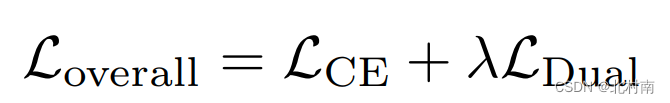
直观的表示如下图所示

在分类方面,作者想更好的利用监督信息,因此设计了one-example分类器,对每一个样本,它都会生成标签token集合,而这token集合就是分类器,将表征与每一个标签token进行相似度计算,哪个值最高,它就属于哪一类
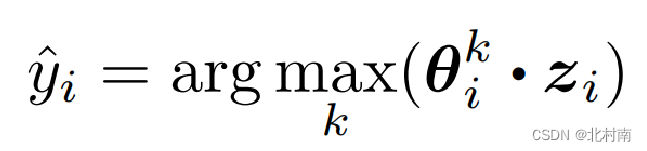
3.4 Theoretical Justification of DualCL
这里给出理论证明,来证明为最小化DualCL Loss等价于最大化输入和标签之间的户信息
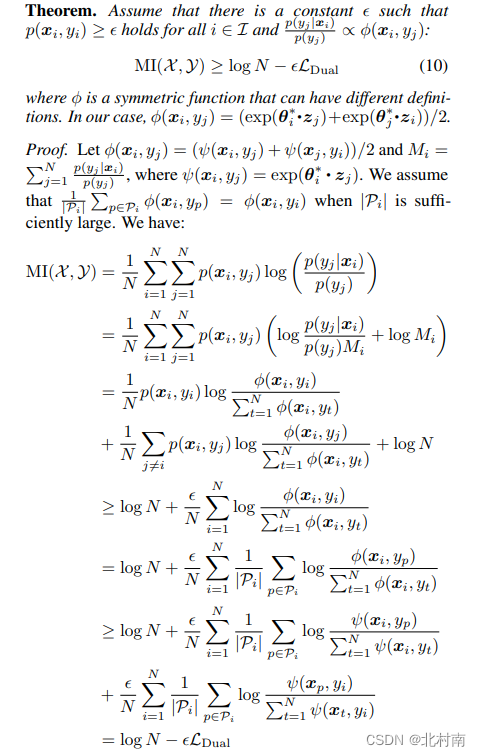
四、Experiments
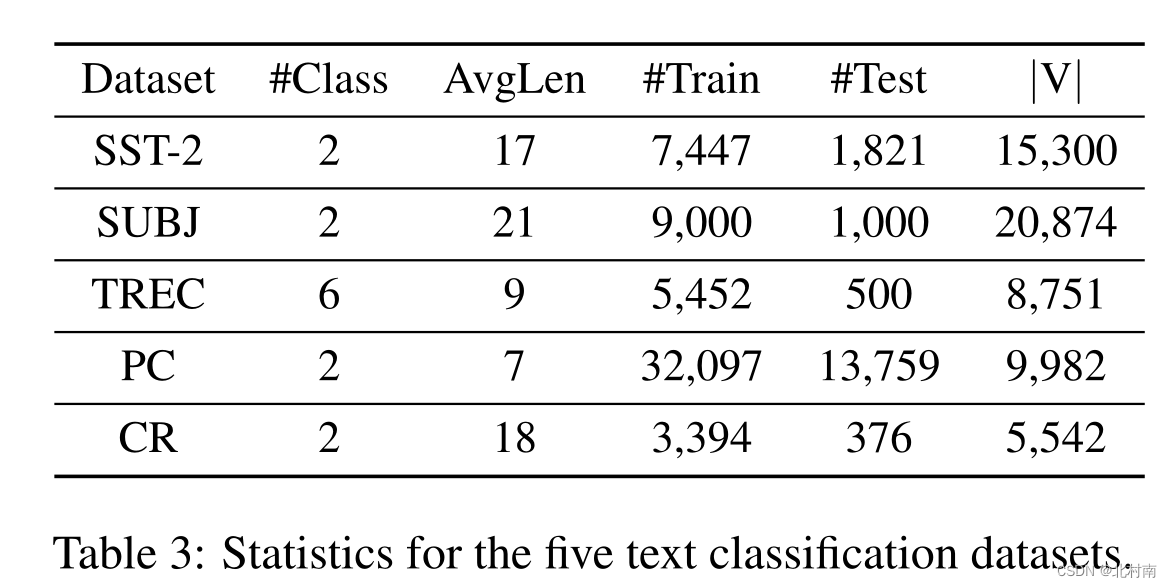
使用了5个文本数据集,包括了多分类文本数据集
模型选了经典的BERT和RoBERTa,方式中CE为交叉熵,SCL为标准对比损失,CL为自监督对比损失,Dual w/o 为不使用损失函数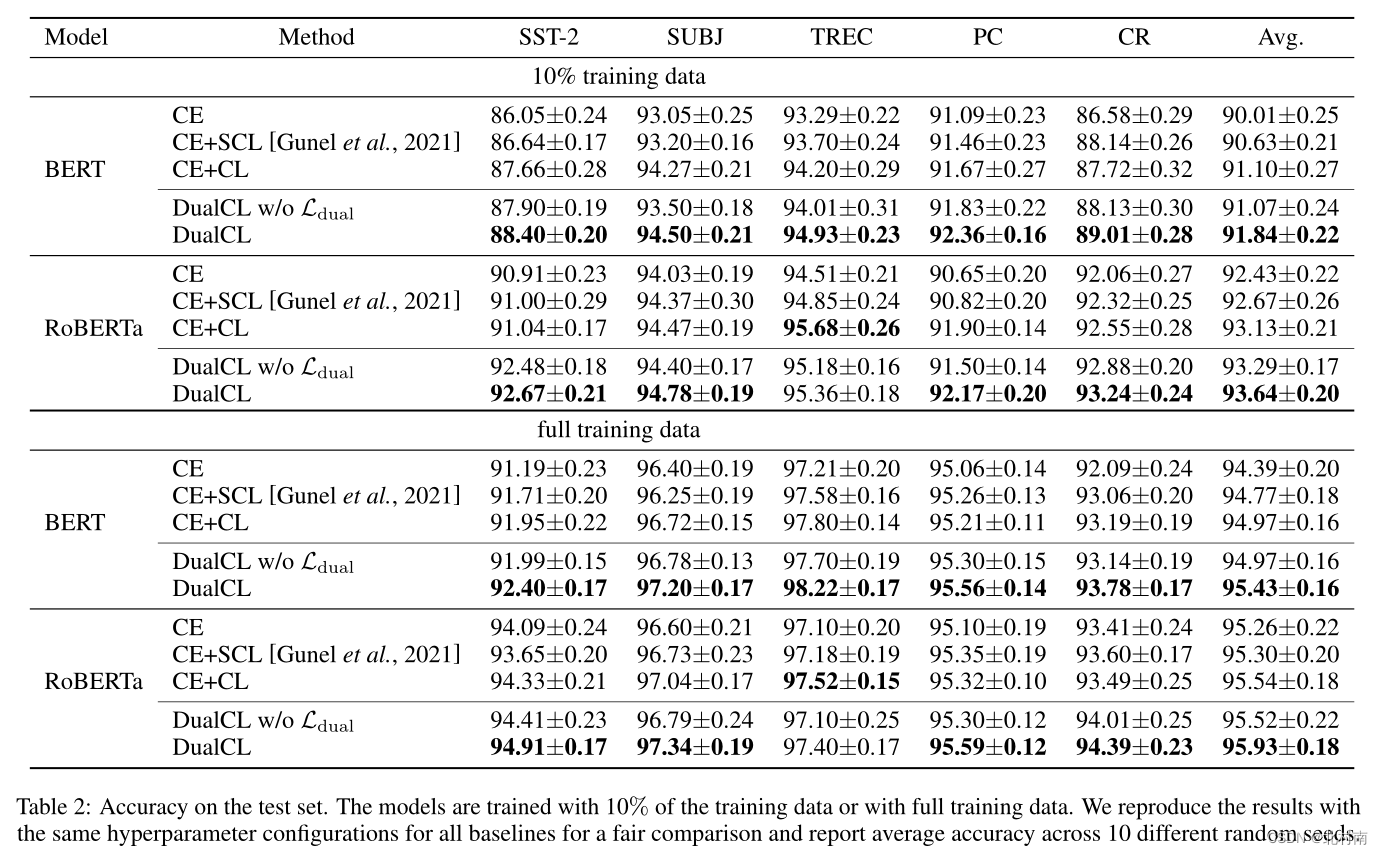
实验结果上
- 除了RoBERTa +(CE+CL)的组合在TREC数据集上效果较好之外,其他的Bert+DualCL组合在所有数据集上的表现效果最好。
- 具体来说DualCL在BERT和RoBERTa上的平均改善率分别为0.46%和0.39%
- 眼前一亮的是DualCL在低资源环境中取得了不错的效果,具体来说在BERT和RoBERTa上的平均改善率分别为0.74%和0.51%
tSNE图可视化

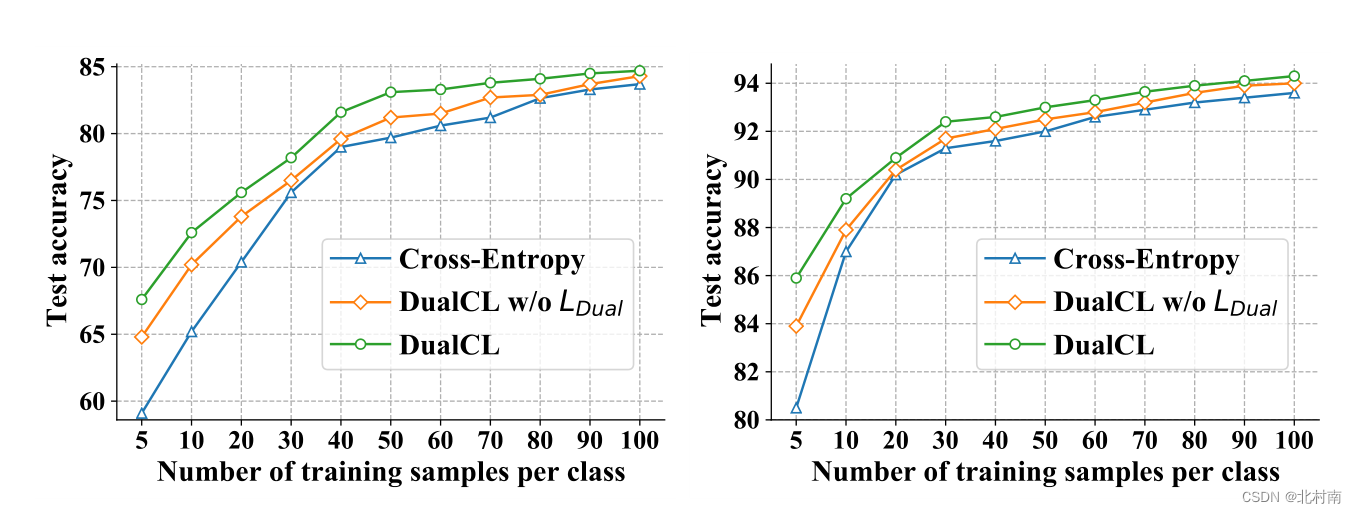
由于在低资源中的表现较为突出,作者专门去做了低资源环境下的实验,选取每个类的5、10、30等样本,测试其准确率,结果发现相比于单一的交叉熵损失函数,DualCL的效果都比较好,而其中DualCL w/o为不适用DualCL损失函数的DualCL,其效果也比交叉熵好,这其实从一个侧面角度反映了标签感知的数据增强方式的有效性
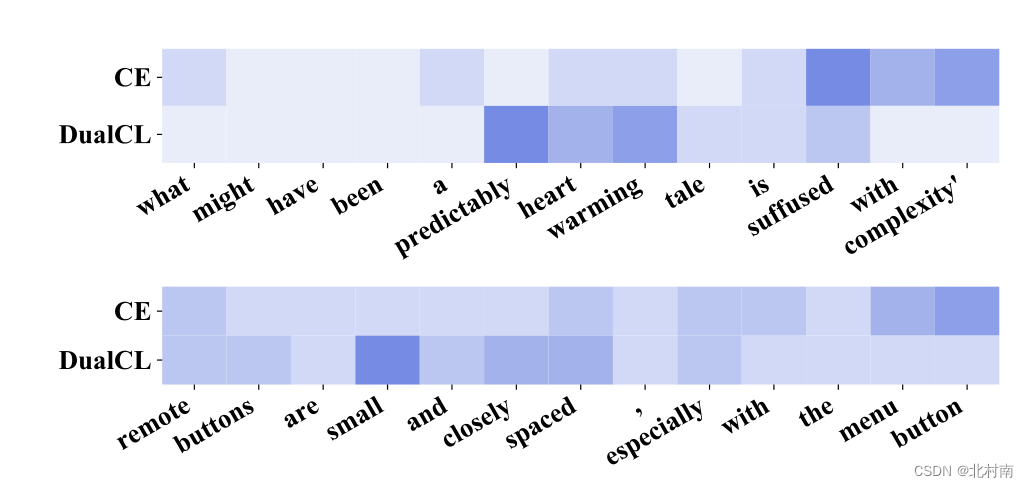
为了验证DualCL能否有效的捕获句子关键信息的能力,作者计算了[CLS]的中的表征于每个单词之间的注意力得分。
五、Conclusion
对比学习一般用于无监督的环境中,若用在有监督的环境中那必须使用标签信息,随后使用标签感知的数据增强方式来有效的利用标签信息。最终在低资源的文本分类任务中取得了不错的效果。因此在低资源、多类文本分类、有监督环境中具有一定的借鉴意义



















 1327
1327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











