







什么是贝尔曼方程
贝尔曼方程最早应用于工程控制理论,又称为动态规划方程,具体可以多查资料多角度理解。在强化学习中,贝尔曼方程描述的是不同状态的状态价值的关系,这些关系有很多,所以实际表现为贝尔曼方程组。
- 状态价值 State Value
某个状态出发,采用某个策略,得到的奖励回报的期望称为状态价值,用于评价一个策略的好坏。
为什么要用贝尔曼方程
- Step 1:策略评价Policy Evaluation
强化学习目标是找到智能体的最优策略,有比较才有最优,如何比较,用状态价值来评价策略的优劣。通过状态价值的定义可以构建出贝尔曼方程组,通过求解方程组可以的到当前策略下不同状态的价值。通过比较状态价值,衡量策略优劣。 - Step 2:策略的优化
评价一个策略得到它的值,基于值改进策略然后循环下去,最后就能得到一个最优的策略,完成强化学习的目标。
贝尔曼方程的形式
-
折扣回报的数学表达
折扣回报表示为Gt,是所有瞬时回报(采取一个动作马上就能获得的回报)与折扣因子乘积相加。
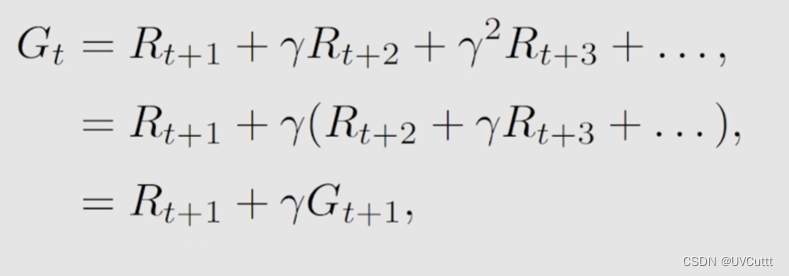
-
状态价值的数学表达
状态价值表示为Vπ(s), 是折扣回报Gt的期望值。
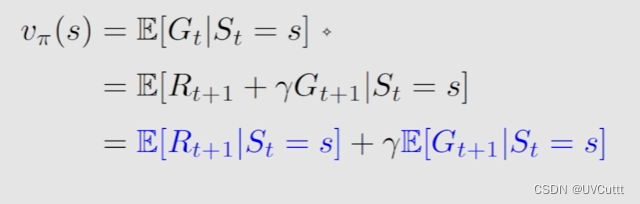
-
瞬时奖励期望值
其中蓝色字体的前半部分为当前状态下获得瞬时奖励的期望值,那其实程序员的角度理解这个公式,两层循环,外层遍历当前状态下所有动作的概率π(a|s),内层遍历当前状态下采用外层遍历到的动作获得奖励r的概率p(r|s, a),最后再加,那其实就是瞬时奖励的期望值,很好理解。

理解时间:当前我站在马路上,只能前后走
前后走的概率为:[0.6, 0.4]
单个方向上获得奖励的可能有:
前 [1, 2, 3, 4],概率[0.1, 0.2, 0.3, 0.4]
后 [4, 3, 2, 1],概率[0.4, 0.3, 0.2, 0.1]
那么我获得瞬时奖励的期望的计算过程为:
0.6 x (1x 0.1 + 2 x 0.2 + 3 x 0.3 + 4 x 0.4) + 0.4 x (4 x 0.4 + 3 x 0.3 + 2 x 0.2 + 1 x 0.1) = 1.8 + 1.2 = 3 -
未来奖励期望值
蓝色字体的后半部分为当前状态S出发到下一个时刻的期望回报,下一个时刻可能的状态有很多,为S`的概率为p(S`|S),同样为两层循环,外层循环为下一个状态为S`的 状态价值Vπ(S`),内层循环计算S到S`的概率(有很多动作,不同的动作都有可能到达S`的可能,所以你看到了这样的公式),最后再相加,即为未来奖励的期望。

-
总结
瞬时奖励期望值 + 折扣因子 * 未来奖励期望值 = 当前的状态价值。
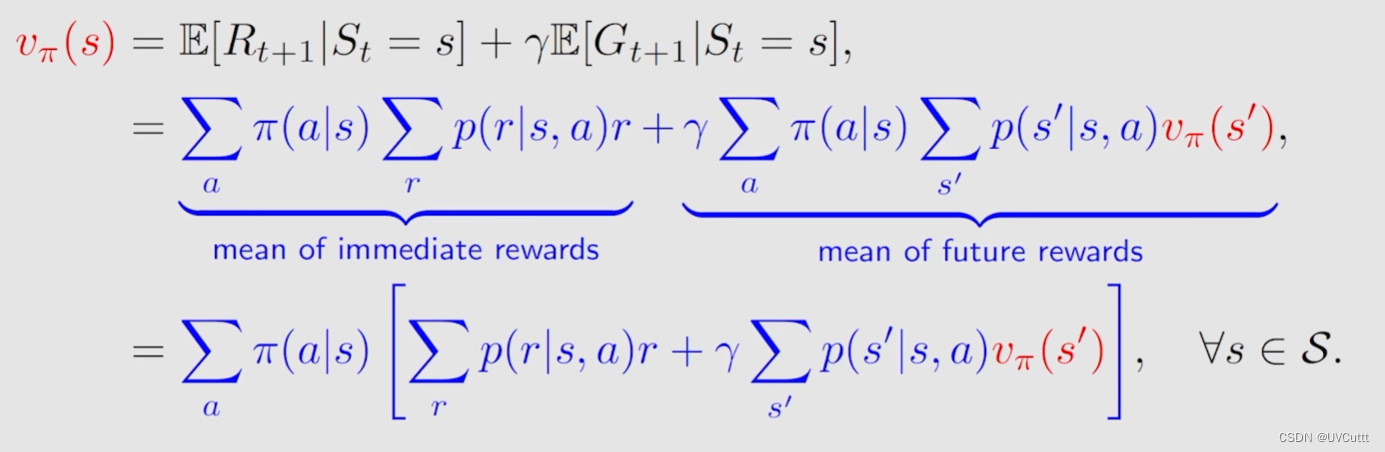
贝尔曼方程的矩阵形式
改写下方程,可以自己写写,体验过程,最终形式还是很好理解的。
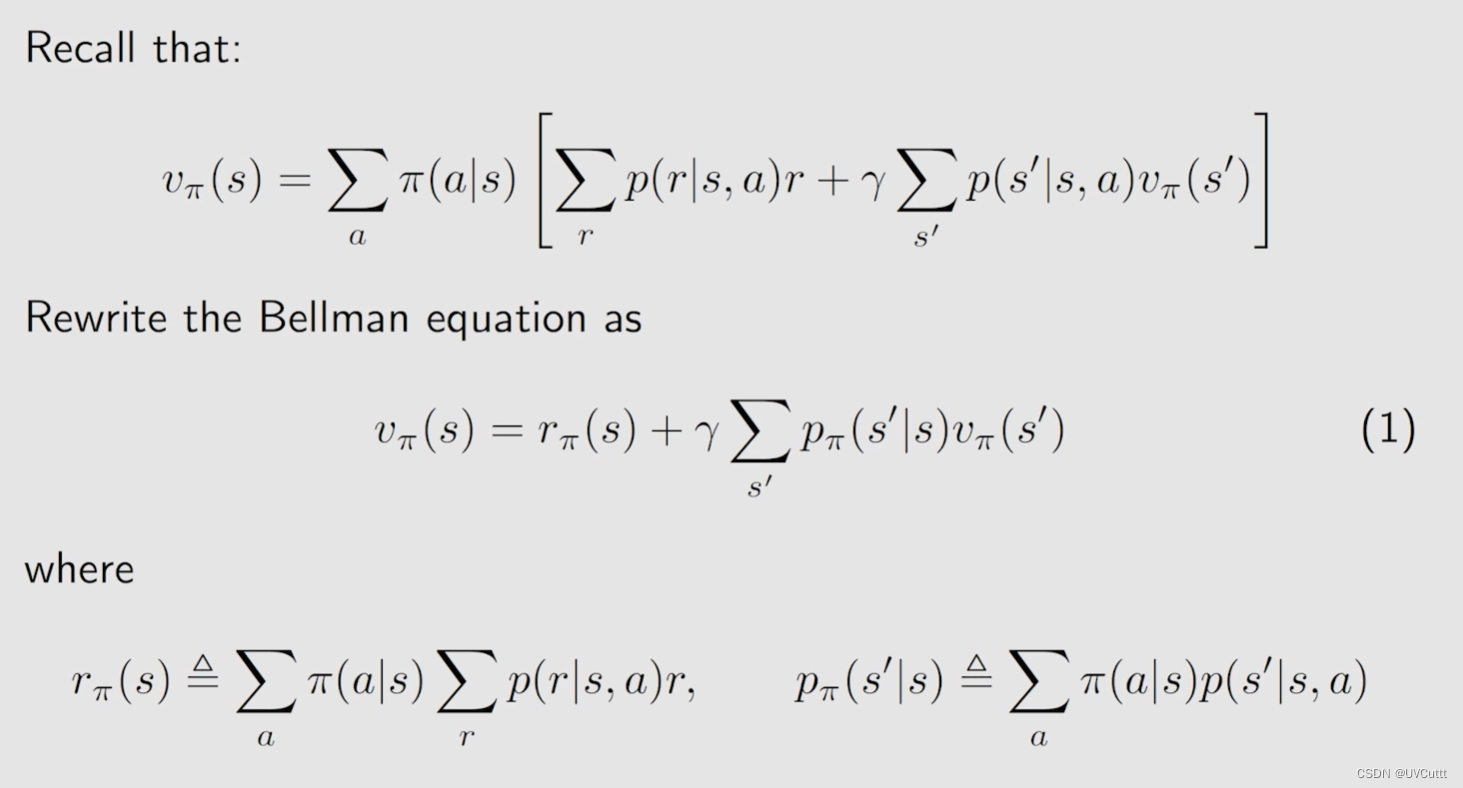
最终的矩阵形式为,书写简洁,求解方便。


- 求解的两种方式
解析解和迭代法
解析解需要计算矩阵的逆,计算量大。
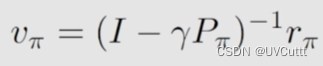
迭代法,实际编程就是这样写的,写个循环,逐步迭代。
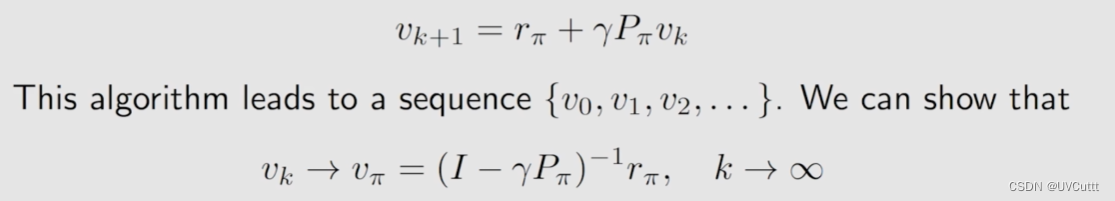
动作价值 Action Value
上面利用了贝尔曼方程组求解了状态价值,比较其与动作价值的定义。
- 状态价值:从一个状态出发,得到的期望回报。
- 动作价值:从一个状态出发,采取一个动作所得到的的期望回报。
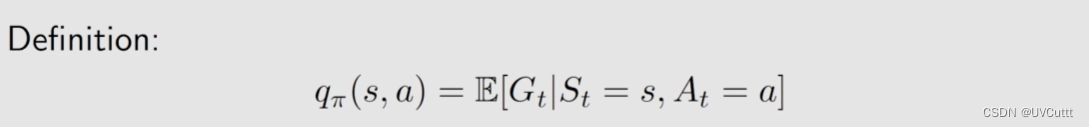
从公式观察相较于状态价值其实就是多了个条件,求动作价值的意义在于选取价值最高的动作。

上面的表达式对比下面贝尔曼方程
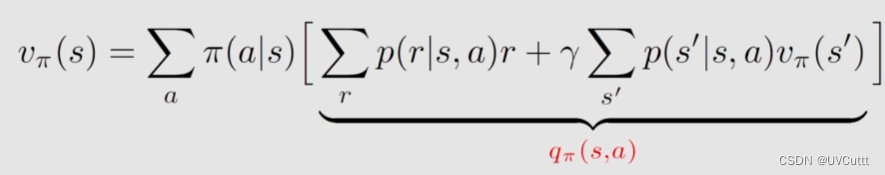
其实可以得到
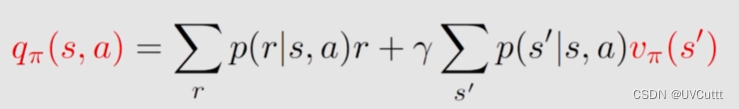
两者之间可以互相求解。
总结
















 61
61

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









