







强化学习第七章:时序差分方法
什么是时序差分方法(Temporal Difference Learning, TDL)
三种方法的比较
- 值迭代和策略迭代算法
可以 边交互边学习 ,学习速度快,但是 需要环境模型 。 - 蒙特卡洛方法
从 经验 (交互结果)中采样学习,学习速度慢(需等Episode完成), 不需要环境模型 。 - 时序差分方法
不需要 环境模型,能 边交互边学习。MakaBaka想了想RM算法的迭代求解过程,点点了点头。
时序差分方法
- 时序差分方法的思想
基于 已得到 的 其他状态 的估计值来 更新当前状态 的价值函数,对于单步TD来说,在采样的时候,用相邻下一时刻状态估计值更新当前的价值函数,两者的时刻差为1,所以被称为时序差分方法。 - 时序差分方法的分类
时序差分方法是一大类强化学习方法,最经典的是用于 估计状态价值 的方法,除此以外还有 估计状态动作价值 的方法及其变种等方法。
从RM算法到时序差分方法
原始的RM算法
考虑求解单个未知分布随机变量期望的问题
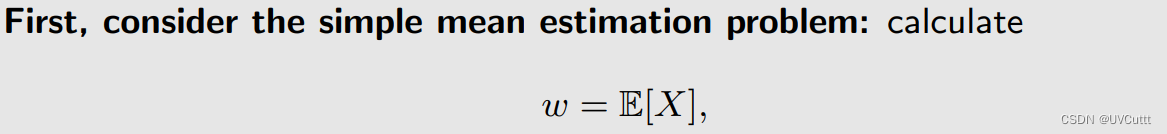
原始问题转化为求根问题
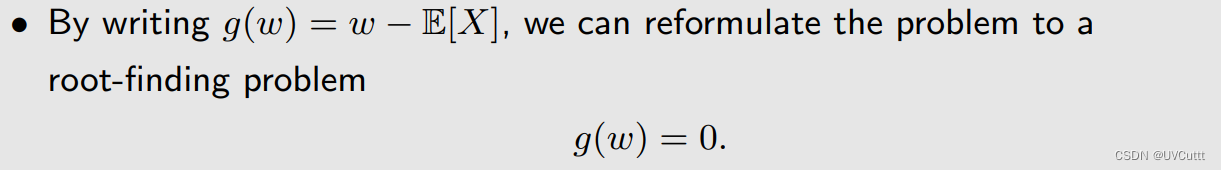
找到RM算法的迭代方向,以随机变量的采样为基础
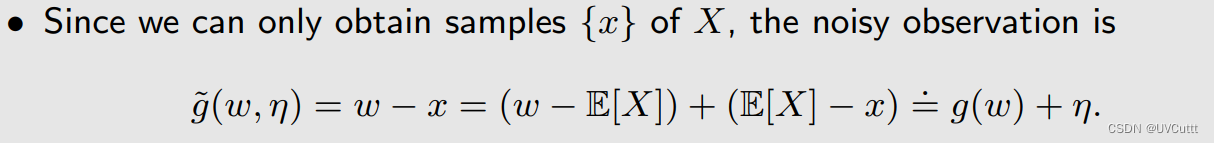
最后得到上述求根问题的迭代求解式:
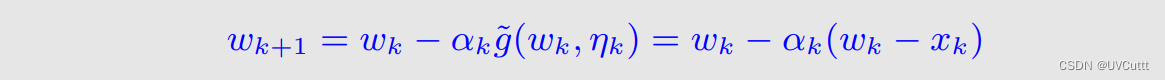
更加复杂的RM算法
从求解单个未知分布随机变量期望的问题变成了多个,但不改变RM框架
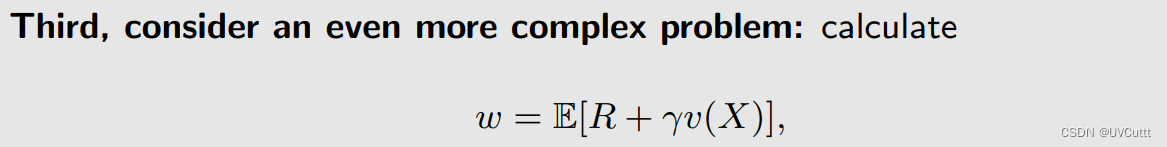
还是将原始问题转化为求根问题,并找到其迭代方向

得到迭代式
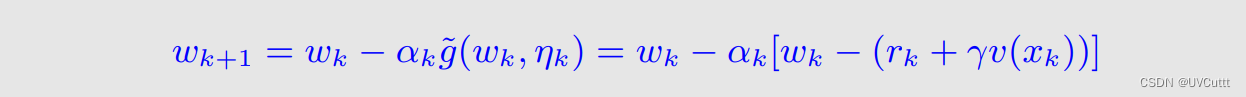
TD算法的形式
需要由给定策略形成的经验
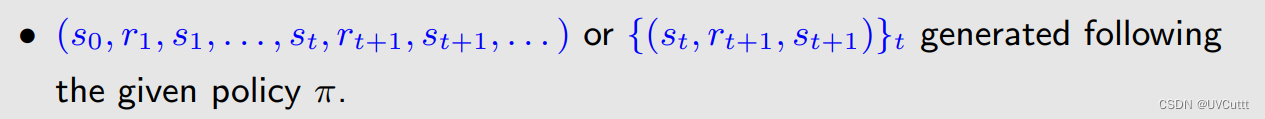
单步TD求解状态价值的具体形式如下:

vt(st): t时刻访问到的状态 的 状态价值 在 t时刻 的 估计
vt(st+1): t+1时刻访问到的状态 的 状态价值 在 t时刻 的 估计
at(st): t时刻访问到的状态 的 折扣因子 在 t时刻 的 值
- TD Target和TD Error
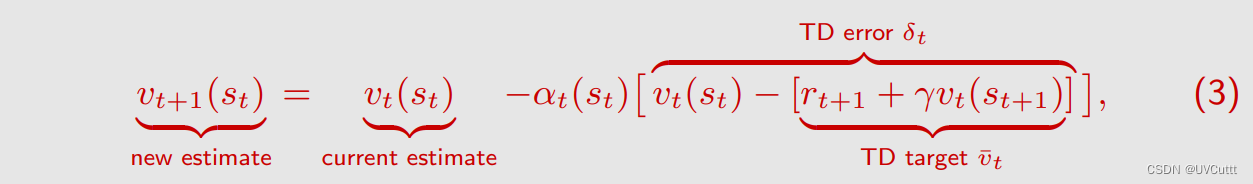
TD算法的理解
对于访问到状态来说,真实的状态价值是vπ(st),回顾状态价值的贝尔曼方程
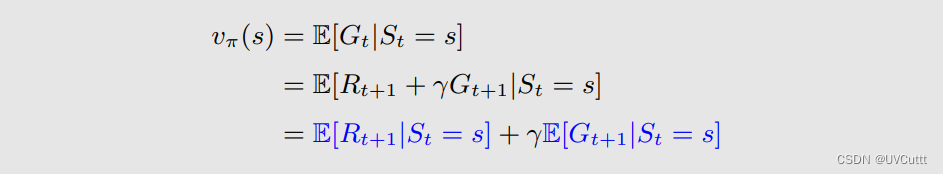
其中Gt+1即为下一个状态的 状态价值的期望 ,那么可以改写为:

这个公式能朝着TD Target前进吗,也就说 vt+1(st) 会比 vt(st) 更接近与t时刻的目标值吗?
等式两边同时减去一个TD Target
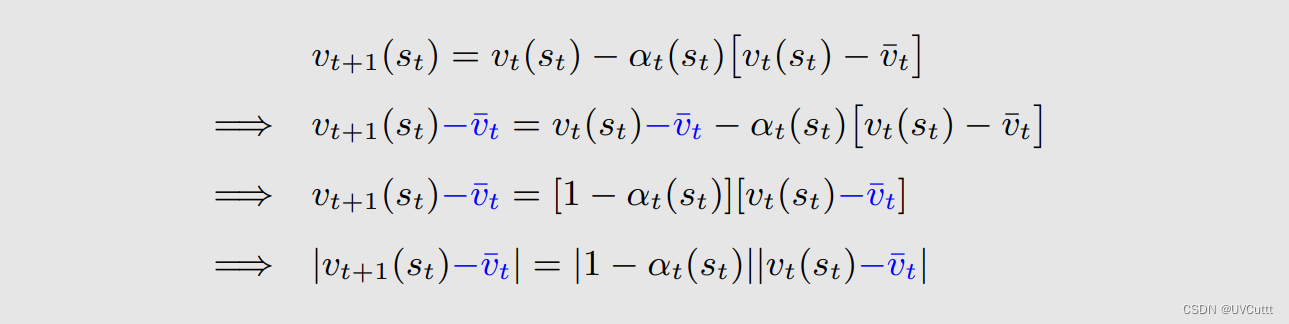
其中
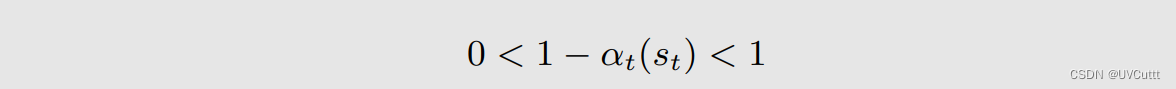
所以
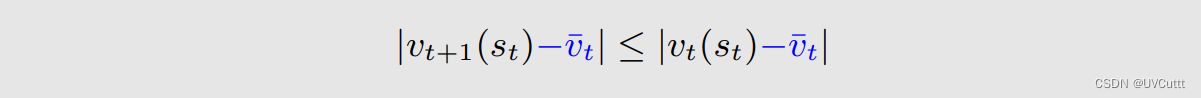
要从经验中改进当前访问到的状态的状态价值的估计,本来 没有环境模型 ,我是不知道st+1和rt+1的,但是我现在知道了, 利用 这个 信息 来 改进 ,如何改进,迭代朝着访问到的状态的真实状态价值前进,每次迭代都会访问到一个状态,同时 只改进它自己 ,没访问到的不变。随着迭代不断利用经验,所有的状态价值的近似都会 朝着真实状态价值收敛 。
- TD算法的数学本质
上面的手写公式中改写了贝尔曼公式,实际上改写之后的为贝尔曼期望公式
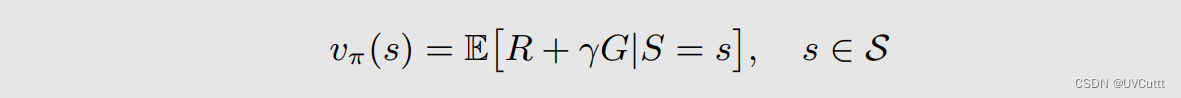
G是折扣奖励,那主观也很好理解,下一个状态的 状态价值的期望
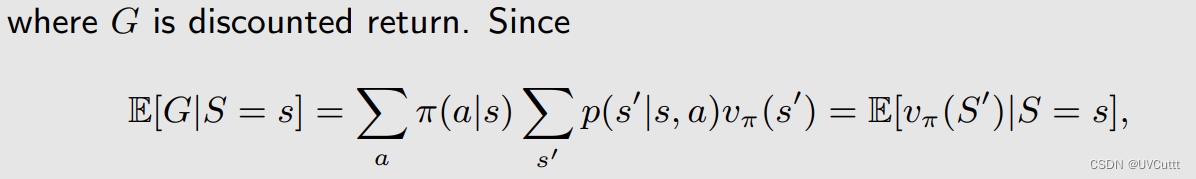
最终,TD算法是要在没有环境模型的情况下求解贝尔曼期望公式
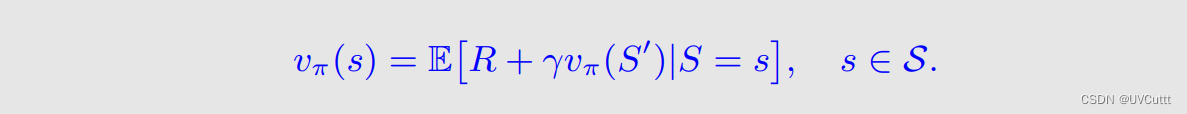
TD算法和RM算法的联系
TD算法是求解贝尔曼期望公式的一个RM算法。
求解给定策略下贝尔曼期望公式转换为RM算法框架中的求根问题
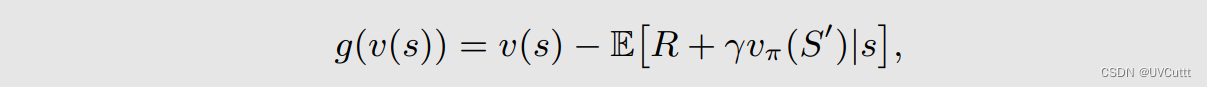
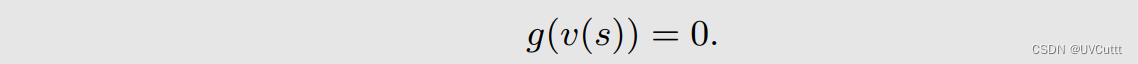
根据采样找到RM算法的迭代方向
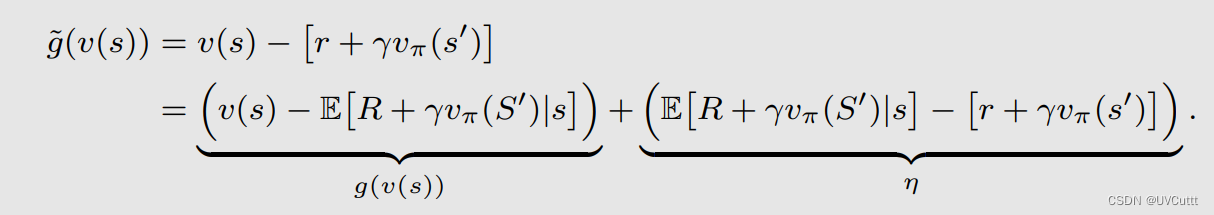
得到迭代式
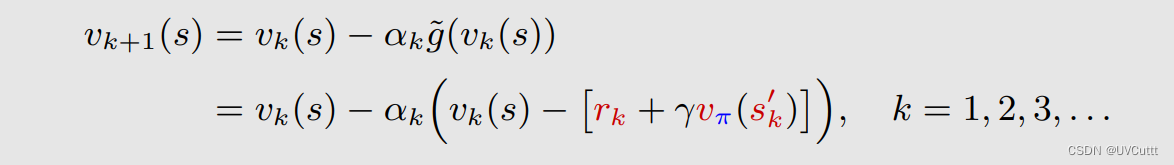
再回顾TD算法的最终形式
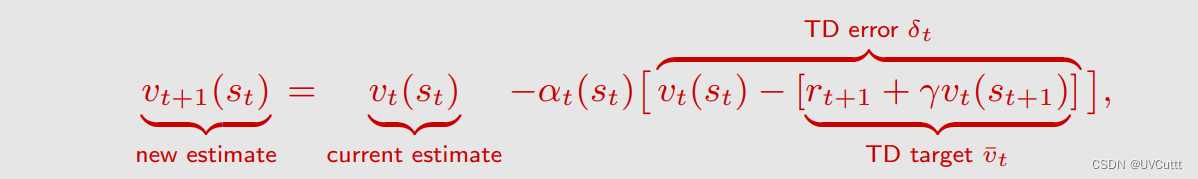
如果要将贝尔曼期望公式的RM算法迭代式改为TD算法中的形式,需要变更两个小点:
奖励和状态的采样直接换为时间序列上的样本,再这个时间序列上, 更新访问到状态 的状态价值。
直接将状态价值的估计值替换为真实状态价值,虽然 现在不是准确 的,但随着 经验 的不断 利用 ,会越来越 准确 。
这样修改之后的RM算法迭代式,也就是TD算法的最终形式能收敛吗,能

值得注意的点就是实际中,不会将学习率at趋向于0,只是设置到一个很小的数,让经验持续有效。
TDL和MCL
两者都是无模型的。
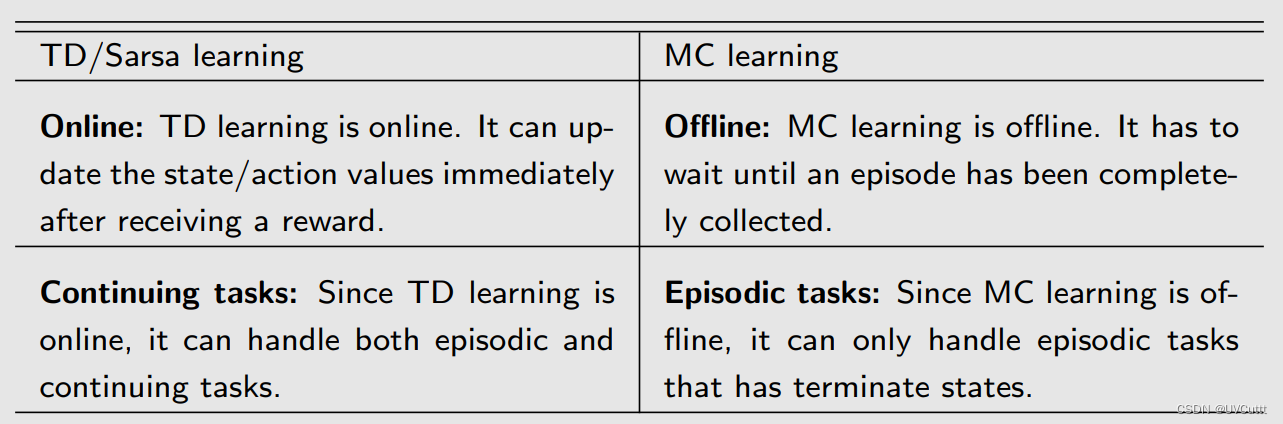
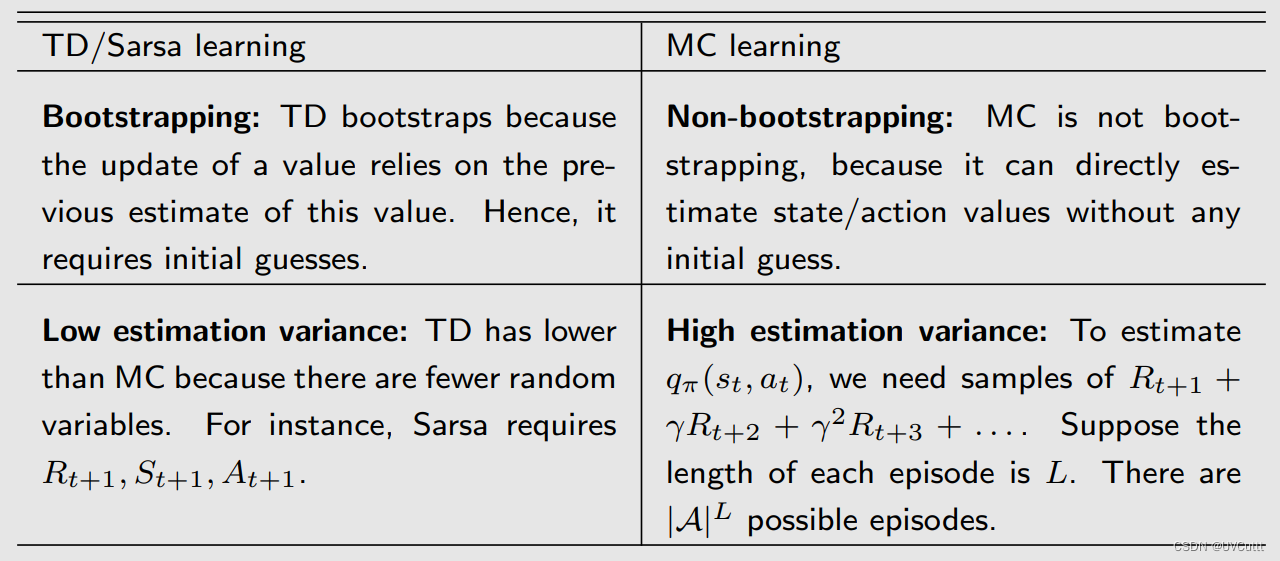
总结
MC:离线,非自举无偏估计,高方差低偏差
TD:在线,自举有偏估计,低方差高偏差,除了MC适用的场景意外,还能用于实时更新,无终止任务的场景
从估计状态价值到估计动作价值的TD算法Sarsa
采样的变化,需要增加两个时刻的动作,这个序列也是名字的由来state-action-reward-state-action
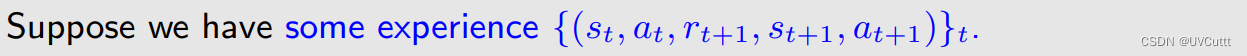
迭代式的变化,状态价值变为了状态动作价值
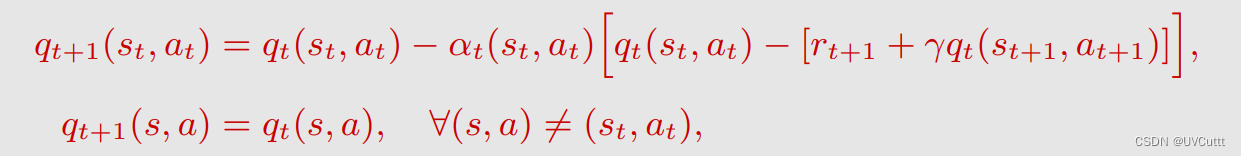
数学本质的变化,贝尔曼期望公式的状态动作价值形式
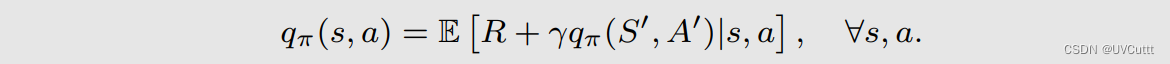
伪代码

Sarsa改进,TD Target中的状态动作价值的估计变为状态动作价值的期望
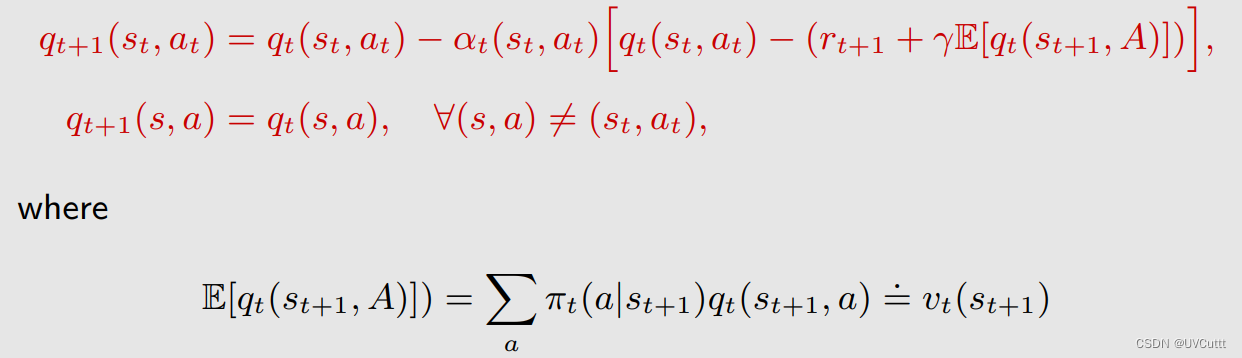
TD Target变了,减少了随机数,减小了自举偏差。

数学本质的变化
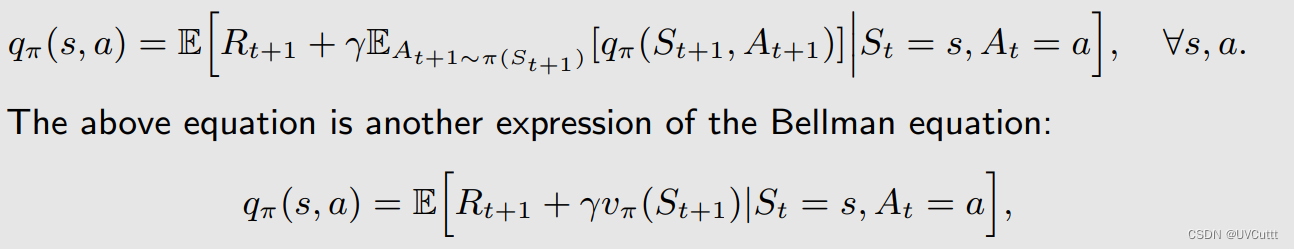
增加了动作作为条件限制,结果由状态价值变为状态动作价值。也是贝尔曼期望公式的状态动作价值的另一种形式。
Sarsa改进,中庸之道:TD思想和MC思想的结合 n-Step Sarsa


该说的都说的很清楚,和之间truncated policy iteration的一样的思想,即非offline,又非online。
Sarsa改进,从估计状态动作价值到选择最优状态动作价值Q-Learning
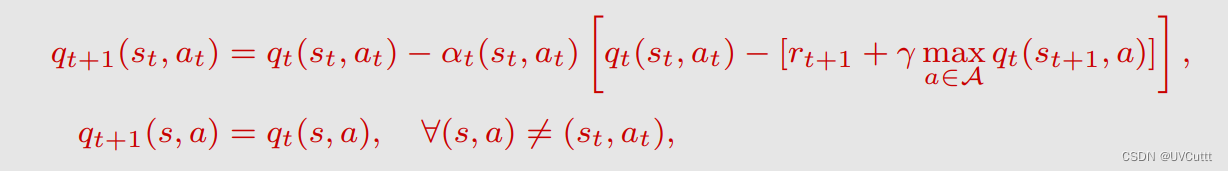
TD Target的变化,直接从状态动作价值变成了最优状态动作价值
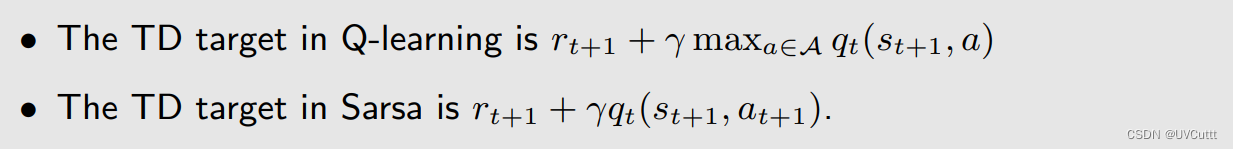
数学本质的变化,很容易想到是贝尔曼最优期望公式的状态动作价值形式
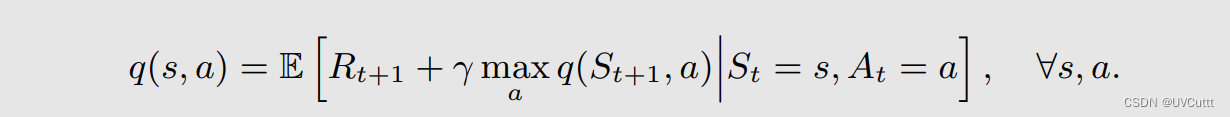
- 插播一条概念,同策略On-Policy和异策略Off-Policy

这两个策略是同一个,就是同策略,反之为异策略。
异策略相较于同策略的优势

如何判断算法是同策略还是异策略,通过判断数学本质的目标(Target Policy)和需要的东西(Behavior Policy)是否相同来判断。

将已学的算法分类

策略π收集数据 --> Sarsa进行PE --> PI过程改进π --> 改进后的π再收集数据
同一个π

策略π收集数据 --> MC进行PE --> PI过程改进π --> 改进后的π再收集数据
同一个π

策略πa收集数据 --> MC进行PE --> PI过程改进πb --> 改进后的πa再收集数据
两个π

这里除了TD Target和Sarsa不一样,其他一样。

这里除了TD Target和Sarsa不一样,更新的时候也只更新了πT,而πb没更新,直接是Greedy策略。
几种算法的形式对比

都能统一成TD的形式。

都是求解贝尔曼公式或者贝尔曼最优公式的随机逼近算法(stochastic approximation algorithms,SAA)。















 1074
1074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









