






在做AI研究和大语言模型训练时,我遇到了从大量文档和网页中提取数据的情况。尤其是PDF、网页等格式,市面的提取工具我都有尝试过,基本所有的软件都有试用期且很多效果没有达到预期,大批量的提取需要充值会员。后面我发现了 MinerU,试了一下,可以很好的满足我的PDF提取需求,下面分享一下使用经验:
什么是MinerU
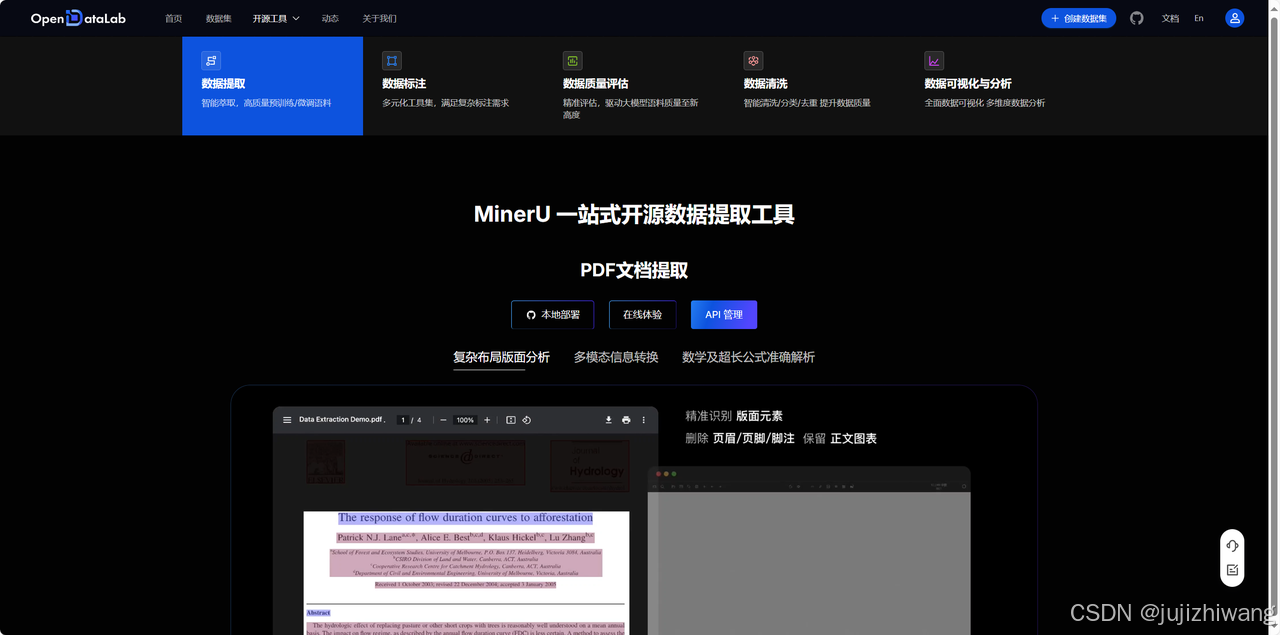
MinerU,由 OpenDataLab 团队开发,已经在GitHub上收获了超过 18.5K stars。它专门为复杂的多模态文档和网页设计,能够将PDF、PPT、DOC等各种文档转化为我和机器都能轻松处理的Markdown或JSON格式。它能智能提取文档中的图片、表格、公式等内容,效果非常精准。

我的使用体验
1. 操作简单,快速上手
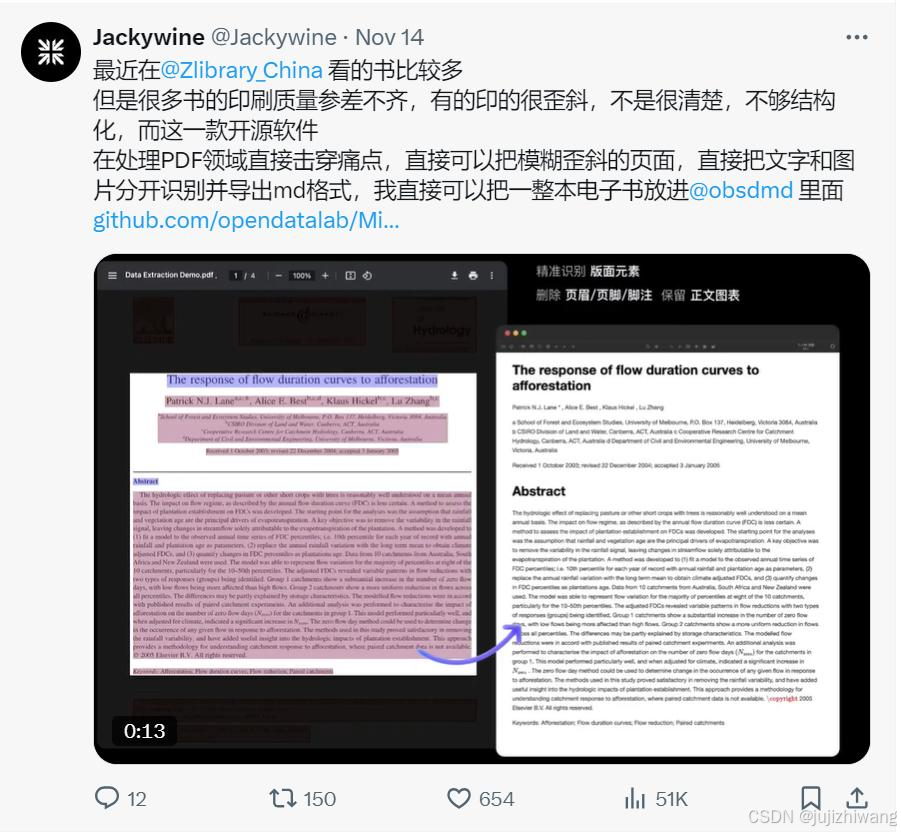
在线使用:只需要访问官网,上传PDF文件,几秒钟后就能得到清晰的Markdown文件输出。操作简便,效率极高!
-
进入官网:MinerU在线体验
-
直接上传文档,自动转换成Markdown格式,不仅速度快,而且内容精准,表格、公式都能完美提取。最新版本已经支持批量上传文档提取,可以一次性上传多个文档,无需逐个操作,方便批量准换。
-
进入文档提取页面,上传文件,自动转换成makedown格式文件


-
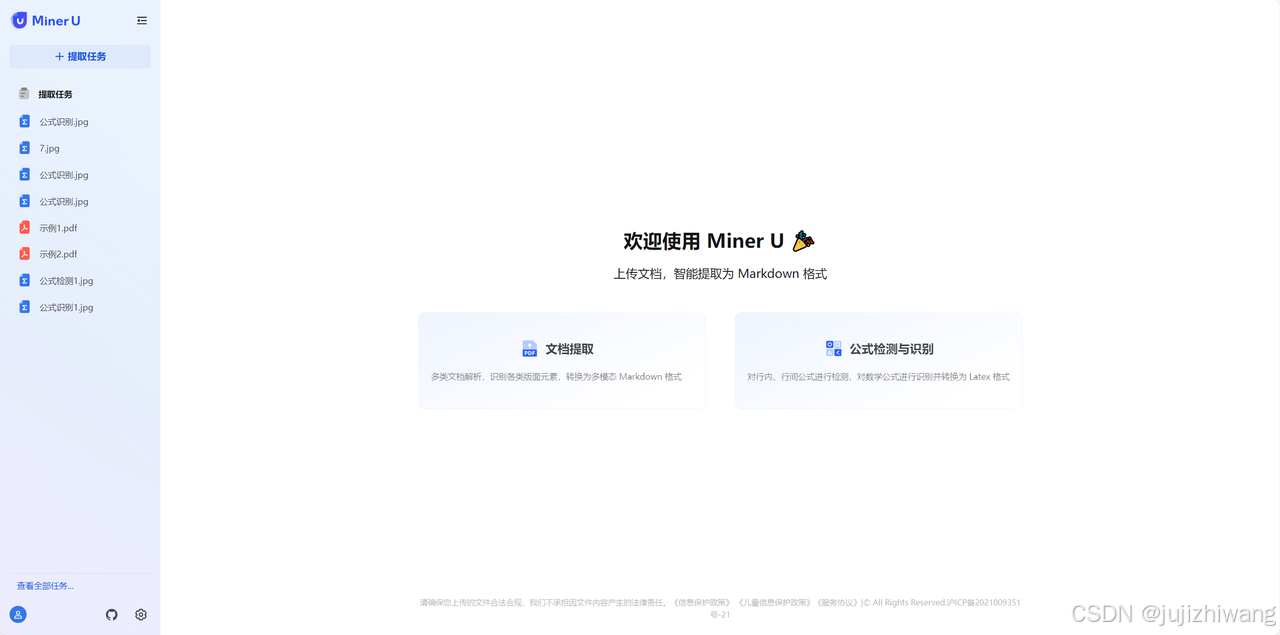
在线体验版可批量上传文件,转换完成后点击查看任务可进行批量下载与解析

-
批量转换完成后可批量下载
2. 主要功能
MinerU的核心功能包括:
-
精准提取:它会自动删除页眉、页脚、页码等干扰内容,确保提取的文本结构清晰,语义连贯。
-
多模态支持:不仅能提取文本,还能提取图片、表格(转换为HTML格式)、公式(转换为LaTeX),简直是我的AI语料准备神器。
-
OCR支持:对于扫描版PDF或乱码文档,MinerU内置OCR功能,支持识别 84种语言,可以让识别效果更精准。
3. API与批量上传功能
除了在线体验,MinerU还提供了 API接口,可以在自己的开发环境中快速集成它,批量处理文档。特别是对于需要大规模文档处理的任务,批量上传功能非常方便,节省了大量时间和精力。
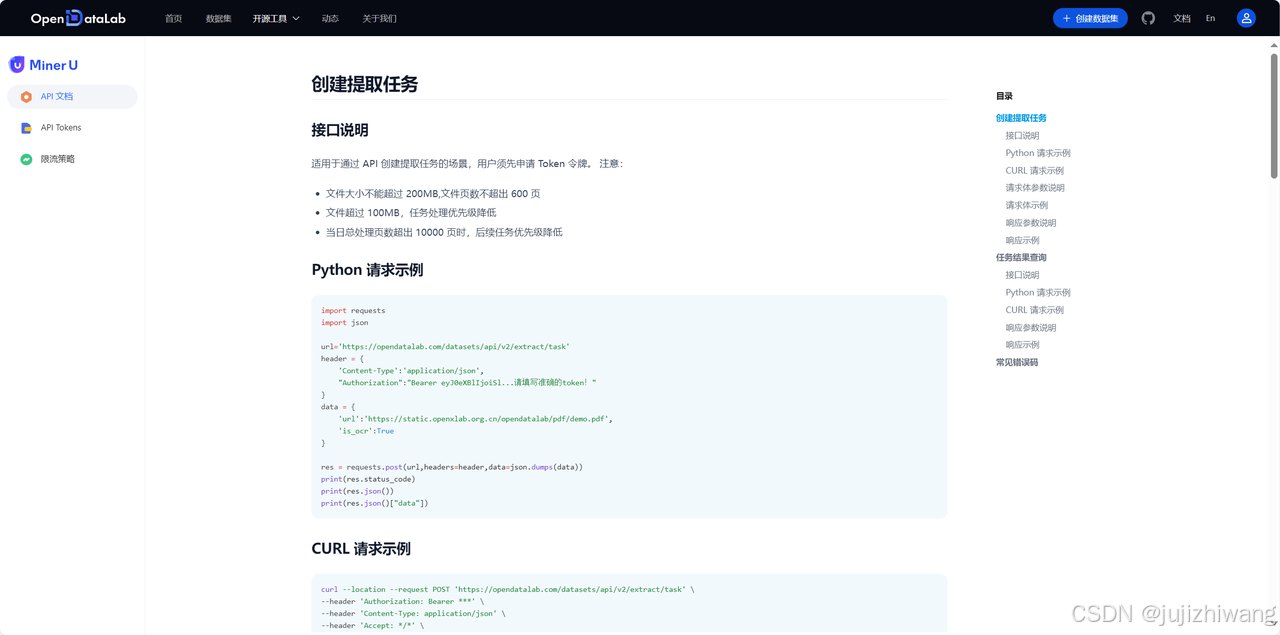
API申请入口:https://opendatalab.com/OpenSourceTools/mineru/api
4. Huggingface在线使用
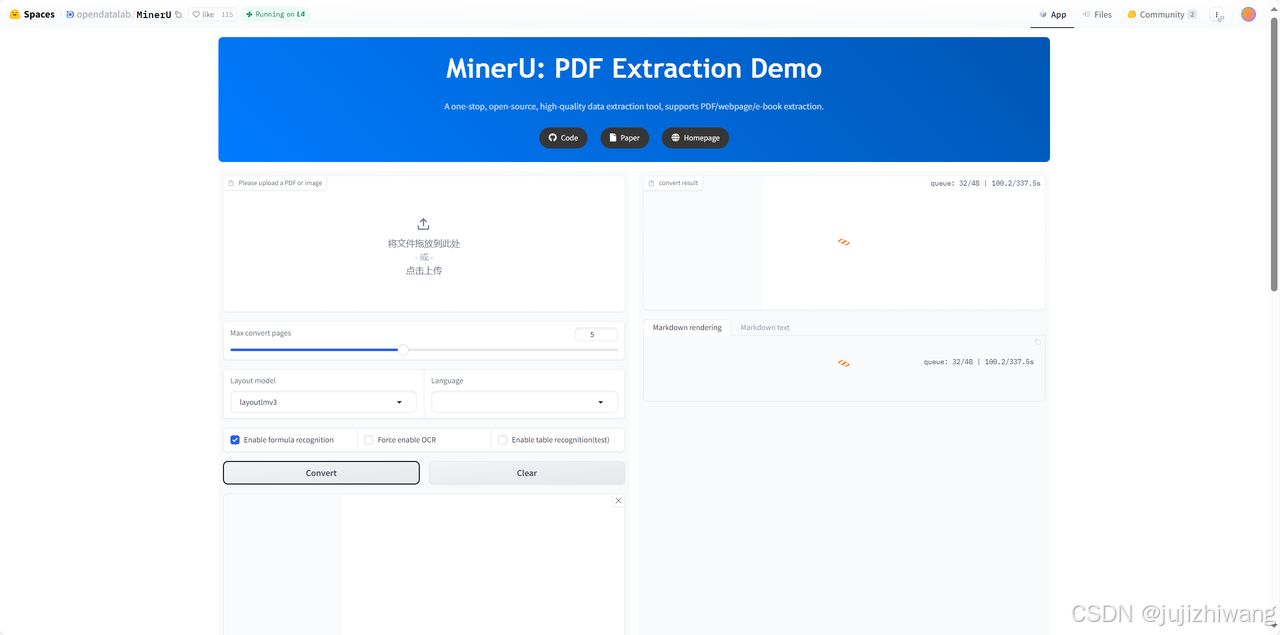
Huggingface上也有在线体验的demo:https://huggingface.co/spaces/opendatalab/MinerU
-
可以在上传文件前选择对应的配置项,提高文件的识别转换效率
- layout model:doclayout_yolo、layoutlmv3
- language:支持 84 种语言的检测和识别,选择转换文档语言转换效率更精准,未选择会自动识别
- Enable formula recognition:开启后,将精准识别文档中的数学公式和符号,提升公式提取效果。
- Force enable OCR:开启后,将强制使用 OCR 技术对文档进行文字识别,适用于图片格式或低质量文档的内容提取。
- Enable table recognition(test):开启后,系统将优先精准识别文档中的表格内容。注意:该功能目前为测试版,识别效果可能有所不同。
-
上传文档,点击convert,进行转换
如何开始?
访问GitHub下载源码
- MinerU GitHub页面,可以下载并查看源代码,还支持二次开发,满足个性化需求。
在线体验
-
官方在线工具:MinerU在线体验
-
Huggingface体验:MinerU Huggingface页面
申请API内测
-
如果你需要批量处理文档,可以申请 API内测,填写申请问卷后即可立即使用!
-
申请链接:API内测申请
总结
总的来说,MinerU还不错!在找PDF提取工具的朋友可以试试😄

















 4667
4667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









