







目标
给定指定的站点信息(始发站和终点站)和发车时间,得到相应的信息表格
代码
from selenium import webdriver
import sys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.select import Select
import re
from lxml import etree
import pandas as pd
from prettytable import PrettyTable
def driver_construction():
driver_path = r'C:\Users\dell\Anaconda3\Scripts\chromedriver.exe'
driver = webdriver.Chrome(driver_path)
return driver
def parse_argv(argv_lst):
departure_station = argv_lst[1]
destination = argv_lst[2]
departure_time = argv_lst[3]
time_match = re.search('(.*?)-(.*?)-(.*)', departure_time)
year = time_match.group(1)
month = time_match.group(2)
day = time_match.group(3)
month_dic = {
"01":"一月",
"02":"二月",
"03":"三月",
"04":"四月",
"05":"五月",
"06":"六月",
"07":"七月",
"08":"八月",
"09":"九月",
"10":"十月",
"11":"十一月",
"12":"十二月",
}
month = month_dic[month]
day_dict = {
"01": "1",
"02": "2",
"03": "3",
"04": "4",
"05": "5",
"06": "6",
"07": "7",
"08": "8",
"09": "9",
}
if day in day_dict:
day = day_dict[day]
time = (year,month,day)
return departure_station,destination, time
def input_information_request_page(driver, departure_station,destination, time):
main_url = "https://www.12306.cn/index/"
main_page = driver.get(main_url)
# 将用户输入的信息传入页面中的文本框处
year,month,day = time
input_departure_box = driver.find_element_by_id("fromStationText").click()
departure_station_click = driver.find_element_by_xpath('//li[@title="%s"]'%departure_station).click()
input_destination = driver.find_element(By.ID,value="toStationText").click()
destination_click = driver.find_element_by_xpath('//li[@title="%s"]'%destination).click()
input_departure_time = driver.find_element(By.ID,value="train_date").click()
year_click = driver.find_element_by_xpath('//div[@class="year"]//input[@type="text"]').click()
click = driver.find_element_by_xpath('//li[text()="%s"]' % year).click()
month_click = driver.find_element_by_xpath('//div[@class="month"]//input[@type="text"]').click()
click = driver.find_element_by_xpath('//li[text()="%s"]' % month).click()
day_click = driver.find_element_by_xpath('//div[text()=%d]' % int(day)).click()
# 点击查询按钮
search_button = driver.find_element_by_id("search_one").click()
# 将driver转到最新的页面上去
driver.switch_to_window(driver.window_handles[-1])
# 获取最新打开的页面源码
page_source = driver.page_source
return page_source
def attain_infos_from_page_source(page_source):
html = etree.HTML(page_source)
diction = {}
checi_lst = html.xpath('//a[@title="点击查看停靠站信息"]/text()')
print(checi_lst)
for checi in checi_lst:
info = html.xpath('//tr[contains(@id,"%s")]//text()' % checi)
if info:
info.remove(info[1])
info.remove(info[1])
info = list(info)[0:7]
info2 = html.xpath('//td[contains(@hbid,"%s")]//text()' % checi)
info2 = list(info2)
info = info + info2
info = list(info)
info = list(map(lambda x:x.replace(' ',''),info))
info = list(map(lambda x:x.ljust(6),info))
# diction[checi] = info[1:]
if len(info) == 18:
diction[checi] = info
columns_index = ["车次", "出发站", "到达站", "出发时间", "到达时间", "历时", "到达状态", "商务座", "一等座", "二等座", "高级软卧", "软卧", "动卧", "硬卧",
"软座", "硬座", "无座", "其他"]
columns_index = map(lambda x: x.ljust(6), columns_index)
columns_index = tuple(columns_index)
diction["title"] = columns_index
return diction
def print_form(diction):
tab = PrettyTable() # 创建格式化表格
columns_index = diction["title"]
tab.field_names = columns_index # 把title行作为第一行
del diction["title"] # 把 diction 中 title 这行删除
for value in diction.values():
tab.add_row(value)
return tab
if __name__ == '__main__':
argv_lst = sys.argv
driver = driver_construction()
departure_station, destination, time = parse_argv(argv_lst)
print(departure_station, destination, time)
page_source = input_information_request_page(driver, departure_station, destination, time)
diction = attain_infos_from_page_source(page_source)
tab = print_form(diction)
print(tab)
with open('table.txt','w',encoding='utf-8') as f:
f.write(str(tab))
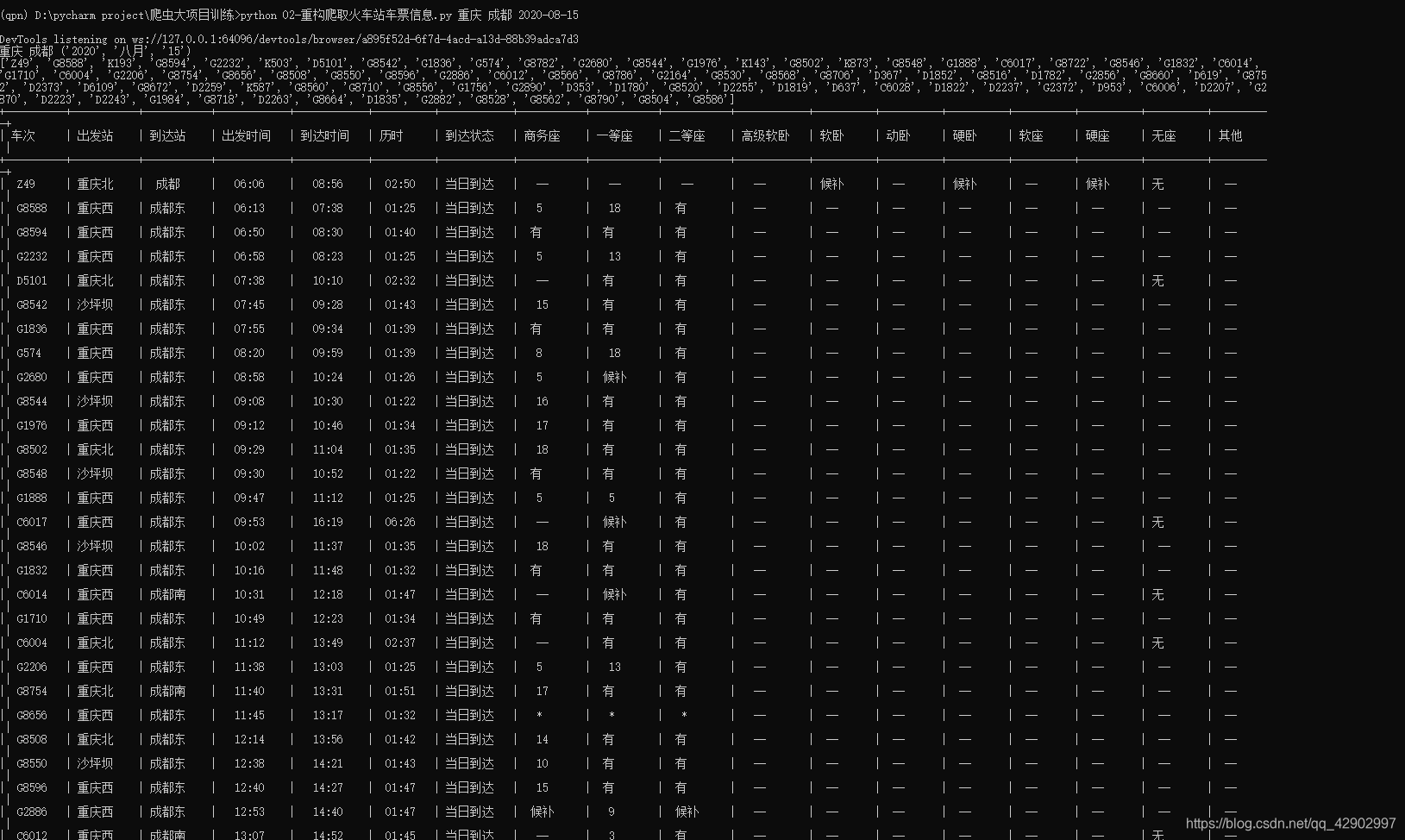
结果


















 5072
5072

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











