






GIL
Cpython因为存在GIL(全局解释器锁)导致python无法真正实现并行计算,故多线程/多进程需要了解。
线程、进程
举例子:进程 = 火车
线程 = 车厢
一个进程可以包含多个进程,各个进程之间共享资源,多个进程之间切换开销相对于进程较小
多个进程之间 不共享资源,进程间切换开销较大
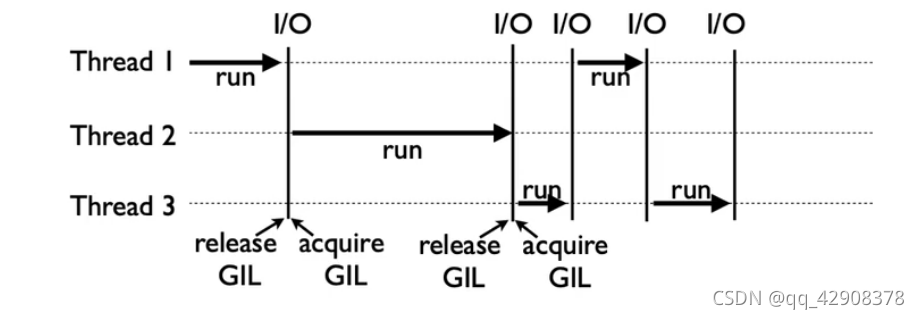
GIL 限制同一时间单个进程中只能有一个线程在运行
多进程
单个进程中只能有一个线程在运行,假如同时启动多个进程,可以在某个进程io期间,另一个进程运行,从而实现了假并行计算
参考图如下:
多进程
现在的计算机都是多核心的、我理解的是一个核心可以启动一个进程 假如你有8核CPU那就可以同时并行运行8个进程,不管每个进程里面如何GIL,我外部实现了8核心同时运行
多进程、多线程选取
**多线程:**适合IO密集操作
**多进程:**适合CPU计算密集型
代码示例
# 这里使用了进程池
from concurrent import futures
# 定义worker方法,实现复杂计算,测试多进程、多线程
def worker(num):
for i in range(num):
a += i*1000+i*1000000000000
if __name__ == '__main__':
num = 10000
# 多进程
with futures.ProcessPoolExecutor() as pool:
pool.map(worker, num)
# 多线程
with futures.ThreadPoolExecutor() as pool:
pool.map(worker, num)
代码示例2 (参考转载)
https://blog.csdn.net/qissme/article/details/105987533 --使用python多进程批量转换word为PDF
def worker(input_file):
print("{} 开始转化...\n".format(input_file))
docx2pdf(input_file)
print("{} 【转化完成】".format(input_file))
def main(): #多进程必须放在主程序中设置
directory = r"C:\Users\31209\Desktop\新建文件夹"
from multiprocessing import cpu_count
print("cpu个数:",cpu_count()) #获取CPU个数
ps = Pool(5) #设置线程池
docs = find_docs(directory)
if docs !=[]:
print("主进程开始执行:")
for i in docs:
# ps.apply(worker,args=(i,)) # 同步执行 (一个进程一个进程执行)基本不用
ps.apply_async(worker,args=(i,)) # 异步执行 (同时开启五个进程)
ps.close() # 关闭进程池,停止接受其它进程
ps.join()# 阻塞进程
print("主进程终止!")
结果是 同时开启5个进程,每执行完一个 另一个进程开启直到全部执行完毕
**每创建一个子进程都会复制父进程内存资源状态,所以多进程势必会造成极大资源开销,python3.8提供了共享内存share_memory可以解决这个问题,下面放参考连接
https://zhuanlan.zhihu.com/p/146769255
**














 861
861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









