







论文名称:Improved Neural Relation Detection for Knowledge Base Question Answering
论文地址:https://arxiv.org/pdf/1704.06194.pdf
一、论文背景
首先我们需要知道什么是知识图谱。如下图所示,知识图谱元素由主语、谓语(也称为“关系”)和宾语构成,利用三元组(subject,predicate,object)存储每个关系。

如下图,(姚明,出生地,上海)和(姚明,国籍,中国)都是三元组,显然这两个元祖的主语相同。绘图可以直观显示不同元祖之间的关系,所以由这些关系绘制的图也被称为知识图谱。

那什么是基于知识图谱的问答呢?当我们问姚明配偶是谁时,很显然我们可以从图中看出是叶莉,即当我们知道subject(主语)和predicate(谓语)时,就可以从三元组(subject,predicate,object)中得知object(宾语)。我们从一个问题中提取出主语和谓语,再与图中的三元组匹配,得出宾语(即问题的答案),就是基于知识图谱的问答。
二、回答问题的方法
1.句子预处理
我们需要识别句子的mention(提及检测,即检测提取句子包含主语的部分),以句子“姚明配偶是谁”为例,该句子mention为姚明,所以我们将姚明提取出来(提取可以使用bio算法,该算法使用lstm,在句子输入过程中对单词进行标注)。提取出mention后,我们用< e >替换句子中原mention,则原句子变为“< e >配偶是谁”。此时我们拥有两项数据,“姚明”和“< e >配偶是谁”。
2.不同数据的任务
因为“姚明”可能存在同名的现象(即知识图谱中有另外一个“姚明”),所以mention“姚明”用于识别主语而不是直接就是主语了。“< e >配偶是谁”用于识别关系,句子中为“配偶”。
3.识别方式
利用mention“姚明”提取出知识图谱中长相比较相似的前n个主语(利用最长字符串匹配,再考虑两个主语长度的方法),比如“姚明”、“李姚明”、“何姚明”等,再计算mention与这n个主语的相似度(此时使用神经网络),相似度得分别为A1、A2、A3…An。
第一个主语可能有m个关系,计算“< e >配偶是谁”和这m个关系的相似度得分B1、B2、B3…Bm,计算得出最大综合得分:
f
1
max
=
max
h
∈
{
1
,
2..
m
}
{
k
∗
A
1
+
(
1
−
k
)
∗
B
h
}
{f_{1\max }} = \mathop {\max }\limits_{h \in \{ 1,2..m\} } \{ k * {A_1} + (1 - k) * {B_h}\}
f1max=h∈{1,2..m}max{k∗A1+(1−k)∗Bh}第2到n个主语也进行同样的操作,则我们有
f
1
max
{{\rm{f}}_{1\max }}
f1max、
f
2
max
{{\rm{f}}_{2\max }}
f2max…
f
n
max
{{\rm{f}}_{n\max }}
fnmax。我们再对这n个值取最大值,即:
f
max
=
m
a
x
max
z
∈
{
1
,
2..
n
}
{
f
z
}
{f_{\max }} = max\mathop {\max }\limits_{z \in \{ 1,2..n\} } \left\{ {{f_z}} \right\}
fmax=maxz∈{1,2..n}max{fz}
经过两轮最大求解,我们已经有了
f
max
{f_{\max }}
fmax和其对应的h和z(h对应关系,z对应主语)。通过主语和关系,我们可以得出宾语,即得出问题的答案。
三、关系连接网络结构
本篇论文主要对识别关系的网络进行了改进。如下图所示,左边输入的是question(如上文中的“< e >配偶是谁”),右边输入的是候选的Relation(比如“姚明”有“出生地”、“国籍”和“配偶”关系)。
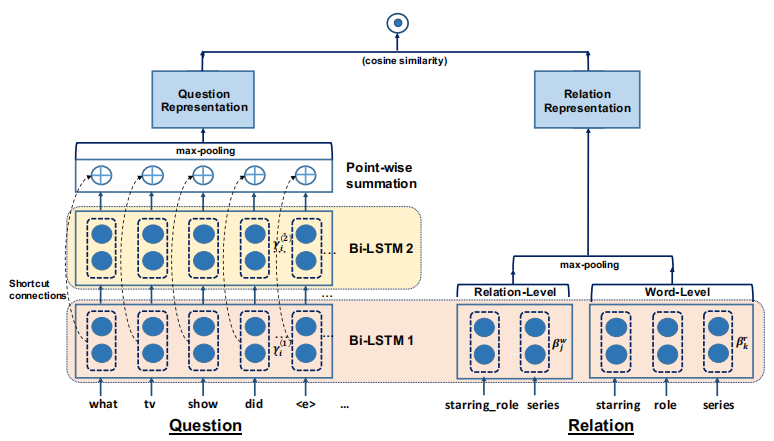
question输入Bi-LSTM(双向长短期神经网络),Bi-LSTM相对于单向LSTM,能够提取文本的逆向信息,比如我们不仅能t提取“我爱你”的“爱”的信息(此时“爱”作用对象为“你”,为正向),还能提取“你,我爱”的“爱”的信息(此时“爱”作用于“你”,为逆向)。利用双层双向LSTM,在增加信息提取能力的同时,会有令某一层参数接近0的可能性,所以论文加入了残差进行连接形成HR-BiLSTM(带残差的双向神经网络)。最后池化形成单一向量Q1。
对于relation的输入,论文形成两个,一个是带有总体信息的relation级别的embedding,一个是单词级别的embedding。通过两级输入,论文不仅考虑了总体信息,而且还考虑了局部信息。最后池化形成单一向量Q2。
对Q1和Q2进行余弦相似度计算。如果为正确关系,我们令label为1(否则为0),与该余弦相似度相减作为loss,即可更新参数。论文中采用了另外一种方法,如下图所示(虽然表达方法不同,但是原理是相似的)。其中,
s
r
e
l
(
r
+
;
q
)
srel(r + ;q)
srel(r+;q)代表正确关系的loss,
s
r
e
l
(
r
−
;
q
)
srel(r - ;q)
srel(r−;q)代表错误关系的loss,
γ
\gamma
γ为我们人为设定的参数。
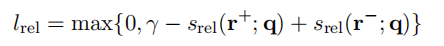
结论:论文使用HR-BiLSTM让question的信息提取更细粒度和高效化;同时考虑relation整体和局部信息,更为全面。















 315
315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









