






一、前言
目前我国智慧城市的场景划分覆盖面很广,比如智慧园区、智慧工地、智慧交通、智慧机场等等。不同的智慧场景,其覆盖范围都不一样,但通常而言,智慧城市行业主要是对空间内的人、车、物进行识别分析。
本文主要以越界识别功能为例,其底层的算法技术,主要是人体检测+人体追踪+区域业务功能判断。这里的业务功能,主要是判断监测区域,在某个时间内,是否有人闯入。而人体检测+人体追踪+不同的业务功能,也可以实现各种各样不同的算法功能。比如可以实现医院进出口人流量统计,实现的业务功能,主要统计经过线段或者区域的人员数量。
二、环境配置
1.跨平台应用系统Aidlux
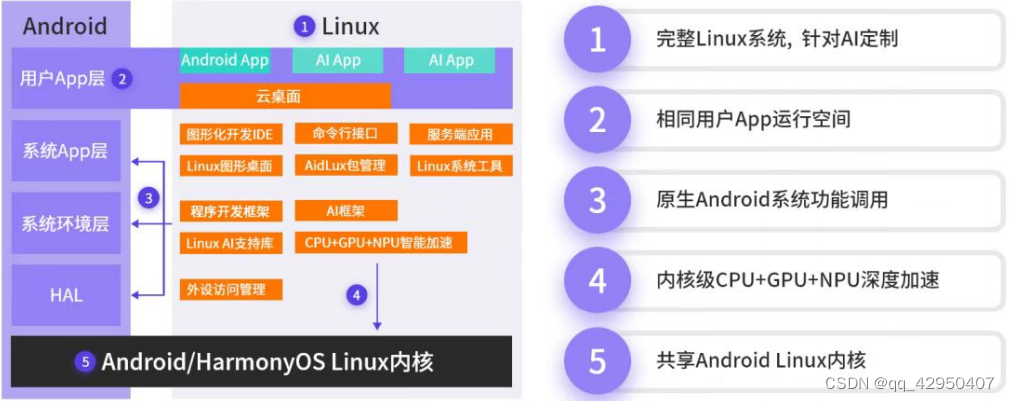
Aidlux主打的是基于ARM架构的跨生态(Android/鸿蒙+Linux)一站式AIOT应用开发平台。用比较简单的方式理解,我们平时编写训练模型,测试模型的时候,常用的是 Linux/window系统。而实际应用到现场的时候,通常会以几种形态:GPU服务器、嵌入式设备(比如Android手机、人脸识别闸机等)、边缘设备。GPU服务器我们好理解,而Android 嵌入式设备的底层芯片,通常是ARM架构。而Linux底层也是ARM架构,并且Android又是 基于Linux内核开发的操作系统,两者可以共享Linux内核。因此就产生了从底层开发一套应用系统的方式,在此基础上同时带来原生Android和原生Linux使用体验。
4.PC端Aidlux投影测试
打开手机版本的Aidlux软件APP,第一次进入的时候,APP自带的系统会进行初始化。初始化好后,进入系统登录页面,这一步最好可以用手机注册一下,当然也可以直接点击“我已阅读并同意”,然后点击跳过登录。


比如这里,笔者是192.168.1.103:8000,打开电脑浏览器,输入相应的ip,即http://192.168.1.103:8000。

密码默认是aidlux,输入后即可进入主页面,可以看到其中的内容和手机端是一样的。
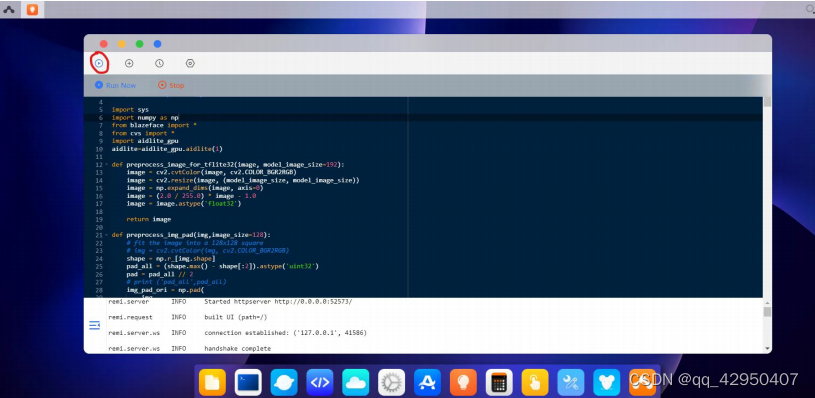
5.Aidlux系统AI案例测试
7.PC端下载vscode软件
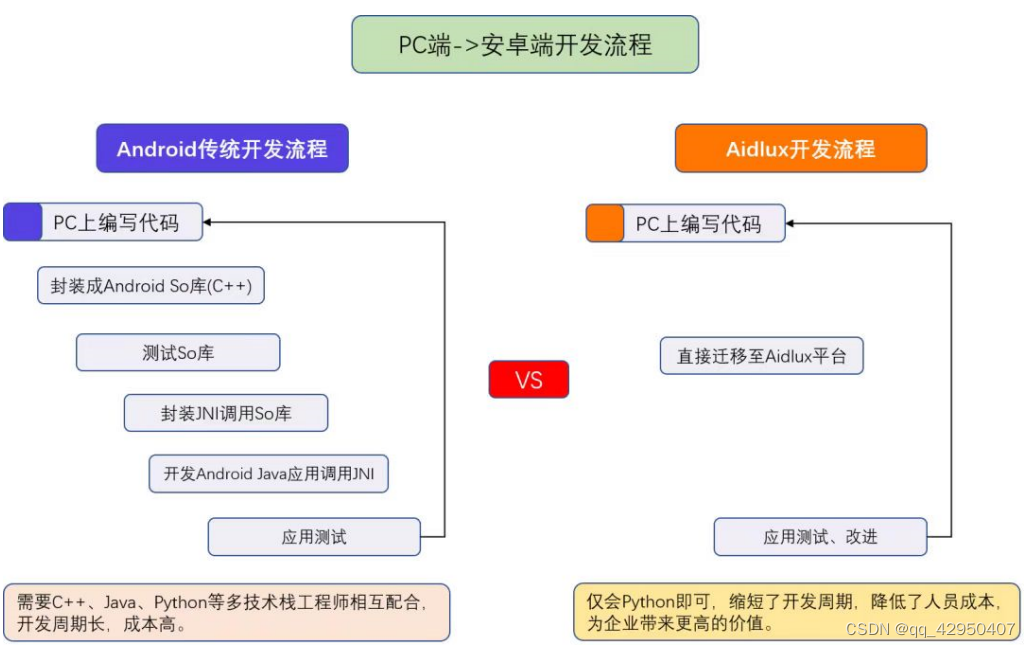
通常工作中我们常用Pycharm和Vscode两款软件,算法人员可能Pycharm使用的多一些。不过目前手机版本的Aidlux对于Pycharm支持还不太友好,因此我们也可以采用Vscode的方式,也方便好用。
点击官网https://code.visualstudio.com/,选择Download按钮进行下载,因为用的时Window电脑,跳到了匹配的默认项。
8.安装python和opencv

在终端页面输入:pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple,即可快速下载安装成功。
三、PC端远程调试Aidlux
1.PC端上传文件
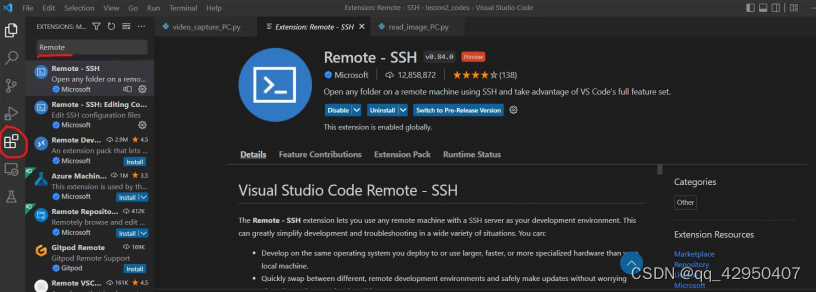
2.安装Remote SSH
点击Vscode左侧的“Extensions”,输入“Remote”,针对跳出的Remote SSH,点击安装。
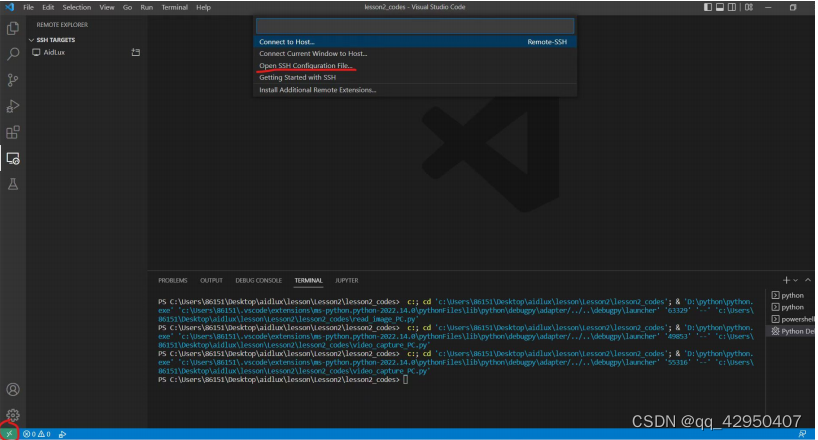
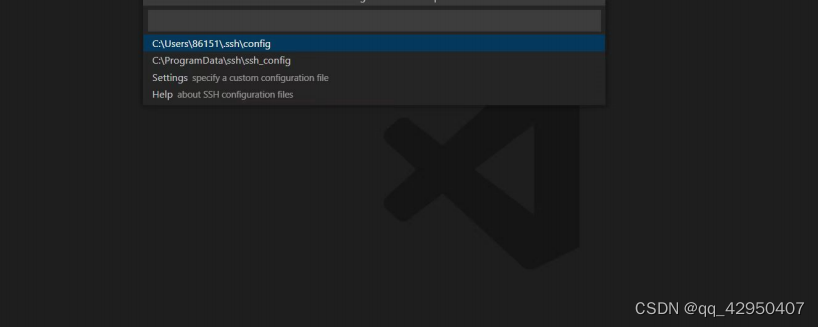
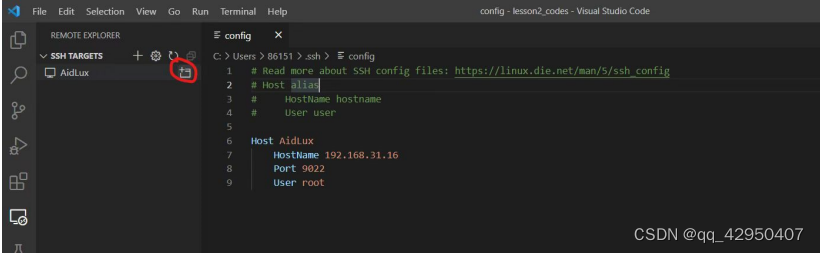
3.远程链接调试
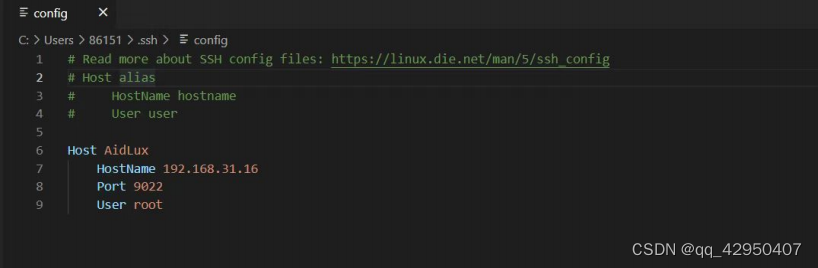
Host AidLux # 服务器别名
HostName 192.168.0.4 # 填写远程服务器的IP或者
HostPort 9022 # 填写访问远程服务器的端口号,这里默认写9022,不写8000
User root # 填写登陆远程服务器的用户的名字
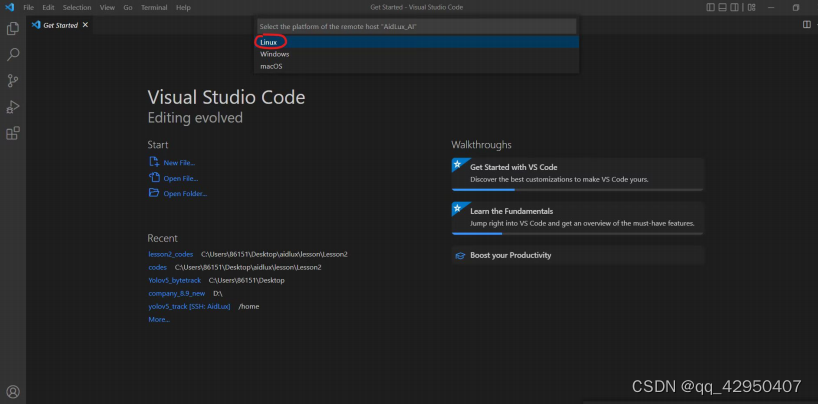
选择“Continue”,再输入密码,aidlux。
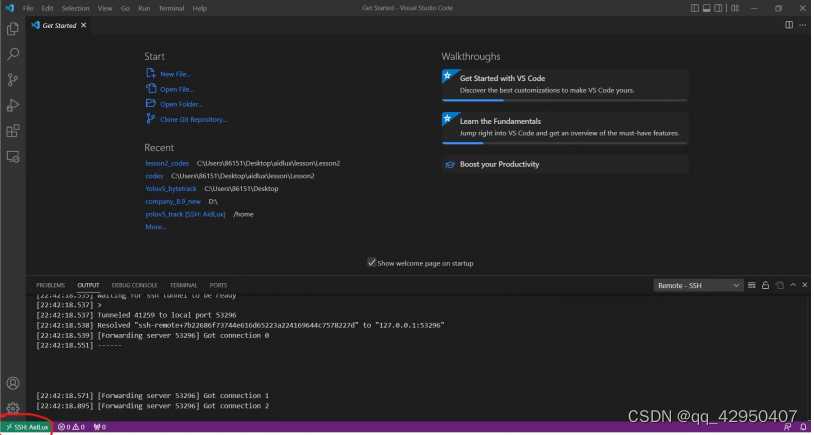
当左下角跳出SSH Aidlux时,表示已经连接成功。
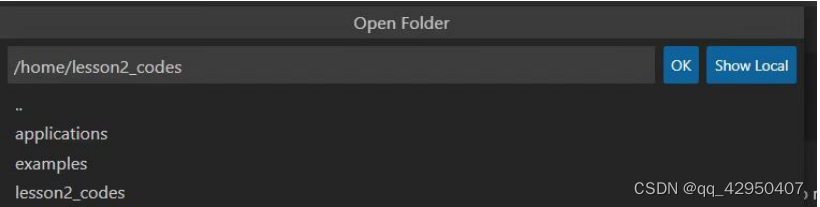
 选择左上角的File,点击Open Filer,即可跳出Aidlux里面的路径。
选择左上角的File,点击Open Filer,即可跳出Aidlux里面的路径。

将路径输入的信息,修改成”/home/lesson2_codes“,点击OK。 跳出的窗口中,再输入密码”aidlux“,即可打开我们已经上传的Lesson2_code文件夹。
四、AI案例:MOT16视频数据集——东京街道人流量统计
1.准备数据集
在本次的案例中,我们使用的是旷视的Crowdhuamn数据集,官网http://www.crowdhuman.org/去下载,Crowdhuman数据集,总共包含三个子数据集:15000张的训练数据集,4370张的验证数据集,5000张的测试数据集。其中训练集和验证集都是有标注信息的,测试集没有标注信息。
2.数据集格式转换
在本次的案例中,我们选用了4370张的val数据集来做为训练集,我们知道在不同的代码中进行检测是需要将数据集的格式转换为所选训练模型对应的格式,这里Crowhuman数据集的val数据集的标注为annotation_val.odgt,接下来我们需要进行数据集格式的转换(我们这里先将其转换为VOC格式,在将其转换为txt格式),这里,为了节约时间,我们可以直接关注“”AidLux“”公众号,回复lesson3,获得了lesson3资料包的连接之后进入百度网盘进行下载。
在VScode中点击"File",然后点击“open Folder”,点击下载好的lesson3进入lesson3_codes文件夹,在进入data_prepare_code打开data_code.py文件。
from xml.dom import minidom
import cv2
import os
import json
from PIL import Image
#将这里的路径改为自己的对应文件路径
roadlabels = "E:/360MoveData/Users/26337/Desktop/Lesson3/lesson3_data/Crowdhuman_data/Annotations"
roadimages = "E:/360MoveData/Users/26337/Desktop/Lesson3/lesson3_data/Crowdhuman_data/JPEGImages"
fpath = "E:/360MoveData/Users/26337/Desktop/Lesson3/lesson3_data/Crowdhuman_data/annotation_val.odgt"
........之后点击运行,生成一系列的xml文件。
在lesson3_data下新建一个文件夹train_data,,在其中再新建一个train和test文件夹,将之前的数据集中的val验证集和Annotations,分别复制到train_data下的train文件夹中分别命名为JPEGImages和Annotations。

3.数据清洗
import argparse
import xml.etree.ElementTree as ET
from utilis import *
import argparse
label_list = ['person']
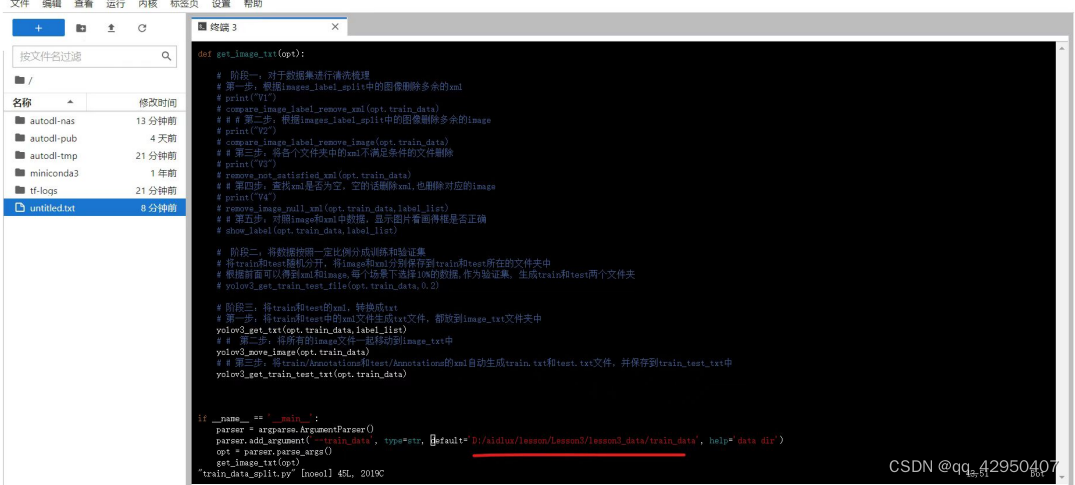
def get_image_txt(opt):
# 阶段一:对于数据集进行清洗梳理
# 第一步:根据images_label_split中的图像删除多余的xml
# print("V1")
# compare_image_label_remove_xml(opt.train_data)
# # # 第二步:根据images_label_split中的图像删除多余的image
# print("V2")
# compare_image_label_remove_image(opt.train_data)
# # 第三步:将各个文件夹中的xml不满足条件的文件删除
# print("V3")
# remove_not_satisfied_xml(opt.train_data)
# # 第四步:查找xml是否为空,空的话删除xml,也删除对应的image
# print("V4")
# remove_image_null_xml(opt.train_data,label_list)
# # 第五步:对照image和xml中数据,显示图片看画得框是否正确
# show_label(opt.train_data,label_list)
# 阶段二:将数据按照一定比例分成训练和验证集
# 将train和test随机分开,将image和xml分别保存到train和test所在的文件夹中
# 根据前面可以得到xml和image,每个场景下选择10%的数据,作为验证集, 生成train和test两个文件夹
yolov3_get_train_test_file(opt.train_data,0.2)
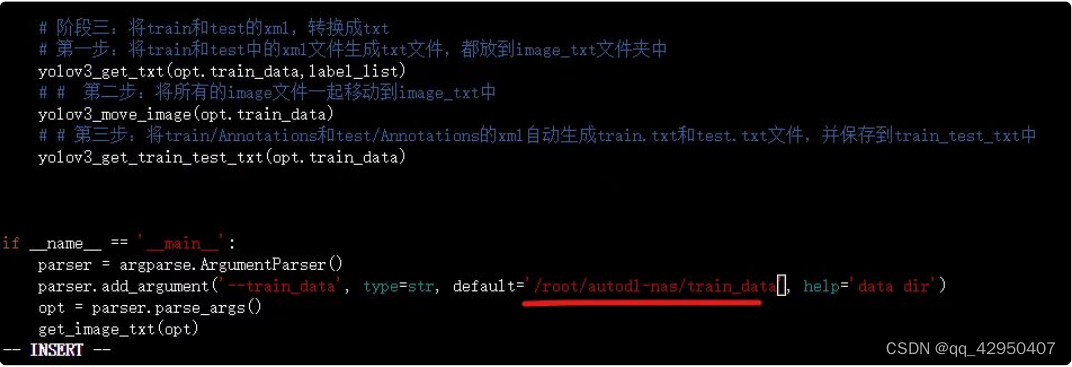
# 阶段三:将train和test的xml,转换成txt
# 第一步:将train和test中的xml文件生成txt文件,都放到image_txt文件夹中
# yolov3_get_txt(opt.train_data,label_list)
# # # 第二步:将所有的image文件一起移动到image_txt中
# yolov3_move_image(opt.train_data)
# # # 第三步:将train/Annotations和test/Annotations的xml自动生成train.txt和test.txt文件,并保存到train_test_txt中
# yolov3_get_train_test_txt(opt.train_data)


修改完成后,按键盘上的Esc键,跳出编辑状态。 再输⼊“:”,会跳出输⼊框,再输⼊"wq!",表示对于该修改内容,保存编辑强制退出,回到原始⻚⾯。 因为云服务器我们刚刚新建实例的时候,没有安装任何安装包。所以先pip install opencv-python,安装 ⼀下。
将xml转换成txt格式进⾏中:

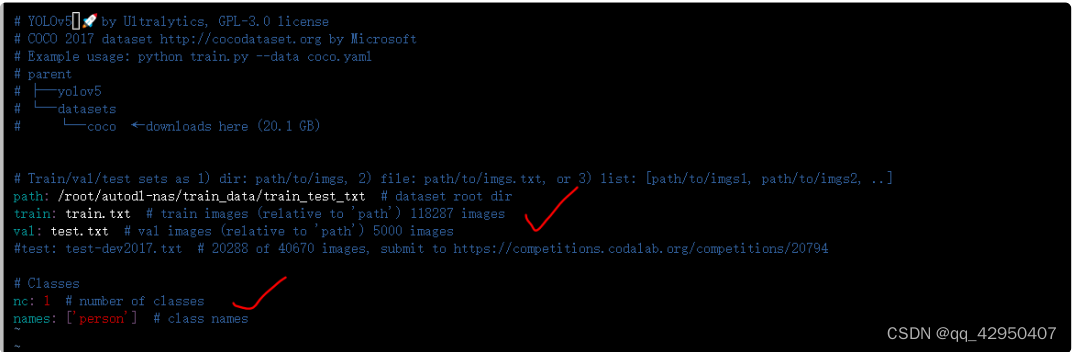
新建person.yaml:
⽽yolov5_code/train.py⽂件中,主要修改models初始化模型的路径,这⾥⼤⽩使⽤的yolov5n的模型权重。cfg即模型对应的⽹络结构路径,data是新增的person.yaml路径。此外还有epochs训练迭代的次 数,batch-size⼤⼩,当然imgsz也可以修改,这⾥默认640。
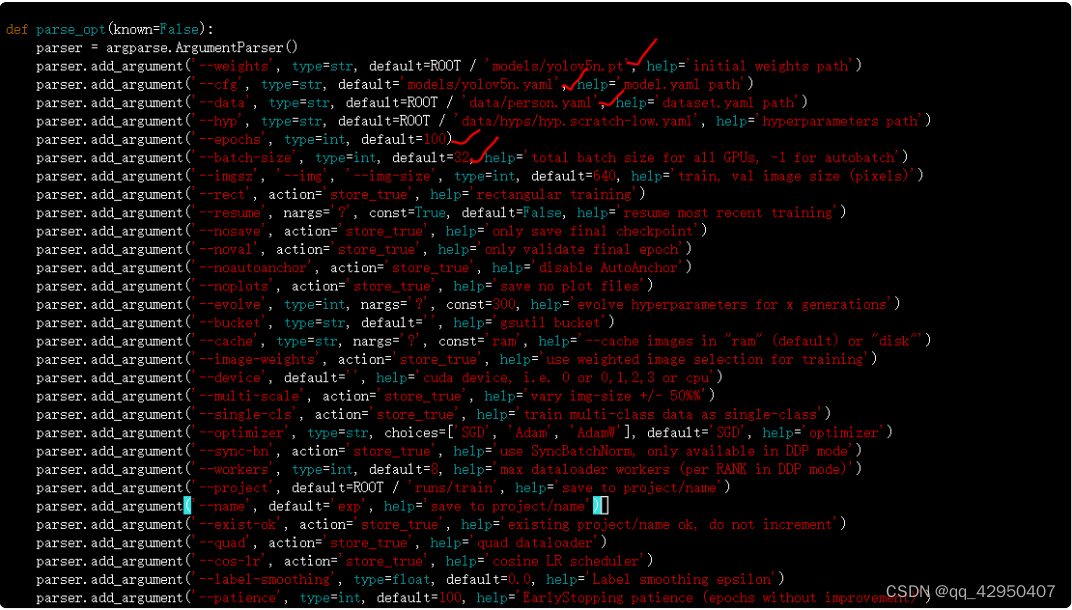
修改models/yolov5n.yaml:修改其中的类别数量,因为⼈体就⼀个类别,修改成1。
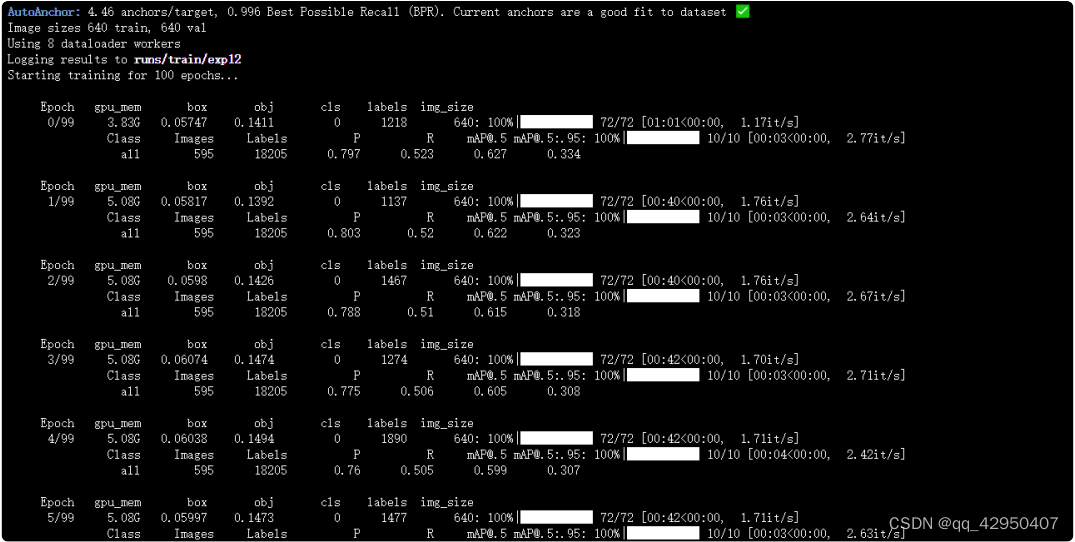
训练过程中,⼀般会得到两个模型,⼀个best.pt,即epoch迭代的过程中,map精度对⽐⽐较好保存的模型。⼀个是last.pt,即迭代过程中,最后⼀次epoch保存的模型。⽐如⼤⽩训练过程中,保存的这两 个,在后⾯测试的时候,主要使⽤best.pt⽂件。
将best.pt模型下载下来,修改成yolov5n_best.pt。并放到资料包代码⽂件夹中。
5.PC端Pytorch推理测试
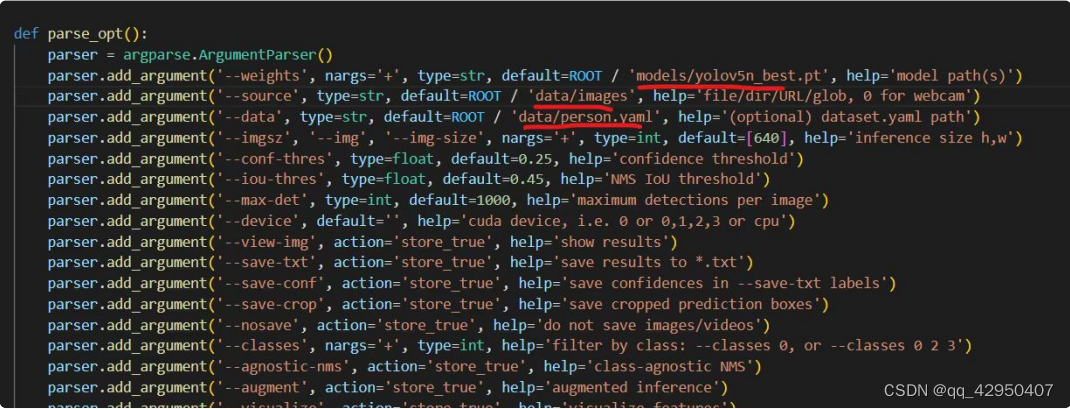
6.Aidlux端模型推理测试
Aidlux主要针对推理 部分,在底层进⾏了加速优化。因此想要将pt模型移植到Aidlux上使⽤,还要进⾏转换模型,修改推理代 码的操作。
6.1 pt模型转换成tflite模型
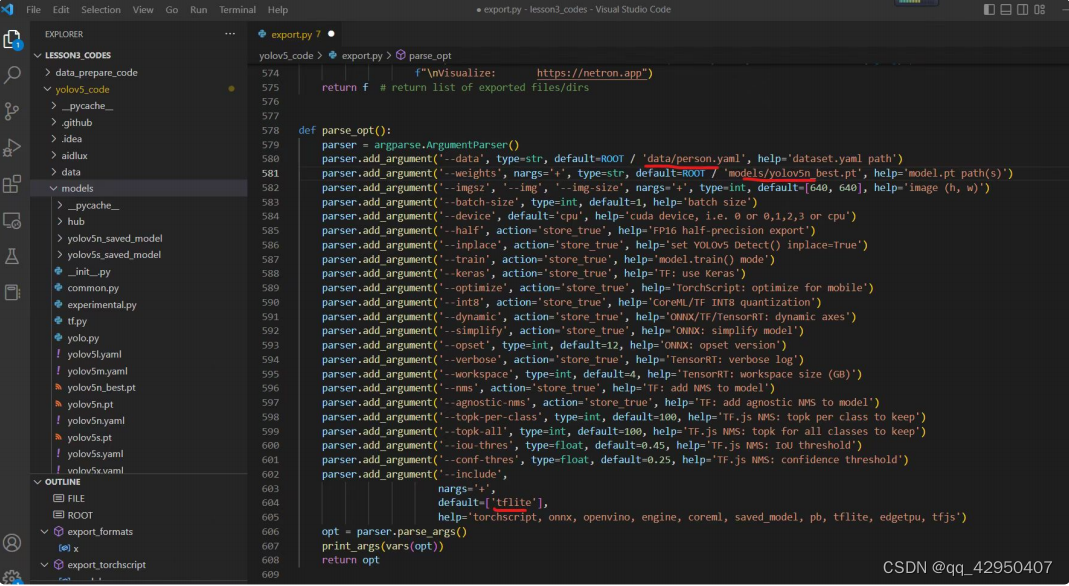
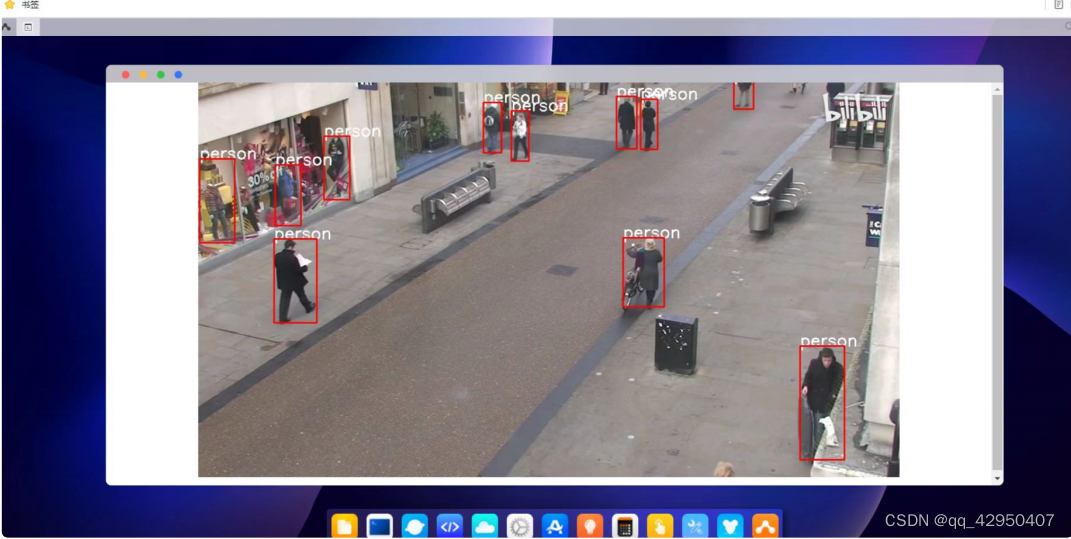
7. MOT16数据集
MOT Challenge - Data,可以登录MOT16数据集下载视频数据。
8.人体轨迹追踪
目标追踪算法包括单目标追踪和多目标追踪,多目标追踪主要针对的是多个目标的运动轨迹,而单目标追踪主要 针对的某⼀个目标的运动轨迹。目前用的较多的是多目标追踪算法,多目标追踪算法包括(1)sort多目标算法(2)deepsort多目标算法(3)Bytetrack多目标追踪算法。该实例中我们使用Bytetrack多目标追踪算法,会尽量的减少人物之间的遮挡而带来的目标的丢失。
# 实现目标追踪相关功能函数,tracker函数接口可以在公众号Aidlux里回复lesson4获取
det = [] #给予检测一个空间
# Process predictions
for box in pred[0]: # per image
box[2] += box[0]
box[3] += box[1]
det.append(box) det.append()表示将这个数组写入det中
if len(det):
# Rescale boxes from img_size to im0 size
online_targets = tracker.update(det, [frame.shape[0], frame.shape[1]])
online_tlwhs = []
online_ids = []
online_scores = []
# 取出每个目标的追踪信息
for t in online_targets:
# 目标的检测框信息
tlwh = t.tlwh
# 目标的track_id信息,赋予目标框一个ID
tid = t.track_id
online_tlwhs.append(tlwh)
online_ids.append(tid)
online_scores.append(t.score)
# 针对目标绘制追踪相关信息
res_img = plot_tracking(res_img, online_tlwhs, online_ids, 0,0)
cvs.imshow(res_img)9.人流量统计

### 越界单边识别功能实现 ###
# 1.绘制越界监测区域
#下面的坐标代表直线的两端的坐标
line = [[167,541],[1191,539]]
cv2.line(res_img,(167,541),(1191,539),(255,255,0),3)
# 2.计算得到人体下方中心点的位置(人体检测监测点调整),
# (x,y,w,h)->(tlwh[0],tlwh[1],tlwh[2],tlwh[3])
pt = [tlwh[0]+1/2*tlwh[2],tlwh[1]] #越界识别点
# 3. 人体和违规区域的判断(人体状态追踪判断)
track_info = is_passing_line(pt, lines)
if tid not in track_id_status.keys():
track_id_status.update( {tid:[track_info]})
else:
if track_info != track_id_status[tid][-1]:
track_id_status[tid].append(track_info)
# 4. 判断是否有track_id越界,有的话保存成图片
# 当某个track_id的状态,上一帧是-1,但是这一帧是1时,说明越界了
if track_id_status[tid][-1] == 1 and len(track_id_status[tid]) >1:
# 判断上一个状态是否是-1,是否的话说明越界,为了防止继续判别,随机的赋了一个3的值
if track_id_status[tid][-2] == -1:
track_id_status[tid].append(3)
count_person +=1 #前面记得count_person初始化
###再判断当前一个状态为1,后一个状态为-1时的情况
if track_id_status[tid][-1] == -1 and len(track_id_status[tid]) >1:
# 判断上一个状态是否是1,是否的话说明越界,为了防止继续判别,随机的赋了一个3的值
if track_id_status[tid][-2] == 1:
track_id_status[tid].append(3)
count_person += 1
#获取进出人流量数据的统计10.额外功能
import requests
import time
# 填写对应的喵码
id = 'tP48aPC'
# 填写喵提醒中,发送的消息,这里放上前面提到的图片外链
text = "有人越界识别!!"
ts = str(time.time()) # 时间戳
type = 'json' # 返回内容格式
request_url = "http://miaotixing.com/trigger?"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47'}
result = requests.post(request_url + "id=" + id + "&text=" + text + "&ts=" + ts + "&type=" + type,
headers=headers)# aidlux相关
#下面的utils函数包和track函数包要到公众号“AidLUx”上回复lesson5
from cvs import *
import aidlite_gpu
from utils import detect_postprocess, preprocess_img, draw_detect_res, scale_coords,process_points,is_in_poly,is_passing_line
import cv2
# bytetrack
from track.tracker.byte_tracker import BYTETracker
from track.utils.visualize import plot_tracking
import requests #库的引用
import time
# 加载模型
model_path = '/home/lesson4_codes/aidlux/best-fp16.tflite'
in_shape = [1 * 640 * 640 * 3 * 4]
out_shape = [1 * 25200 * 6 * 4]
# 载入模型
aidlite = aidlite_gpu.aidlite()
# 载入yolov5检测模型
aidlite.ANNModel(model_path, in_shape, out_shape, 4, 0)
#初始化文件
tracker = BYTETracker(frame_rate=30)
track_id_status = {}
cap = cvs.VideoCapture("/home/lesson4_codes/aidlux/jiankong.mp4")
frame_id = 0
count_person = 0
while True:
frame = cap.read()
if frame is None:
print("Camera is over!")
# 填写对应的喵码
id = 'ti184WH'
# 填写喵提醒中,发送的消息,这里放上前面提到的图片外链
text = "医院进出口人流统计:"+str(count_person)
ts = str(time.time()) # 时间戳
type = 'json' # 返回内容格式
request_url = "http://miaotixing.com/trigger?"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47'}
result = requests.post(request_url + "id=" + id + "&text=" + text + "&ts=" + ts + "&type=" + type,headers=headers)
break
frame_id += 1
if frame_id % 3 != 0:
continue
# 预处理
img = preprocess_img(frame, target_shape=(640, 640), div_num=255, means=None, stds=None)
# 数据转换:因为setTensor_Fp32()需要的是float32类型的数据,所以送入的input的数据需为float32,大多数的开发者都会忘记将图像的数据类型转换为float32
aidlite.setInput_Float32(img, 640, 640)
# 模型推理API
aidlite.invoke()
# 读取返回的结果
pred = aidlite.getOutput_Float32(0)
# 数据维度转换
pred = pred.reshape(1, 25200, 6)[0]
# 模型推理后处理
pred = detect_postprocess(pred, frame.shape, [640, 640, 3], conf_thres=0.4, iou_thres=0.45)
# 绘制推理结果
res_img = draw_detect_res(frame, pred)
# 目标追踪相关功能
det = []
# Process predictions
for box in pred[0]: # per image
box[2] += box[0]
box[3] += box[1]
det.append(box)
if len(det):
# Rescale boxes from img_size to im0 size
online_targets = tracker.update(det, [frame.shape[0], frame.shape[1]])
online_tlwhs = []
online_ids = []
online_scores = []
# 取出每个目标的追踪信息
for t in online_targets:
# 目标的检测框信息
tlwh = t.tlwh
# 目标的track_id信息
tid = t.track_id
online_tlwhs.append(tlwh)
online_ids.append(tid)
online_scores.append(t.score)
# 针对目标绘制追踪相关信息
res_img = plot_tracking(res_img, online_tlwhs, online_ids, 0,0)
#1.绘制统计人流线
lines =[[167,541],[1191,539]]
cv2.line(res_img,(167,541),(1191,539),(255,255,0),3)
# 2.计算得到人体下方中心点的位置(人体检测监测点调整)
pt = [tlwh[0]+1/2*tlwh[2],tlwh[1]]#以人头为识别点
#3人体和违规线的判断(状态追踪)
track_info = is_passing_line(pt, lines)
if tid not in track_id_status.keys():
track_id_status.update( {tid:[track_info]})
else:
if track_info != track_id_status[tid][-1]:
track_id_status[tid].append(track_info)
# 4.判断是否有track_id越界,有的话保存成图片
# 当某个track_id的状态,上一帧是-1,但是这一帧是1时,说明越界了
if track_id_status[tid][-1] == 1 and len(track_id_status[tid]) >1:
# 判断上一个状态是否是-1,是否的话说明越界,为了防止继续判别,随机的赋了一个3的值
if track_id_status[tid][-2] == -1:
track_id_status[tid].append(3)
#cv2.imwrite("overstep.jpg",res_img)
count_person += 1 #之前已经定义count_person=0,不然会报未定义的错
#5.再判断当前一个状态为1,后一个状态为-1时的情况
if track_id_status[tid][-1] == -1 and len(track_id_status[tid]) >1:
# 判断上一个状态是否是1,是否的话说明越界,为了防止继续判别,随机的赋了一个3的值
if track_id_status[tid][-2] == 1:
track_id_status[tid].append(3)
#cv2.imwrite("overstep.jpg",res_img)
count_person += 1
cv2.putText(res_img,"Pereson_count in the gate of Hospital:"+ str(count_person), (50,50), cv2.FONT_HERSHEY_SIMPLEX, 1 ,(255, 0, 255), 3)
cvs.imshow(res_img)
五、总结与学习心得
笔者是在江大白以及Aidlux团队的训练营中学习而来,期间大白老师区别以往的视频课,采用图文描述的方式以一种更加直观的方式展现出整个项目的流程与细节。不管是AI算法小白还是AI算法的老手都在这次训练营受益匪浅。Aidlux工程实践内容全是干货,同时过程也遇见了很多问题,但是大白老师和训练营的其他同学们都很认真为其他学员解决,耐心辅导,对我来言,刚刚接触这一领域,以及Aidlux平台的使用,让我耳目一新。整个流程下,我已经学会了如何在Aidlux进行模型部署,令我也感觉到成就感,在此特别感谢江大白老师和Aidlux团队的贡献,希望他们以后在AI算法开发的道路事业更加顺利。最后放上本次街道人流量统计的效果视频的地址。
https://live.csdn.net/v/248893
















 128
128











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









