







3. 序列属性衍生的特征
3.1 连续变量衍生
一个序列可能会伴有多个连续变量的特征,比如说对于股票数据,除了收盘价,可能还会有成交量、开盘价等伴随的特征,对于销量数据,可能还会伴随有价格的特征。对于这种连续变量,可以直接作为一个特征,也可以像之前时序值衍生的特征那样做处理,或者也可以与先前的数据做差值,比如t时刻的价格减去t-1时刻的价格。但是一般这种连续变量使用不多,因为这些值在未来也很可能是不可知的,那怎么能当成造特征呢?
3.2 类别变量Encoding
对于类别型变量,如果类别比较少,一般在机器学习里做的处理是one-hot encoding,但是如果类别一多,那么生成的特征是会很多的,容易造成维度灾难,但是也不能随便用label encoding,因为很多时候类别是不反应顺序的,如果给他编码成1、2、3、4、5,对于一些树模型来说,在分裂节点的时候可不管这些是类别型还是连续型,通通当作连续型来处理,这是有先后顺序的,肯定不能这么做。所以就有这么一种方式,就是和y做特征交互,比如预测销量,有一个特征是产品类别,那么就可以统计下这个产品类别下的销量均值、标准差等,这种其实也算是上面扩展窗口统计的一种。
3.2.0 变量类型
A. 二元特征:二元特征通常表示两种互斥的状态或选择。这意味着一个对象只能同时具有其中的一种状态。在二元特征中,每个类别代表了一个明确的情况或选择。例如:
- 是/否:表示是否发生了某个事件或条件是否成立。
- 真/假:表示某个断言的真实性或有效性。
在二元特征中,每个类别之间通常存在明确的对立关系,而且两个类别通常具有相似的重要性。
B. 有序特征:有序特征表示具有一定顺序或级别关系的类别。这意味着在这种特征中,每个类别都有一个明确的顺序,其中某些类别被认为是更高或更重要的。例如:
- 低/中/高:表示某种级别或程度的大小顺序。
- 冷/热/岩浆热:表示温度的不同级别,其中某些级别被认为比其他级别更高。
在有序特征中,类别之间的顺序关系对于数据的解释和分析至关重要。通常,这种特征表示的是一种连续性的变化或级别。
C. 名义特征:名义特征代表的是一组没有任何内在顺序或级别关系的类别。这意味着在名义特征中,每个类别都是彼此独立的,没有明确的顺序。例如:
- 猫/狗/老虎:表示不同类型的动物,它们之间没有明确的顺序关系。
- 披萨/汉堡/可乐:表示不同种类的食物或饮料,它们之间没有大小或重要性的顺序。
在名义特征中,每个类别都被视为是独立的,没有顺序关系。因此,在分析和建模时,名义特征的类别通常被视为是相互独立的。
3.2.1 Label Encoding(标签编码)
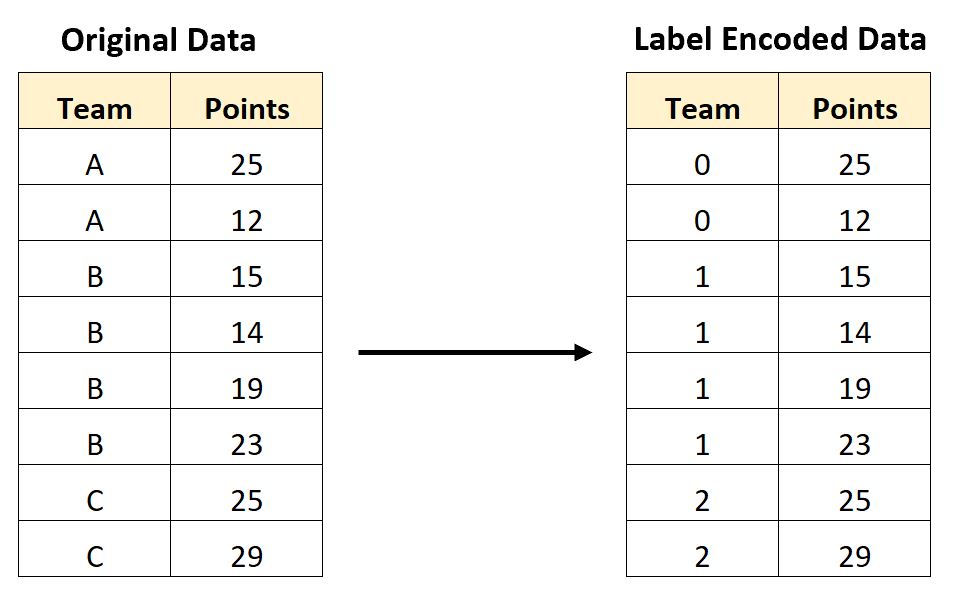
标签编码是一种将类别型特征转换为整数标签的编码方法。标签编码的过程很简单,就是将每个类别按照它们在数据中出现的顺序赋予一个整数编码。例如,如果一个特征包含了三个类别:'A'、'B'、'C',则可以用0、1、2分别代表它们。这样,原始的类别型特征就被转换为了整数编码。
优点包括:
- 简单快捷: 标签编码的实现非常简单,可以直接使用许多机器学习库提供的函数来完成。
- 保留类别信息: 虽然将类别转换为整数编码,但是整数之间的顺序没有实际意义,因此它仍然保留了原始特征中的类别信息。
然而,标签编码也存在一些缺点:
- 可能误导模型: 对于一些机器学习算法,如决策树和随机森林,它们可能会错误地将整数编码解释为 有序 的特征,从而影响模型的性能。
因此,在使用标签编码时需要注意一些问题:
如果类别之间不存在顺序关系,应该谨慎使用标签编码,或者在使用之前仔细检查数据是否具有顺序性。
3.2.2 One-Hot Encoding(独热编码)
用于将类别型特征转换为二进制编码。在独热编码中,每个类别都由一个长度等于类别总数的向量表示,其中只有一个元素为1(表示类别存在),其他元素为0。
优点:
- 保留了类别之间的无序性:独热编码将每个类别表示为一个独立的向量,这样可以确保不同类别之间没有顺序关系,适用于无序类别的特征。
- 避免了类别之间的顺序关系:由于每个类别都用独立的向量表示,因此独热编码不会引入类别之间的顺序关系,避免了模型对类别之间的顺序进行错误的假设。
缺点:
- 维度灾难:如果类别数量较多,独热编码会导致特征空间的维度急剧增加,从而增加了模型的复杂度和训练时间。这在处理大规模数据时可能会成为一个问题。
- 冗余性:独热编码会生成多个特征,其中大多数特征都是稀疏的(大部分值为0),这可能会导致数据集中存在大量冗余信息,增加了计算和存储的成本。
- 不适用于高基数特征:对于具有高基数(大量不同取值)的特征,独热编码会生成过多的特征,导致维度爆炸和稀疏性问题。这种情况下,通常需要使用其他编码方法或特征选择技术来处理。
3.2.2 Target Encoding(目标编码)
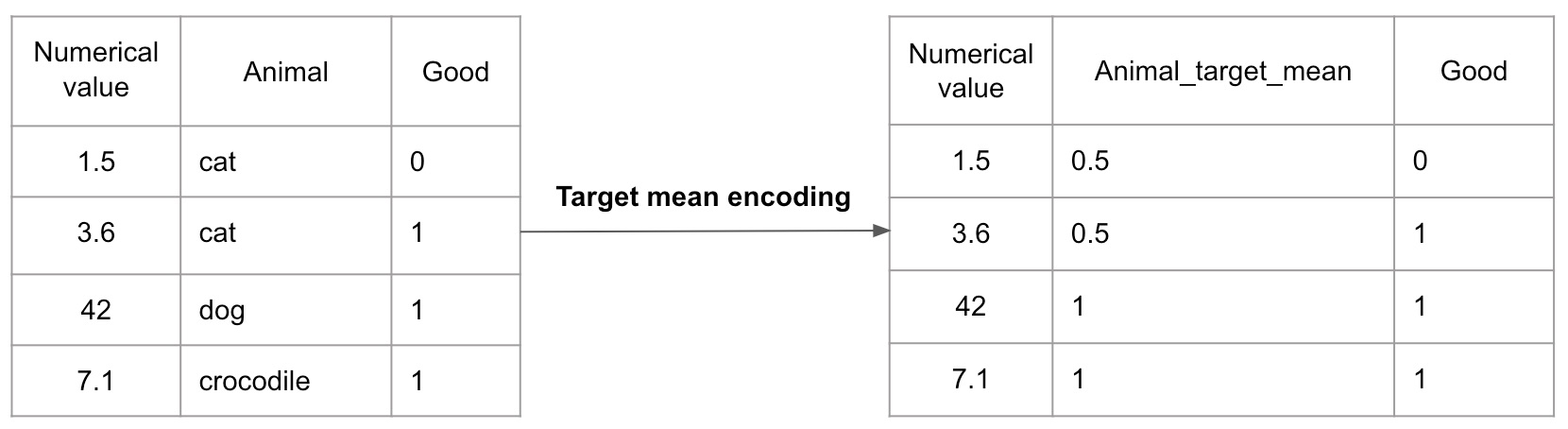
也称为Mean Encoding或Probability Encoding,是一种用于处理分类特征的编码方法。它将每个类别映射到目标变量(通常是二元分类问题中的目标类别的概率或均值),从而将分类特征转换为数值特征。
目标编码的基本思想是利用目标变量在不同类别下的分布情况来编码分类特征,以反映不同类别对目标变量的影响程度。
3.2.3 其他
- BackwardDifferenceEncoder : 使用类别值的差异来编码特征。每个编码的特征表示为该类别与其后续类别的差异。这种编码通常用于处理有序分类变量。
- BaseNEncoder : 将类别值转换为基数N的数字。例如,对于类别A、B、C,可能会转换为0、1、2(如果N=3),或者转换为10、11、12(如果N=13)等。
- BinaryEncoder : 将类别值转换为二进制编码。每个类别值被表示为一串二进制数字。
- CatBoostEncoder : CatBoost是一种梯度提升算法,该编码器使用CatBoost模型来对类别特征进行编码。
- CountEncoder : 将每个类别值替换为其在整个数据集中出现的次数。
- GLMMEncoder : 使用广义线性混合模型(Generalized Linear Mixed Model)来编码类别特征。
- GrayEncoder : 使用格雷编码(Gray Code)来对类别特征进行编码。格雷编码是一种二进制编码,相邻的两个数之间只有一个比特位不同。
- HashingEncoder : 将类别值哈希成固定数量的特征列。这种编码通常用于处理高基数的类别特征。
- HelmertEncoder : 使用Helmert转换来编码类别特征。Helmert转换是一种多重比较方法,用于比较每个类别与其后续类别的差异。
- JamesSteinEncoder : 使用James-Stein估计来编码类别特征。
- LeaveOneOutEncoder : 将每个类别值替换为在该类别上目标变量的平均值,但排除了当前样本。
- MEstimateEncoder : 使用M估计来编码类别特征。
- OneHotEncoder : 将类别特征转换为独热编码形式,即每个类别值被表示为一个只有一个元素为1,其他元素为0的向量。
- OrdinalEncoder : 将类别特征转换为顺序编码,即将类别值映射到整数值。
- PolynomialEncoder : 使用多项式基函数来编码类别特征。
- QuantileEncoder : 将类别值替换为其在整个数据集中的分位数。
- RankHotEncoder : 将类别值转换为其在整个数据集中的排名。
- SumEncoder : 使用和编码来编码类别特征,即每个类别值与其他类别值的和。
- TargetEncoder : 将每个类别值替换为目标变量在该类别上的平均值。
- WOEEncoder : 使用权重的编码来编码类别特征,其中权重是目标变量的对数几率比。
















 997
997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











